







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
在当今数字化时代,数据已经成为企业成功的关键要素之一。随着数据量的不断增长和数据处理需求的不断提高,构建高效、可靠的大数据体系成为了企业面临的重要挑战之一。在这个过程中,Apache Kafka作为一个分布式流处理平台,扮演着至关重要的角色。它不仅提供了高吞吐量、低延迟的消息传输服务,还支持实时数据流处理和复杂的事件驱动架构。

概要:
从Kafka的工作原理、集群架构和应用场景三个方面对其进行深入探讨。首先,我们将介绍Kafka的基本概念和核心组件,包括Producer、Consumer、Broker等,并深入探讨其消息存储和分发机制。接着,我们将详细解析Kafka集群的架构设计,包括ZooKeeper的角色、分区和副本的管理以及故障恢复机制。最后,我们将探讨Kafka在大数据领域的应用场景,包括实时日志处理、数据管道和ETL、实时推荐系统、分布式事务处理以及流式数据处理等,并通过实际案例展示其在不同场景下的应用和价值。
1. Kafka的基本概念
在开始深入了解Kafka的工作原理之前,需要了解一些基本概念:
- Producer(生产者): 将数据发布到Kafka主题(Topic)的应用程序。
- Consumer(消费者): 从Kafka主题中读取数据的应用程序。
- Broker(代理): Kafka集群中的服务器,负责存储数据和处理数据传输。
- Topic(主题): 数据发布的类别或分区。
- Partition(分区): 主题被分割成多个分区,每个分区在不同的服务器上。
- Offset(偏移量): 每个消息在分区中的唯一标识。
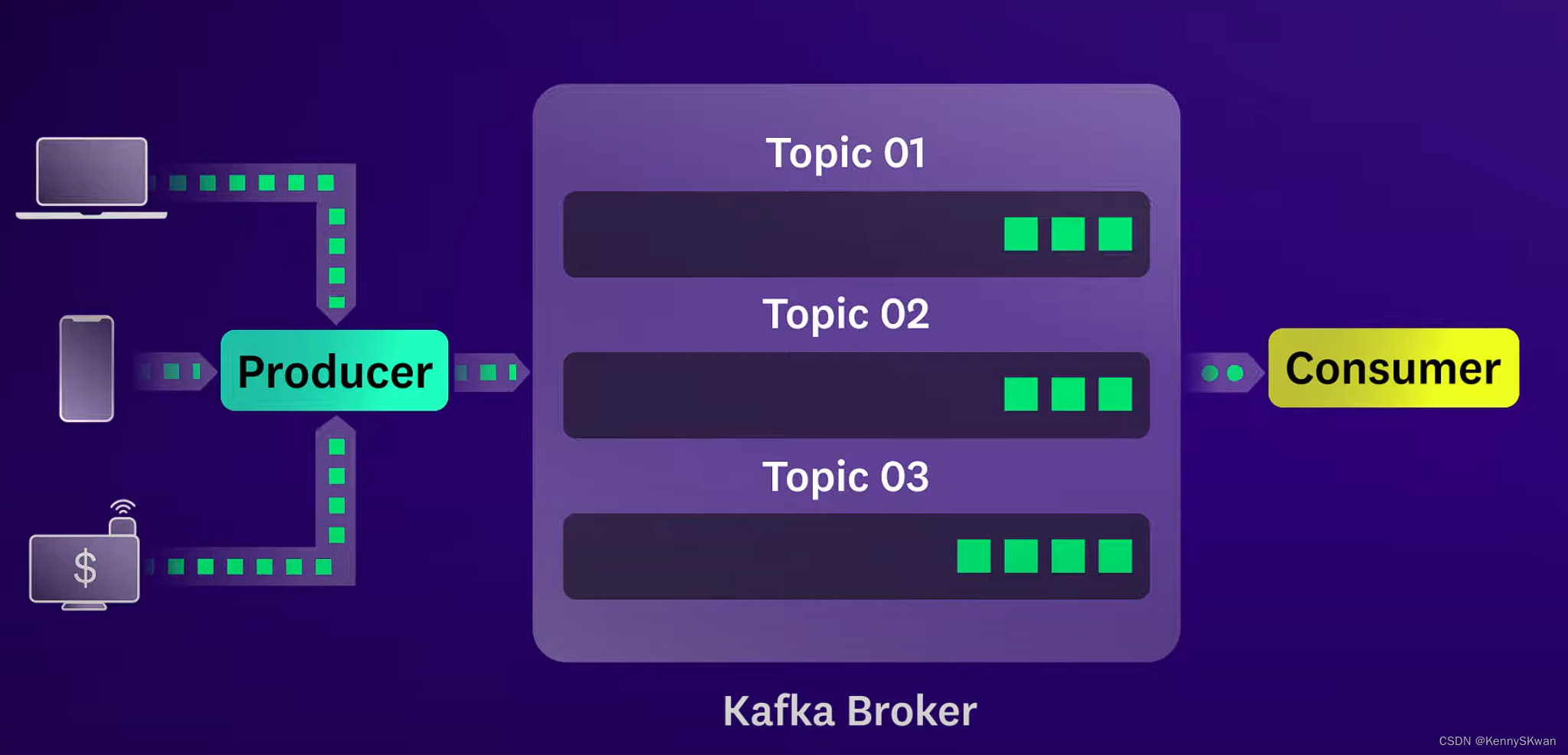
Kafka消息存储
- Kafka的消息存储是基于日志的,每个主题被分成一个或多个分区,每个分区是一个有序的消息队列。消息被追加到分区的末尾,并且保留一段时间(可以配置)。这种设计使得Kafka能够处理大量数据,并支持高吞吐量。
生产者发布消息
- 当生产者发送消息到Kafka时,它们首先连接到Kafka集群的一个Broker,并根据特定的分区策略将消息发布到一个或多个主题中的分区。生产者可以选择指定消息的键,这样消息将被发送到特定的分区,或者Kafka将基于负载均衡策略自动选择分区。
消费者消费消息
- 消费者从Kafka订阅一个或多个主题,并且会被分配到每个主题的一个或多个分区。消费者定期轮询Kafka Broker,拉取新的消息。一旦消费者拉取到消息,它们就会处理这些消息,并提交偏移量来记录自己的消费位置。
Kafka的水平扩展性
- Kafka通过分区和复制来实现水平扩展性和高可用性。分区允许数据水平分布在集群中的多个Broker上,从而允许Kafka处理大量数据。同时,Kafka通过复制每个分区到多个Broker上来提供容错性和可靠性。
2.Kafka集群组件
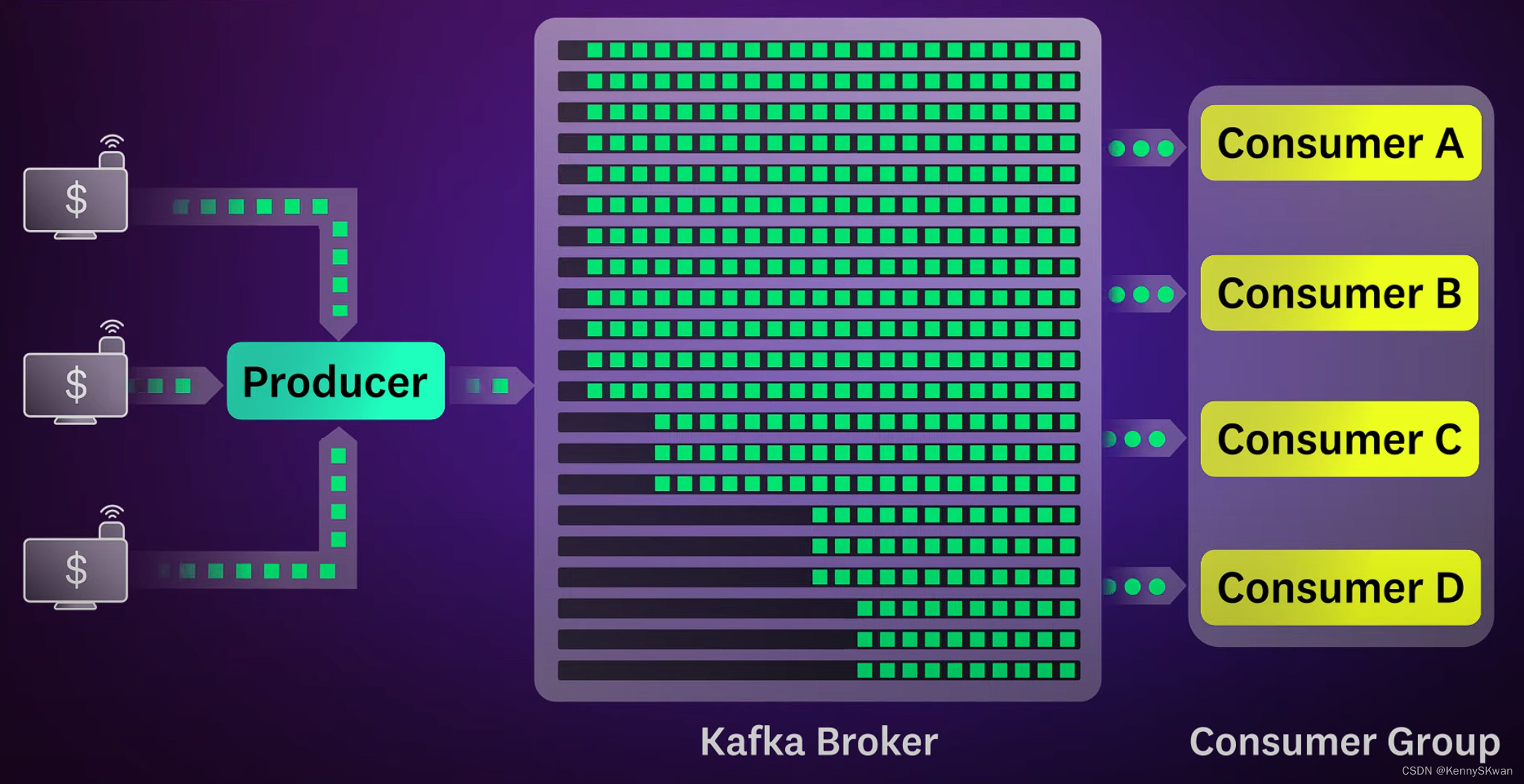
一个典型的Kafka集群包含以下组件:
- ZooKeeper:
ZooKeeper是一个分布式协调服务,Kafka依赖它来进行集群管理和领导者选举。ZooKeeper保存了Kafka集群的元数据(如主题、分区、副本分配等),并且监控Kafka Broker的健康状态。 - Broker:
Broker是Kafka集群中的服务器节点,负责存储和处理数据。每个Broker都是一个独立的Kafka服务器,它们共同组成了整个Kafka集群。 - Topic:
Topic是消息发布的类别或分区。在集群中,每个Topic都被分成一个或多个分区,这些分区分布在不同的Broker上。 - Partition:
Partition是Topic的子集,每个分区都是一个有序的消息队列。分区允许数据在多个Broker上进行并行处理,从而提高了吞吐量和可扩展性。
Kafka集群工作原理
- 启动:
当Kafka Broker启动时,它会向ZooKeeper注册自己的信息,包括主机名、端口号等。ZooKeeper会维护所有Broker的信息,并监控它们的健康状态。 - 元数据管理:
ZooKeeper保存了Kafka集群的元数据,包括Topic、分区、副本分配等信息。这些元数据被用来协调Broker之间的消息路由和复制。 - Leader-Follower模式:
对于每个分区,Kafka会选举出一个Broker作为Leader,并将其他Broker设置为Follower。Leader负责处理所有的读写请求,而Follower则负责复制Leader的数据。当Leader失效时,ZooKeeper会协助选举新的Leader。 - 消息发布和消费:
生产者将消息发布到指定的Topic,Kafka根据分区策略将消息分配到各个分区中。消费者从Topic订阅消息,并根据分配的分区拉取数据。Kafka会保证消息的顺序性和一致性,以及消费者的负载均衡。 - 水平扩展:
Kafka通过增加Broker节点和分区来实现水平扩展。每个Broker负责处理一部分数据和请求,从而提高了集群的吞吐量和容量。
Kafka集群的可靠性和容错性
- 副本复制:
每个分区都有多个副本,它们分布在不同的Broker上。当Leader失效时,Kafka会自动选择一个副本作为新的Leader,从而保证数据的可用性。 - ISR机制:
Kafka使用ISR(In-Sync Replicas)机制来确保副本之间的一致性。只有处于ISR中的副本才会被选举为新的Leader,这样可以防止数据丢失和不一致。 - 故障恢复:
当Broker或者分区发生故障时,Kafka会自动进行故障恢复,包括重新选举Leader和同步数据等操作。
3.Kafka在大数据的应用场景
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
vXHU0M2-1713433539314)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









