







视频录制的大致实现流程是先由 Camera 、 AudioRecord 进行最原始的相机画面以及声音的采集,然后将采集的数据进行滤镜、降噪等前处理,处理完成后由 MediaCodec 进行硬件编码,最后采用 MediaMuxer 生成最终的 MP4 文件。
二.短视频处理播放
视频的处理和播放主要是视频的清晰度、观看流畅度方面的体验。在这方面来讲,可以采用“窄带高清”技术,在节省码率的同时能够提供更加清晰的观看体验,经过测试,同等视频质量下最高可以节省20-40%带宽。除了带宽之外,短视频内容的存储和CDN优化也尤为重要,通常我们需要上传到云存储服务器的内容是短视频内容和封面内容。
而CDN优化带给短视频平台的则是进一步的短视频首次载入和循环播放方面的体验。比如针对首播慢的问题,像阿里云播放器支持QUIC协议,基于CDN的调度,可以使短视频首次播放秒开的成功率达到98%,此外在循环播放时还可以边播放边缓存,用户反复观看某一短视频时就不用耗费流量了。
三.录制视频的方式
在Android系统当中,如果需要一台Android设备来获取到一个MP4这样的视频文件的话,主流的方式一共与三种:MediaRecorder、MediaCodec+MediaMuxer、FFmpeg。
**MediaRecorder:**是Android系统直接提供给我们的录制类,用于录制音频和视频的一个类,简单方便,不需要理会中间录制过程,结束录制后可以直接得到音频文件进行播放,录制的音频文件是经过压缩的,需要设置编码器,录制的音频文件可以用系统自带的播放器播放。
优点:大部分以及集成,直接调用相关接口即可,代码量小,简单稳定;
缺点:无法实时处理音频;输出的音频格式不是很多。
MediaCodec+MediaMuxer: MediaCodec 与 MediaMuxer结合使用同样能够实现录制的功能。MediaCodec是Android提供的编解码类,MediaMuxer则是复用类(生成视频文件)。从易用性的角度上来说肯定不如MediaRecorder,但是允许我们进行更加灵活的操作,比如需要给录制的视频添加水印等各种效果。
优点: 与MediaRecorder一样低功耗速度快,并且更加灵活
缺点: 支持的格式有限,兼容性问题
FFmpeg: FFmpeg(Fast forword mpeg,音视频转换器)是一个开源免费跨平台的视频和音频流方案,它提供了录制/音视频编解码、转换以及流化音视频的完整解决方案。主要的作用在于对多媒体数据进行解协议、解封装、解码以及转码等操作
优点:格式支持非常的强,十分的灵活,功能强大,兼容性好;
缺点:C语言些的音视频编解码程序,使用起来不是很方便。
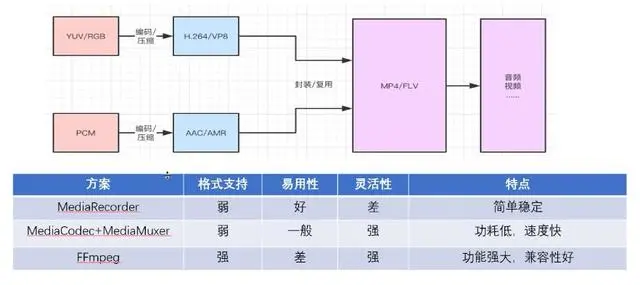
虽然从数据看来FFmpeg是最好的,但是我们得首先排除这种,因为他的易用性是最差的;其次,MediaRecorder也是需要排除的,所以在这里我比较推荐MediaCodec+MediaMuxer这种方式。
四.编码器参数
码率:数据传输时单位时间传送的数据位数,kbps:千位每秒。码率和质量成正比,也和文件体积成正比。码率超过一定数值,对图像的质量没有多大的影响。
帧数:每秒显示多少个画面,fps
关键帧间隔:在H.264编码中,编码后输出的压缩图像数据有多种,可以简单的分为关键帧和非关键帧。关键帧能够进行独立解码,看成是一个图像经过压缩的产物。而非关键帧包含了与其他帧的“差异”信息,也可以称呼为“参考帧”,它的解码需要参考关键帧才能够解码出一个图像。非关键帧拥有更高的压缩率。
五、MediaCodec+MediaMuxer的使用
MediaMuxer和MediaCodec这两个类,它们的参考文http://developer.android.com/reference/android/media/MediaMuxer.html和http://developer.android.com/reference/android/media/MediaCodec.html,里边有使用的框架。这个组合可以实现很多功能,比如音视频文件的编辑(结合MediaExtractor),用OpenGL绘制Surface并生成mp4文件,屏幕录像以及类似Camera app里的录像功能(虽然这个用MediaRecorder更合适)等。
它们一个是生成视频,一个生成音频,这里把它们结合一下,同时生成音频和视频。基本框架和流程如下:
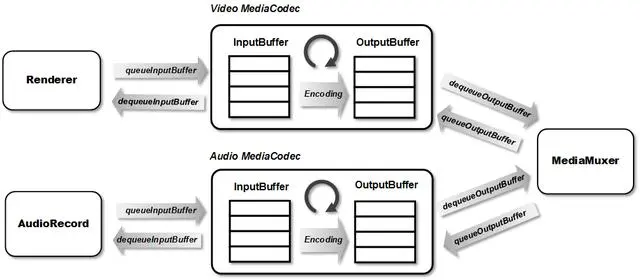
首先是录音线程,主要参考HWEncoderExperiments。通过AudioRecord类接收来自麦克风的采样数据,然后丢给Encoder准备编码:
AudioRecord audio_recorder;
audio_recorder = new AudioRecord(MediaRecorder.AudioSource.MIC,
SAMPLE_RATE, CHANNEL_CONFIG, AUDIO_FORMAT, buffer_size);
// …
audio_recorder.startRecording();
while (is_recording) {
byte[] this_buffer = new byte[frame_buffer_size];
read_result = audio_recorder.read(this_buffer, 0, frame_buffer_size); // read audio raw data
// …
presentationTimeStamp = System.nanoTime() / 1000;
audioEncoder.offerAudioEncoder(this_buffer.clone(), presentationTimeStamp); // feed to audio encoder
}
这里也可以设置AudioRecord的回调(通过setRecordPositionUpdateListener())来触发音频数据的读取。offerAudioEncoder()里主要是把audio采样数据送入音频MediaCodec的InputBuffer进行编码:
ByteBuffer[] inputBuffers = mAudioEncoder.getInputBuffers();
int inputBufferIndex = mAudioEncoder.dequeueInputBuffer(-1);
if (inputBufferIndex >= 0) {
ByteBuffer inputBuffer = inputBuffers[inputBufferIndex];
inputBuffer.clear();
inputBuffer.put(this_buffer);
…
mAudioEncoder.queueInputBuffer(inputBufferIndex, 0, this_buffer.length, presentationTimeStamp, 0);
}
下面,参考Grafika-SoftInputSurfaceActivity,并加入音频处理。主循环大体分四部分:
try {
// Part 1
prepareEncoder(outputFile);
…
// Part 2
for (int i = 0; i < NUM_FRAMES; i++) {
generateFrame(i);
drainVideoEncoder(false);
drainAudioEncoder(false);
}
// Part 3
…
drainVideoEncoder(true);
drainAudioEncoder(true);
} catch (IOException ioe) {
throw new RuntimeException(ioe);
} finally {
// Part 4
releaseEncoder();
}
第1部分是准备工作,除了video的MediaCodec,这里还初始化了audio的MediaCodec:
MediaFormat audioFormat = new MediaFormat();
audioFormat.setInteger(MediaFormat.KEY_SAMPLE_RATE, 44100);
audioFormat.setInteger(MediaFormat.KEY_CHANNEL_COUNT, 1);
…
mAudioEncoder = MediaCodec.createEncoderByType(AUDIO_MIME_TYPE);
mAudioEncoder.configure(audioFormat, null, null, MediaCodec.CONFIGURE_FLAG_ENCODE);
mAudioEncoder.start();
第2部分进入主循环,app在Surface上直接绘图,由于这个Surface是从MediaCodec中用createInputSurface()申请来的,所以画完后不用显式用queueInputBuffer()交给Encoder。drainVideoEncoder()和drainAudioEncoder()分别将编码好的音视频从buffer中拿出来(通过dequeueOutputBuffer()),然后交由MediaMuxer进行混合(通过writeSampleData())。注意音视频通过PTS(Presentation time stamp,决定了某一帧的音视频数据何时显示或播放)来同步,音频的time stamp需在AudioRecord从MIC采集到数据时获取并放到相应的bufferInfo中,视频由于是在Surface上画,因此直接用dequeueOutputBuffer()出来的bufferInfo中的就行,最后将编码好的数据送去MediaMuxer进行多路混合。
注意这里Muxer要等把audio track和video track都加入了再开始。MediaCodec在一开始调用dequeueOutputBuffer()时会返回一次INFO_OUTPUT_FORMAT_CHANGED消息。我们只需在这里获取该MediaCodec的format,并注册到MediaMuxer里。接着判断当前audio track和video track是否都已就绪,如果是的话就启动Muxer。
总结来说,drainVideoEncoder()的主逻辑大致如下,drainAudioEncoder也是类似的,只是把video的MediaCodec换成audio的MediaCodec即可。
写在最后
由于本文罗列的知识点是根据我自身总结出来的,并且由于本人水平有限,无法全部提及,欢迎大神们能补充~
将来我会对上面的知识点一个一个深入学习,也希望有童鞋跟我一起学习,一起进阶。
提升架构认知不是一蹴而就的,它离不开刻意学习和思考。
**这里,笔者分享一份从架构哲学的层面来剖析的视频及资料分享给大家,**梳理了多年的架构经验,筹备近1个月最新录制的,相信这份视频能给你带来不一样的启发、收获。
最近还在整理并复习一些Android基础知识点,有问题希望大家够指出,谢谢。
希望读到这的您能转发分享和关注一下我,以后还会更新技术干货,谢谢您的支持!
转发+点赞+关注,第一时间获取最新知识点
Android架构师之路很漫长,一起共勉吧!
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门,即可获取!
以后还会更新技术干货,谢谢您的支持!
转发+点赞+关注,第一时间获取最新知识点
Android架构师之路很漫长,一起共勉吧!
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门,即可获取!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









