







 文章讲述了作者在分析百度贴吧帖子时遇到的反爬问题,通过源码分析发现内容被HTML注释隐藏,随后介绍了解决方法并展示了如何使用Python的requests和lxml库处理问题,提取帖子标题和链接。同时,文中还提到了作者作为技术专家对于前端开发者学习资源和面试经验的分享。
文章讲述了作者在分析百度贴吧帖子时遇到的反爬问题,通过源码分析发现内容被HTML注释隐藏,随后介绍了解决方法并展示了如何使用Python的requests和lxml库处理问题,提取帖子标题和链接。同时,文中还提到了作者作为技术专家对于前端开发者学习资源和面试经验的分享。

目录
-
- 📋 个人简介
-
🧨前言
-
- 🧧分析
-
🧧源码
-
🧧结果
-
🧨结语
===================================================================
百度贴吧!曾今一代人的回忆,曾经用了一年时间就成长为了全球最大的中文社区。用户量超 15 亿,曾诞生无数金句!“贾君鹏,你妈喊你回家吃饭”、“帝吧出征,寸草不生”,当年流行一句“吧友一起吼一吼,整个互联网都要抖三抖。”由此可见当年的贴吧多么火爆,即使今天大不如从前了,但阿牛依旧是贴吧资深吧友,闲暇时常去刷搞笑段子,那么今天阿牛对贴吧下手了!
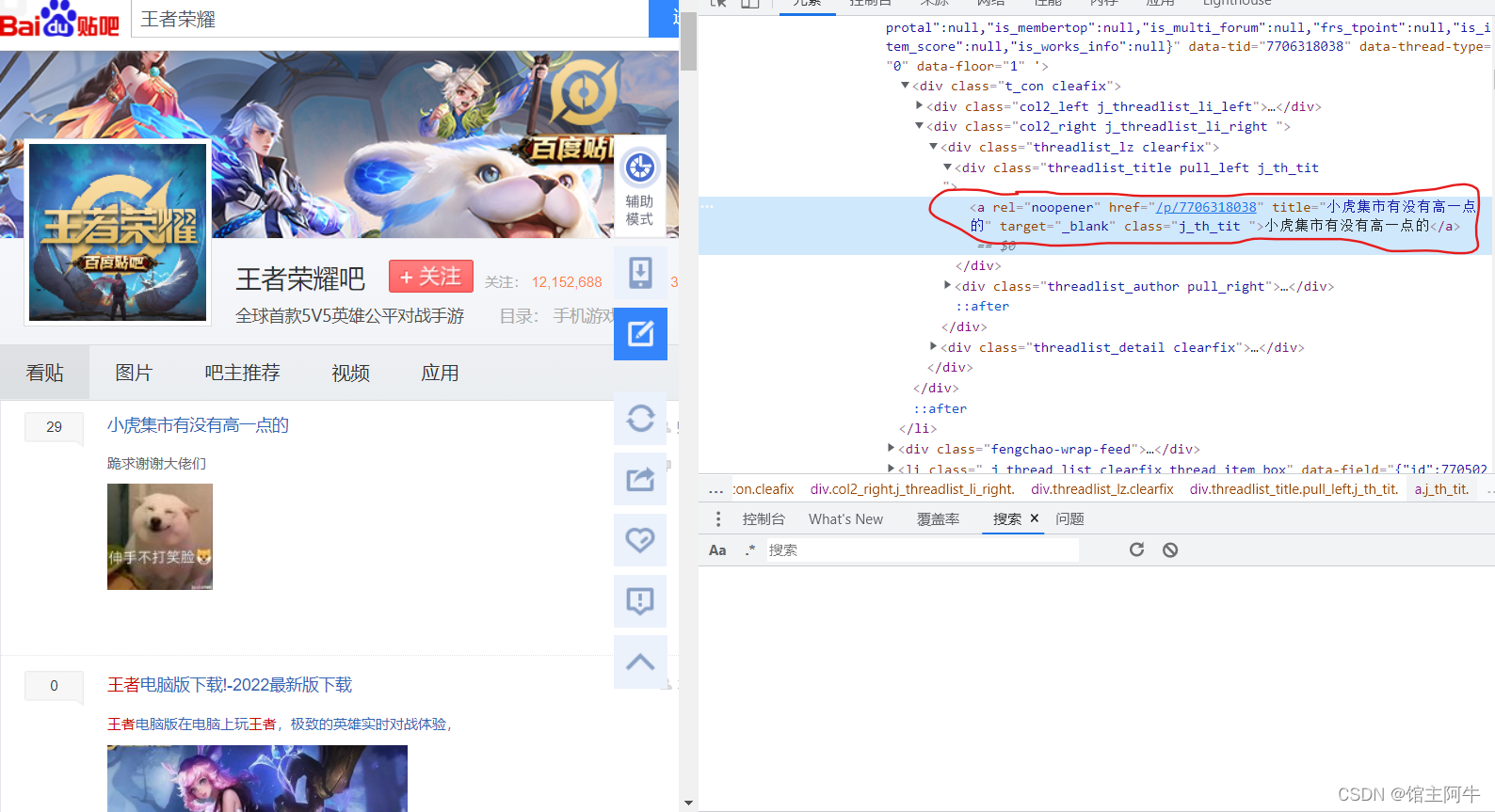
今天目标是帖子的标题和链接,从标题中就可以看出很多内容了,接下来做一个分页处理就好了
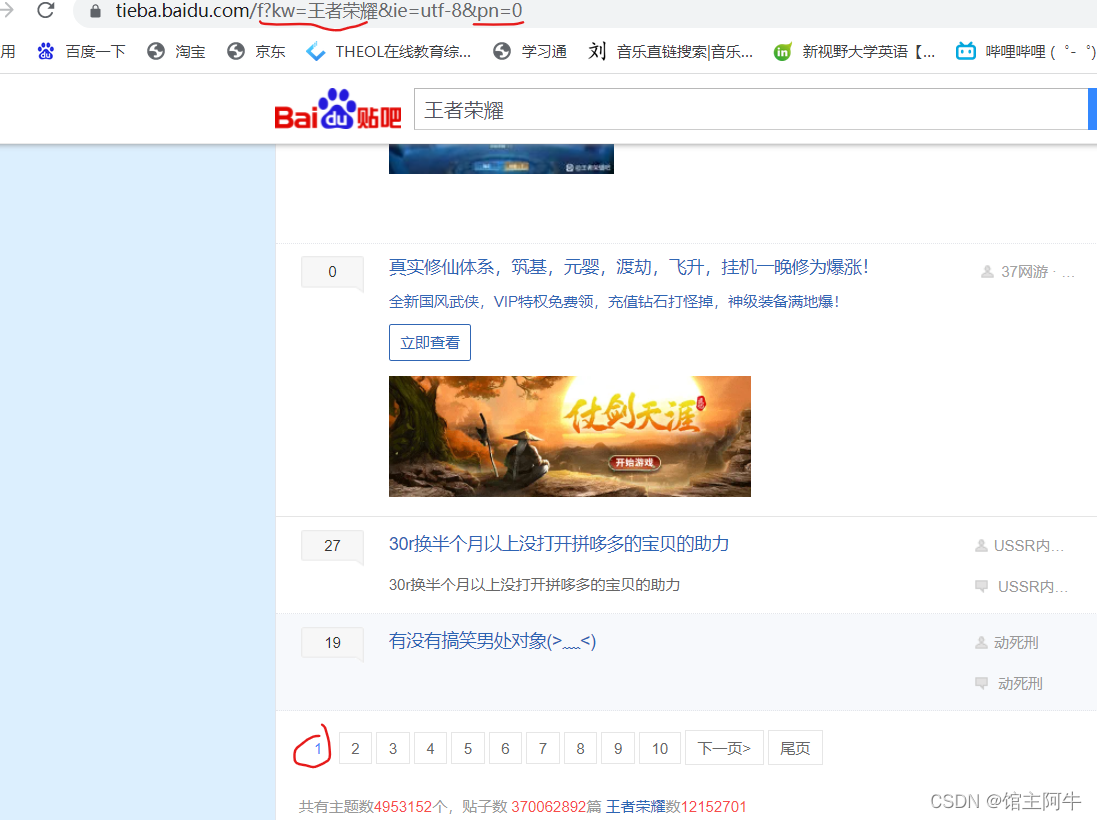
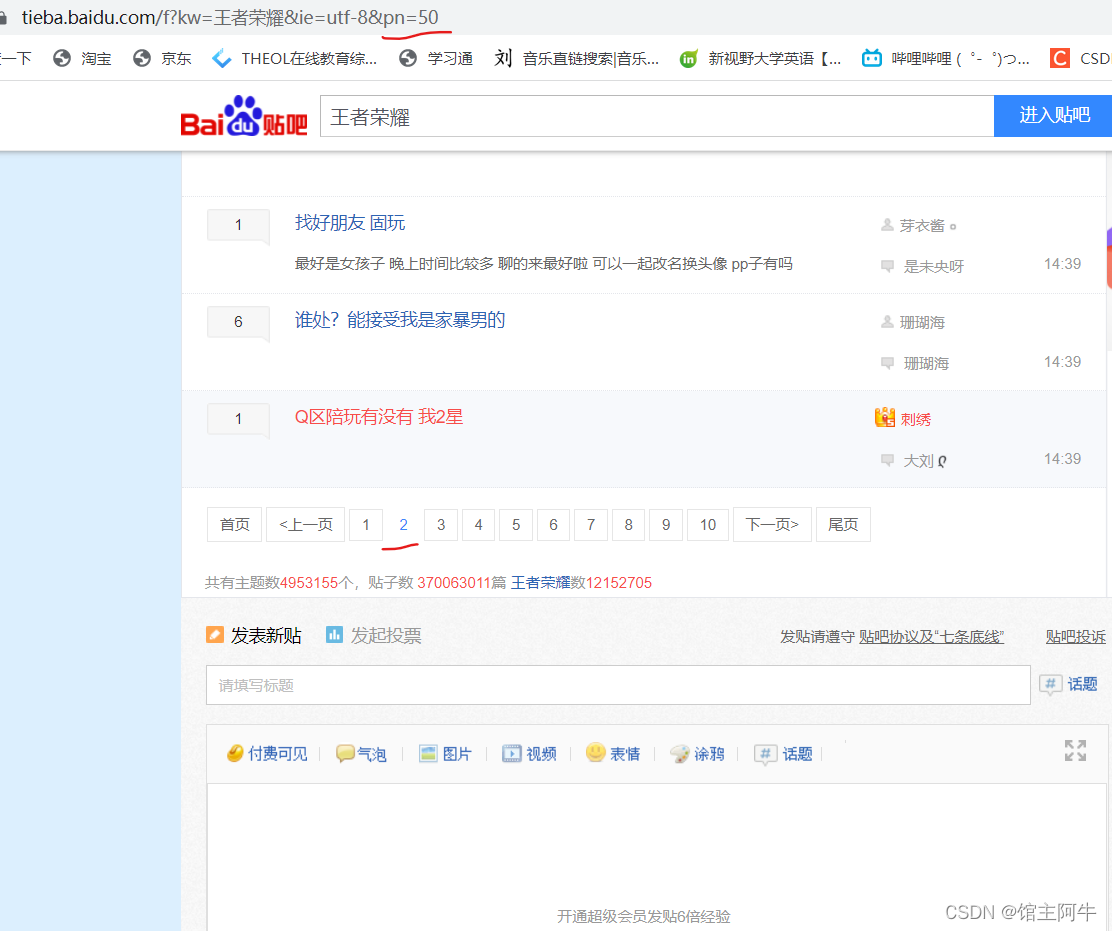
可以观察出页码是由pn参数决定的,第一页pn=0,第二页pn=50,第三页pn=100,以此类推。另外,可以看到链接中的参数kw就是我们搜索的参数,可以用上,把爬虫写活一点!
正常分析就完成了,那我们上代码看看
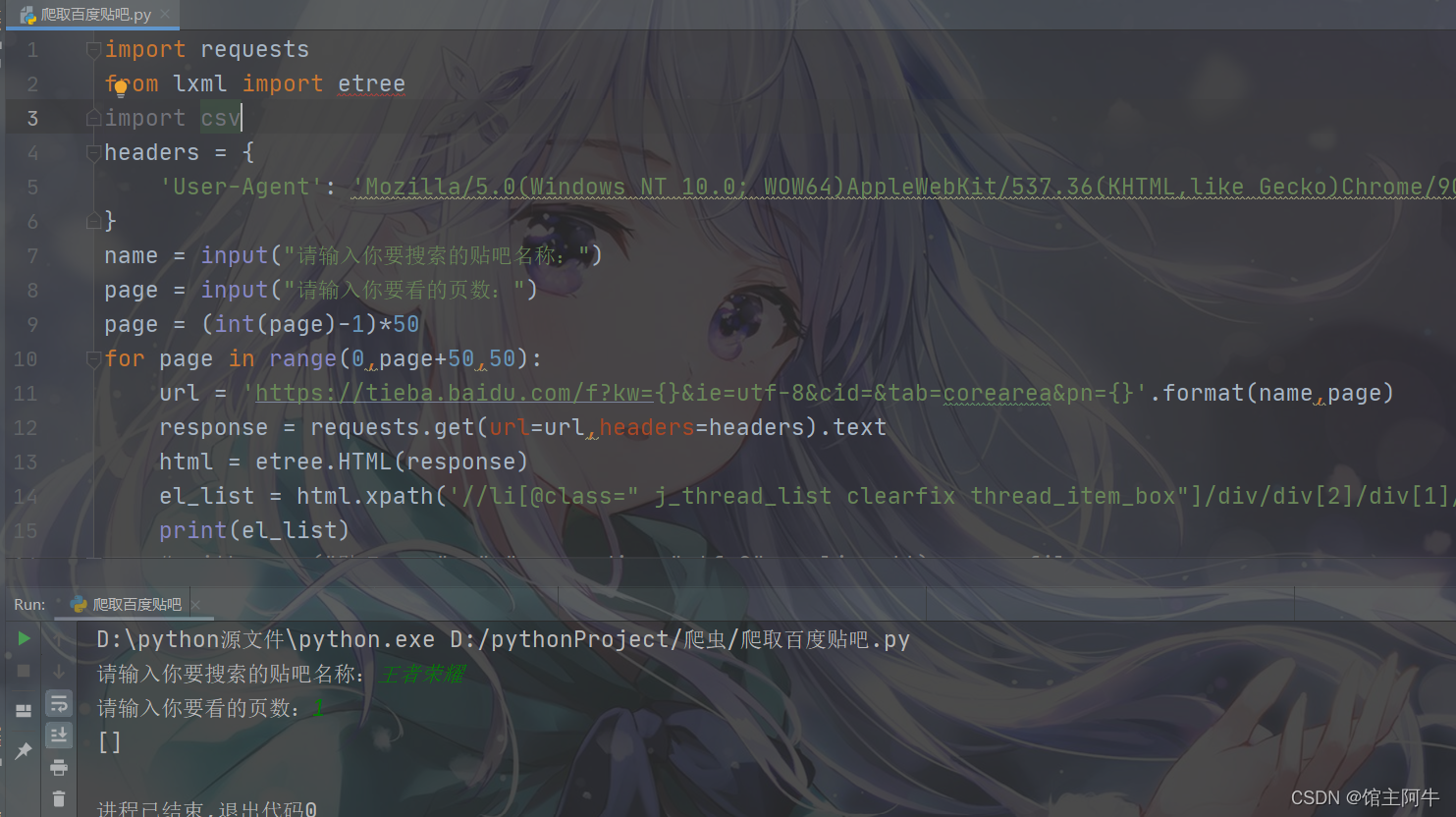
好家伙,出问题了,没有匹配到所有要提取信息的元素节点,列表为空,这可把阿牛整懵了,学到现在,阿牛对xpath一直用xpath helper,不会出错,不信你们看:
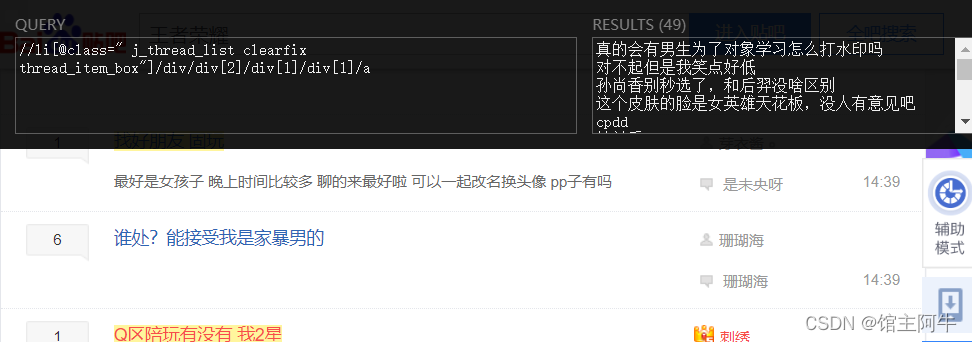
正常猜想是反爬了,不急,先打开网页源代码看一手,不看不知道,一看吓一跳,源码中内容是注释掉的,在浏览器通过渲染去掉了注释。
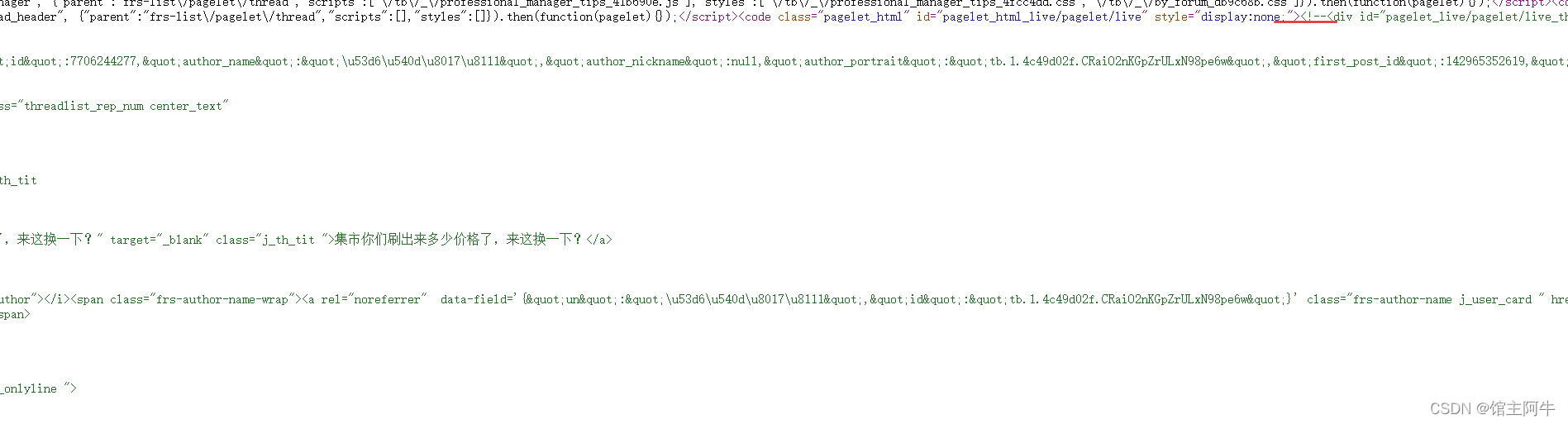
所以我们拿到的内容是注释掉的,需要处理去掉HTML的注释符号,我们的xpath才能生效。
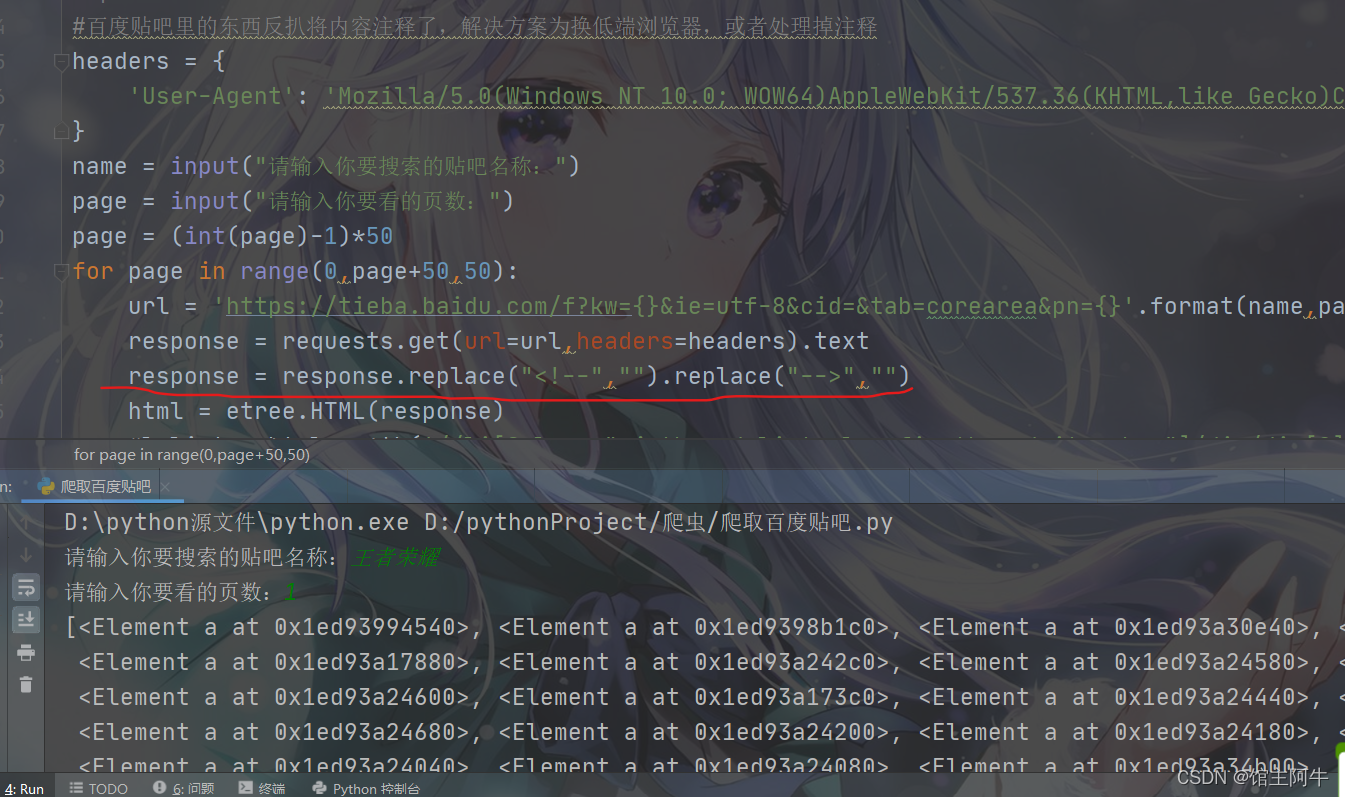
果然去掉注释后我们拿到了对象,接下来我们就可以进行数据提取了,最后把他存为csv文件。
import requests
from lxml import etree
import csv
#百度贴吧里的东西反扒将内容注释了,解决方案为换低端浏览器,或者处理掉注释
headers = {
‘User-Agent’: ‘Mozilla/5.0(Windows NT 10.0; WOW64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/90.0.4430.85 Safari/537.’,
}
name = input(“请输入你要搜索的贴吧名称:”)
page = input(“请输入你要看的页数:”)
page = (int(page)-1)*50
for page in range(0,page+50,50):
url = ‘https://tieba.baidu.com/f?kw={}&ie=utf-8&cid=&tab=corearea&pn={}’.format(name,page)
response = requests.get(url=url,headers=headers).text
#去掉html的注释符号
response = response.replace(“ ”,“”)
html = etree.HTML(response)
el_list = html.xpath(‘//li[@class=" j_thread_list clearfix thread_item_box"]/div/div[2]/div[1]/div[1]/a’)
print(el_list)
newline=‘’ 去掉存进csv文件内容之间的空行
with open(“贴吧.csv”, “w”, encoding=“utf-8”,newline=‘’) as csvfile:
fieldnames = [“title”, “link”]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for el in el_list:
temp = {}
temp[‘title’] = el.xpath(“./text()”)[0]
#给链接拼接域名
temp[‘link’] = ‘https://tieba.baidu.com’+el.xpath(“./@href”)[0]
print(temp)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数前端工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:前端)

总结一下这三次面试下来我的经验是:
-
一定不要死记硬背,要理解原理,否则面试官一深入就会露馅!
-
代码能力一定要注重,尤其是很多原理性的代码(之前两次让我写过Node中间件,Promise.all,双向绑定原理,被虐的怀疑人生)!
-
尽量从面试官的问题中表现自己知识的深度与广度,让面试官发现你的闪光点!
-
多刷面经!
我把所有遇到的面试题都做了一个整理,并且阅读了很多大牛的博客之后写了解析,免费分享给大家,算是一个感恩回馈吧,有需要的朋友【点击我】获取。祝大家早日拿到自己心怡的工作!
篇幅有限,仅展示部分内容



8a77e76478.png)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









