







最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
6.模型诊断
- 1.残差分析:使用命令predict和rvfplot进行残差的预测和可视化。
predict resid, residuals
rvfplot resid
- 2.多重共线性检验:使用命令collin或vif进行多重共线性检验。
collin var1-var5
vif var6-var10
- 3.异方差性检验:使用命令hettest或robust进行异方差性检验。
hettest var11
regress var12 var13 var14, robust
7.结果解释和报告
- 1.表格输出:使用命令tabout、esttab、outreg2等进行表格输出。
tabout var1 var2, c(mean sd) replace
esttab model1 model2, b(a3) se(3) star(.05 .01 .001) title("回归结果")
outreg2 using "regression\_results.doc", replace
- 2.图表输出:使用命令graph export、twoway、marginsplot等进行图表输出。
graph export "figure1.png", replace
twoway scatter var3 var4 || lfit var3 var4
marginsplot, at(var5=(0 1)) by(var6)
- 3.文字说明:使用命令notes、putdocx、markdown等进行文字说明。
notes "根据回归结果,可以看出..."
putdocx "在此处插入文字说明" para
markdown "## 结果解释"
所遇到的问题“租个鸡婆”
1.如何导入excel的数据
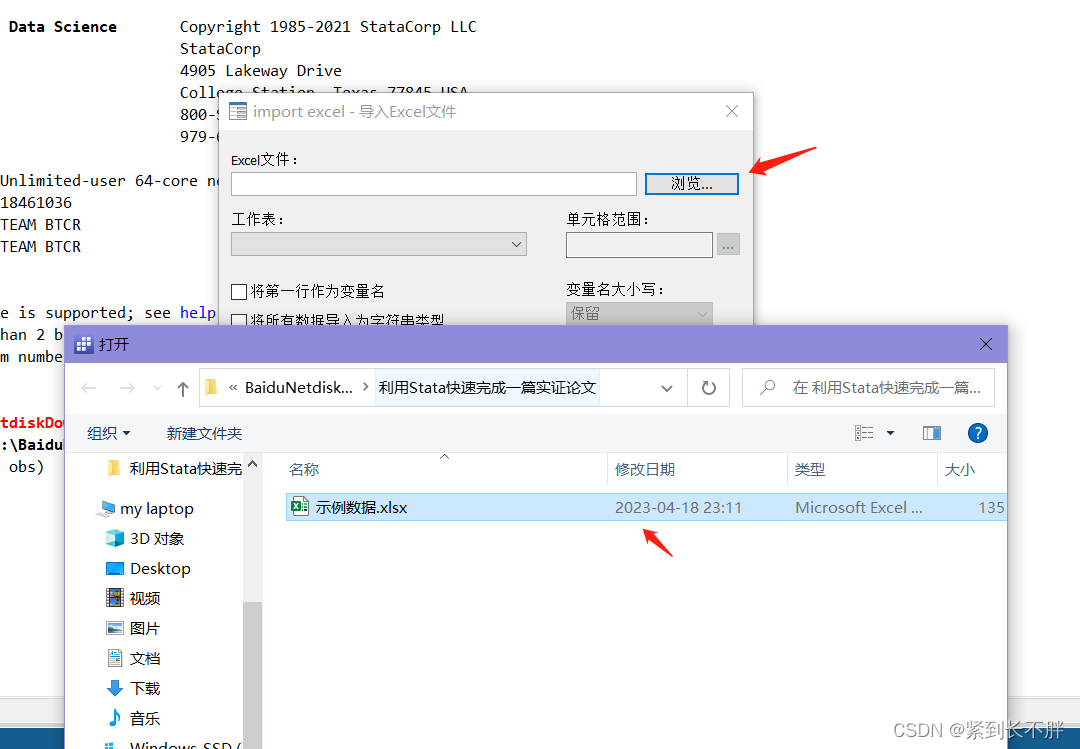
如果数据导入后,出现红色,那么用destring 红色的变量,replace,将数据变为数值型。
2.报错记录
2.1 迎来的第一个报错
not possible with numeric variable
这表明你的变量已经是数值型了,不用在定义。
2.2 第二个报错
command logout is unrecognized
- 1.因为你logout命令没有下载,你可以在stata命令行输入
ssc install logout - 2.这时候会弹出
Java installation not found - 3.然后看这里,安装java【传送门】
注意,这里的ssc install XXX就相当于python里面的pip install XX哈哈哈
2.3 第三个报错
command pwcorr_a is unrecognized
我是看的这篇文章解决的
【传送门】
2.4 第四个报错
command esttab is unrecognized
执行:ssc install estout, replace
3.up🐖的代码解析
3.1 数据处理
/\*数据整理\*/
rename 综合税率A x2
rename 净资产收益率ROE y
rename 资产负债率 x1
rename 总资产周转率A x3
rename 资产对数 x4
rename 前十大股东持股比例 x5
3.2 面板数据的时间、个体设置
\*xtset 股票代码 截止日期
encode 股票代码 ,gen(id)
encode 截止日期 ,gen(time)
xtset id time
xtset id time 这是 Stata 中的一个命令,用于设置面板数据的索引变量。其中,id 是个体标识变量,time 是时间标识变量。这个命令告诉 Stata,数据集是一个面板数据集,并且 id 和 time 是面板数据的索引变量,它们将被用来区分不同个体和不同时间点的观测值。这个命令在进行面板数据分析之前必须先执行,否则 Stata 不会正确地识别面板数据的结构。
3.3 变量的描述性统计
/\*描述性统计\*/
logout,save(基本统计描述)word replace:tabstat y x1 x2 x3 x4 x5,s(N mean p50 sd min max) f(%12.3f) c(s)
这里,f(%12.3f)保留小数点个数 ,c(s)是输出表格的形式,不变即可
3.4 相关性分析
/\*相关性分析\*/
logout,save(相关分析)word replace:pwcorr_a y x1 x2 x3 x4 x5
如果报错,解决方案看上面。
3.5 共线性诊断
/\*共线性诊断\*/
reg y x1 x2 x3 x4 x5,r
vif
logout,save(共线性诊断)word replace:vif
order y x1 x2 x3 x4 x5
注意,VIF<10即可进行下一步分析。
其次,r代表可选参数,order y x1 x2 x3 x4 x5是用于对数据进行排序。其中,y 是排序的关键字,后面的 x1,x2,x3,x4 和 x5 是需要排序的变量。该命令可以帮助用户快速对数据进行排序,以便更好地进行数据分析和处理。
那么作为面板数据,以上三步都通过的话,我们就需要判断选择固定效应或者随机效应
严格的模型检验而言,首先是从混合的模型开始检验
3.6 模型选择检验
/\*模型选择检验\*/
reg y x1 x2 x3 x4 x5
est store ols
xtreg y x1 x2 x3 x4 x5,fe
// 检验个体效应 ,表明固定效应优于混合ols模型 ,p<0.05表示个体效应显著,固定效应更好
reg y x1 x2 x3 x4 x5: 这是进行普通最小二乘回归分析的命令,其中 y 是因变量,x1,x2,x3,x4 和 x5 是自变量。
est store ols: 这是将回归结果保存在一个名为 ols 的存储器中,以便之后进行比较或使用。
xtreg y x1 x2 x3 x4 x5,fe: 这是进行固定效应模型(fixed effects model)的命令,其中 y 是因变量,x1,x2,x3,x4 和 x5 是自变量。fe表示使用固定效应模型进行分析,这种模型可以控制个体固定效应的影响。此外,xtreg 命令还可以用于面板数据分析,这时需要指定面板数据的特定变量。
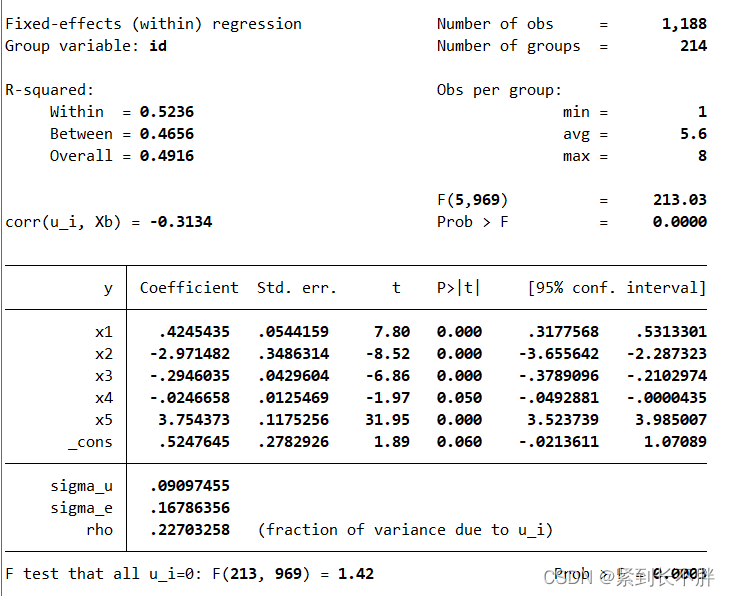
挡住的p=0.0003是显著的,检验个体效应 ,表明固定效应优于混合ols模型 ,p<0.05表示个体效应显著,固定效应更好。
qui xtreg y x1 x2 x3 x4 x5,re
xttest0
//检验时间效应,结果随机效应也优于混合ols模型,p<0.05表示随机效应显著

qui xtreg y x1 x2 x3 x4 x5,re: 这是进行随机效应模型(random effects model)的命令,其中 y 是因变量,x1,x2,x3,x4 和 x5 是自变量,re 表示使用随机效应模型进行分析。
xttest0: 这是对面板数据的时间效应进行假设检验的命令,用于确定是否需要使用固定效应模型。如果检验结果 p 值小于显著性水平(通常为 0.05),则说明时间效应对因变量的影响是显著的,需要使用固定效应模型;否则,可以使用随机效应模型。
在这段代码中,检验结果显示随机效应模型优于混合 OLS 模型,并且时间效应对因变量的影响是显著的(p<0.05),因此使用随机效应模型进行分析是合理的。
qui是 Stata 中的一个命令,表示"quietly",即“安静地”执行命令。使用 qui 命令可以在执行命令时抑制 Stata 输出结果,避免在执行大量命令时过多干扰用户。
3.6.1 hausman检验
xtreg y x1 x2 x3 x4 x5,re
est store re
xtreg y x1 x2 x3 x4 x5,fe
est store fe
hausman fe re //豪斯曼检验,结果拒绝原假设,选用固定效应模型 p<0.05固定效应,大于0.05 随机效应
outreg2 using "豪斯曼检验", word ctitle(FE) adds(Hausman, `r(chi2)',p-value,`r(p)')replace //输出hausman结果
如果检验结果的 p 值小于显著性水平(通常为 0.05),则说明固定效应模型和随机效应模型之间存在显著差异,应该使用固定效应模型。反之,如果 p 值大于显著性水平,则说明两种模型的结果没有显著差异,可以使用随机效应模型。在这段代码中,检验结果拒绝了原假设,即固定效应模型和随机效应模型之间存在显著差异,应该使用固定效应模型,因为 p 值小于 0.05。
简言之:显著选固定,不显著选随机
模型选择到这里就告一段落,基本的分析也就结束。
3.6.2 初步模型整合
/\*检验结果,应该选择固定效应回归分析\*/
reg y x1 x2 x3 x4 x5
est store ols
xtreg y x1 x2 x3 x4 x5,fe
est store fe
xtreg y x1 x2 x3 x4 x5,re
est store re
esttab ols fe re using 实证结果.rtf, replace b(%12.3f) se(%12.3f) nogap compress s(N r2 r2_a)star(\* 0.1 \*\* 0.05 \*\*\* 0.01) //加入了调整R2,r2_
esttab ols fe re using :实证结果.rtf, replace:这是将存储在 ols、fe 和 re 存储器中的回归结果输出到一个名为 实证结果.rtf 的 RTF 文件中的命令。replace 表示如果文件已经存在,则替换原有文件。
b(%12.3f) se(%12.3f):这是将回归系数和标准误的输出格式设置为小数点后三位的浮点数。【格式固定不动】
nogap:这是设置 esttab 命令的输出格式,使之间隔更为紧凑。
compress:这是使用压缩格式来输出 RTF 文件,减小文件大小。
s(N r2 r2_a)star(* 0.1 ** 0.05 *** 0.01):这是在输出结果中添加一些统计信息,如样本大小、拟合优度和调整 R^2。星号表示统计量的显著性水平,例如 * 表示显著性水平为 0.1,** 表示显著性水平为 0.05,*** 表示显著性水平为 0.01。【格式固定不动即可】
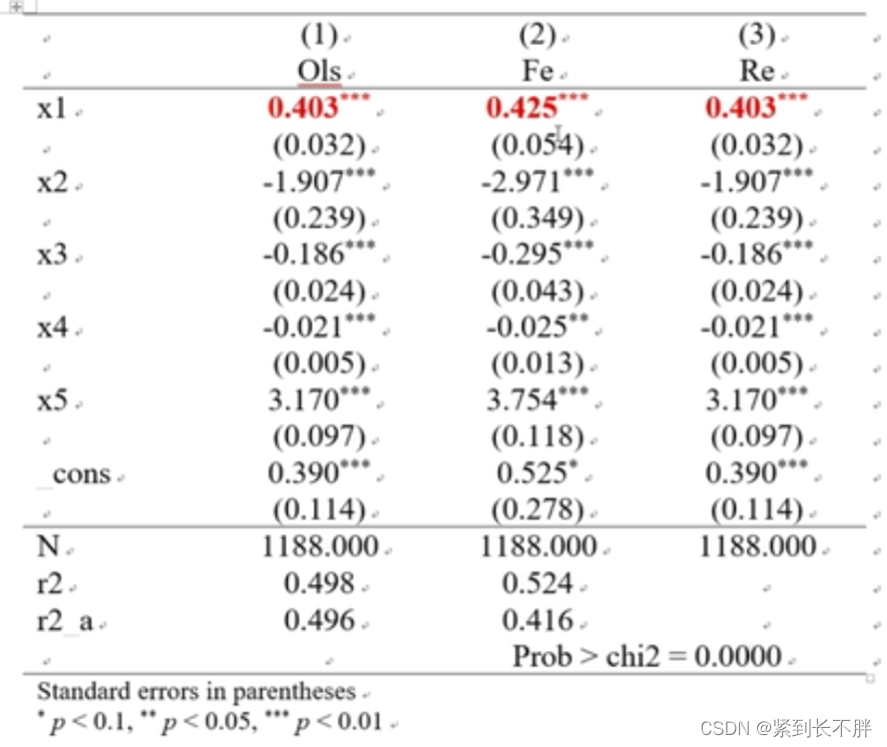
注意:
- 1.标红1处,关键变量x1在三个模型都显著,说明我们的模型对x1来说是 稳健的。
- 2.增加了
Prob>chi2=0.0000这是固定效应,hausman检验的结果。需要在论文中说明。
4.滞后检验
没弄出来!
5.分组回归
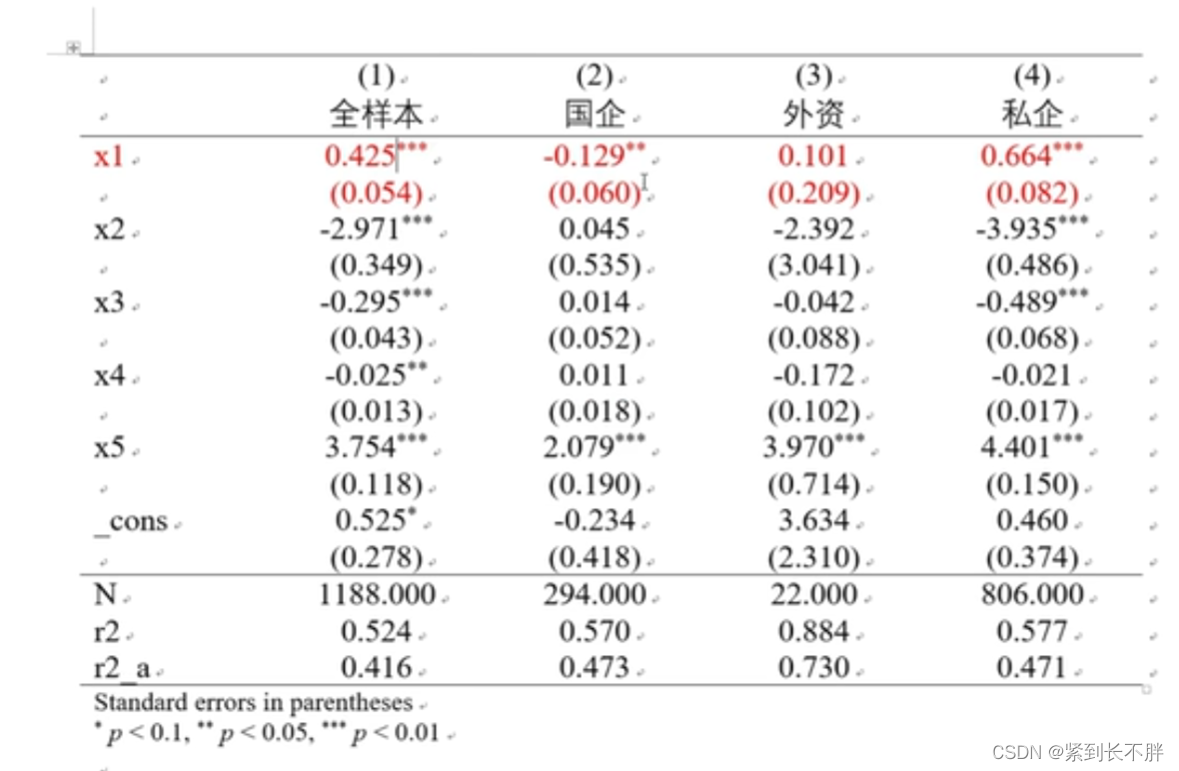
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*分组回归\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
order y x1 x2 x3 x4 x5 分组1
\*encode 股权性质,gen(分组)
order y x1 x2 x3 x4 x5 // 国企 = 2 外资 = 3 私企 = 4
xtreg y x1 x2 x3 x4 x5 if 分组1 == 2 ,fe
est store fe3
xtreg y x1 x2 x3 x4 x5 if 分组1 == 3 ,fe
est store fe4
xtreg y x1 x2 x3 x4 x5 if 分组1 == 4 ,fe
est store fe5
esttab fe fe3 fe4 fe5 using 分组回归.rtf, replace b(%12.3f) se(%12.3f) nogap compress s(N r2 r2_a)star(\* 0.1 \*\* 0.05 \*\*\* 0.01) //加入了调整R2,r2_a
注意分组回归的分组变量,需要encode 股权性质,gen(分组)重新编码!不然会type mismatch
结果整理:
6.调节效应
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*调节效应\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
\*gen TJ = x4\*x5
xtreg y x1 x2 x3 x4 x5 TJ ,fe
est store fe6
esttab fe fe6 using 调节效应.rtf, replace b(%12.3f) se(%12.3f) nogap compress s(N r2 r2_a)star(\* 0.1 \*\* 0.05 \*\*\* 0.01) //加入了调整R2,r2_a
需要用gen来产生调节变量
7.中介效应
/\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*中介效应\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*/
\* rename 托宾Q值TQ ZJ
xtreg y x1 x2 x3 x4 x5 ,fe
est store fe7
xtreg ZJ x1 x2 x3 x4 x5 ,fe
est store fe8
xtreg y x1 ZJ x2 x3 x4 x5 ,fe
est store fe9
esttab fe7 fe8 fe9 using 中介效应.rtf, replace b(%12.3f) se(%12.3f) nogap compress s(N r2 r2_a)star(\* 0.1 \*\* 0.05 \*\*\* 0.01) //加入了调整R2
中介效应,这里用的是三步检验法。先看x与y的一般检验是否通过,再看x与中介变量m检验,最后看x、m与y的检验
结果整理如下:
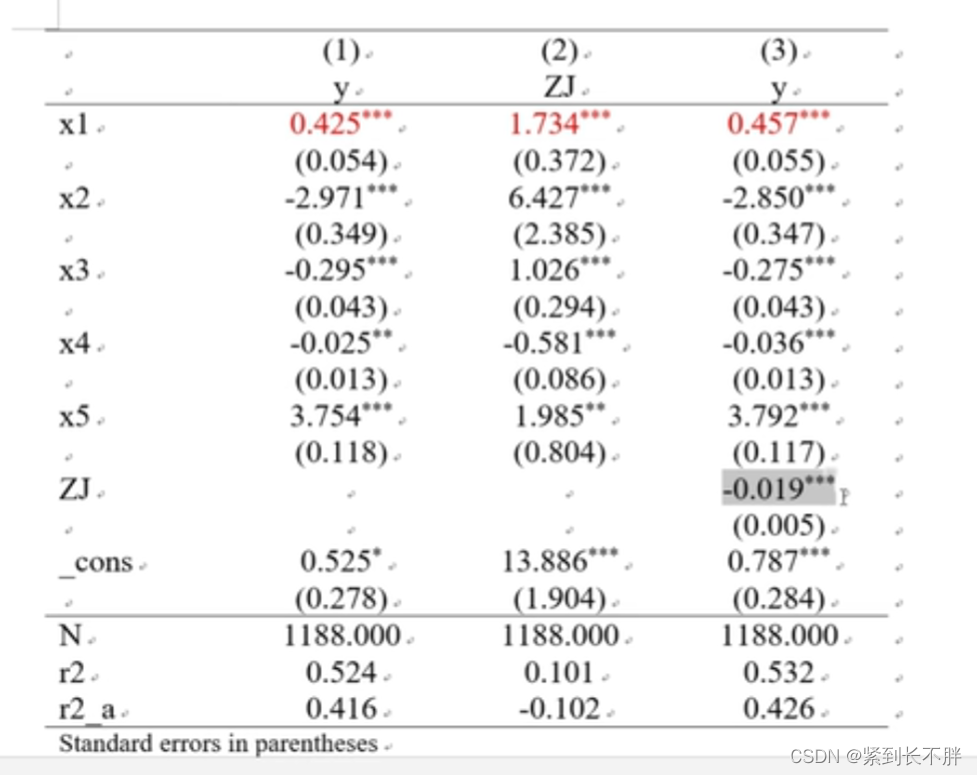
则存在中介效应,如果模型3的x1系数不显著,那么,这存在完全中介效应。
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









