







{
“name”: “66718a266132”,
“cluster_name”: “elasticsearch”,
“cluster_uuid”: “xhDnsLynQ3WyRdYmQk5xhQ”,
“version”: {
“number”: “7.4.2”,
“build_flavor”: “default”,
“build_type”: “docker”,
“build_hash”: “2f90bbf7b93631e52bafb59b3b049cb44ec25e96”,
“build_date”: “2019-10-28T20:40:44.881551Z”,
“build_snapshot”: false,
“lucene_version”: “8.2.0”,
“minimum_wire_compatibility_version”: “6.8.0”,
“minimum_index_compatibility_version”: “6.0.0-beta1”
},
“tagline”: “You Know, for Search”
}
## ES常用命令
访问Kibana: http://192.168.56.10:5601/app/kibana
### 1、检索es信息
(1)**GET /\_cat/nodes**:查看所有节点
如:http://192.168.56.10:9200/\_cat/nodes
可以直接浏览器输入上面的url,也可以在kibana中输入GET /\_cat/nodes
127.0.0.1 12 97 3 0.00 0.01 0.05 dilm * 66718a266132
66718a266132代表结点
*代表是主节点
(2)**GET /\_cat/health**:查看es健康状况
如: http://192.168.56.10:9200/\_cat/health
1613741055 13:24:15 elasticsearch green 1 1 0 0 0 0 0 0 - 100.0%
注:green表示健康值正常
(3)**GET /\_cat/master**:查看主节点
如: http://192.168.56.10:9200/\_cat/master
089F76WwSaiJcO6Crk7MpA 127.0.0.1 127.0.0.1 66718a266132
主节点唯一编号
虚拟机地址
(4)**GET/\_cat/indicies**:查看所有索引 ,等价于mysql数据库的show databases;
如:http://192.168.56.10:9200/\_cat/indices
green open .kibana_task_manager_1 DhtDmKrsRDOUHPJm1EFVqQ 1 0 2 3 40.8kb 40.8kb
green open .apm-agent-configuration vxzRbo9sQ1SvMtGkx6aAHQ 1 0 0 0 230b 230b
green open .kibana_1 rdJ5pejQSKWjKxRtx-EIkQ 1 0 5 1 18.2kb 18.2kb
这3个索引是kibana创建的
### 2、新增文档
保存一个数据,保存在哪个索引的哪个类型下(哪张数据库哪张表下),保存时用唯一标识指定
# 在customer索引下的external类型下保存1号数据
PUT customer/external/1
POSTMAN输入
http://192.168.56.10:9200/customer/external/1
{
“name”:“John Doe”
}
**PUT和POST区别**
* POST新增。如果不指定id,会自动生成id。指定id就会修改这个数据,并新增版本号;
* + 可以不指定id,不指定id时永远为创建
* + 指定不存在的id为创建
* + 指定存在的id为更新,而版本号会根据内容变没变而觉得版本号递增与否
* PUT可以新增也可以修改。PUT必须指定id;由于PUT需要指定id,我们一般用来做修改操作,不指定id会报错
* + 必须指定id
* + 版本号总会增加
**怎么记:put和java里map.put一样必须指定key-value。而post相当于mysql insert**
**seq\_no和version的区别:**
每个文档的版本号"\_version" 起始值都为1 每次对当前文档成功操作后都加1
而序列号"\_seq\_no"则可以看做是索引的信息 在第一次为索引插入数据时为0,每对索引内数据操作成功一次sqlNO加1, 并且文档会记录是第几次操作使它成为现在的情况的
可以参考https://www.cnblogs.com/Taeso/p/13363136.html
下面是在postman中的测试数据:
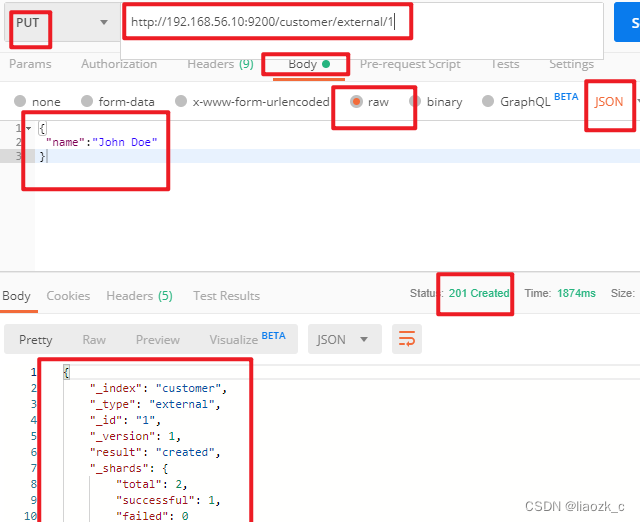
创建数据成功后,显示201 created表示插入记录成功。
返回数据:
带有下划线开头的,称为元数据,反映了当前的基本信息。
{
“_index”: “customer”, 表明该数据在哪个数据库下;
“_type”: “external”, 表明该数据在哪个类型下;
“_id”: “1”, 表明被保存数据的id;
“_version”: 1, 被保存数据的版本
“result”: “created”, 这里是创建了一条数据,如果重新put一条数据,则该状态会变为updated,并且版本号也会发生变化。
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 0,
“_primary_term”: 1
}
下面选用POST方式:
添加数据的时候,不指定ID,会自动的生成id,并且类型是新增:
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “5MIjvncBKdY1wAQm-wNZ”,
“_version”: 1,
“result”: “created”,
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 11,
“_primary_term”: 6
}
再次使用POST插入数据,不指定ID,仍然是新增的:
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “5cIkvncBKdY1wAQmcQNk”,
“_version”: 1,
“result”: “created”,
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 12,
“_primary_term”: 6
}
添加数据的时候,指定ID,会使用该id,并且类型是新增:
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “2”,
“_version”: 1,
“result”: “created”,
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 13,
“_primary_term”: 6
}
再次使用POST插入数据,指定同样的ID,类型为updated
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “2”,
“_version”: 2,
“result”: “updated”,
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 14,
“_primary_term”: 6
}
### 3、查看文档
**GET /customer/external/1**
http://192.168.56.10:9200/customer/external/1
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “1”,
“_version”: 10,
“_seq_no”: 18,//并发控制字段,每次更新都会+1,用来做乐观锁
“_primary_term”: 6,//同上,主分片重新分配,如重启,就会变化
“found”: true,
“_source”: {
“name”: “John Doe”
}
}
**乐观锁用法**:通过“if\_seq\_no=1&if\_primary\_term=1”,当序列号匹配的时候,才进行修改,否则不修改。
**实例**:将id=1的数据更新为name=1,然后再次更新为name=2,起始1\_seq\_no=18,\_primary\_term=6
#### 将name更新为1
PUT http://192.168.56.10:9200/customer/external/1?if\_seq\_no=18&if\_primary\_term=6
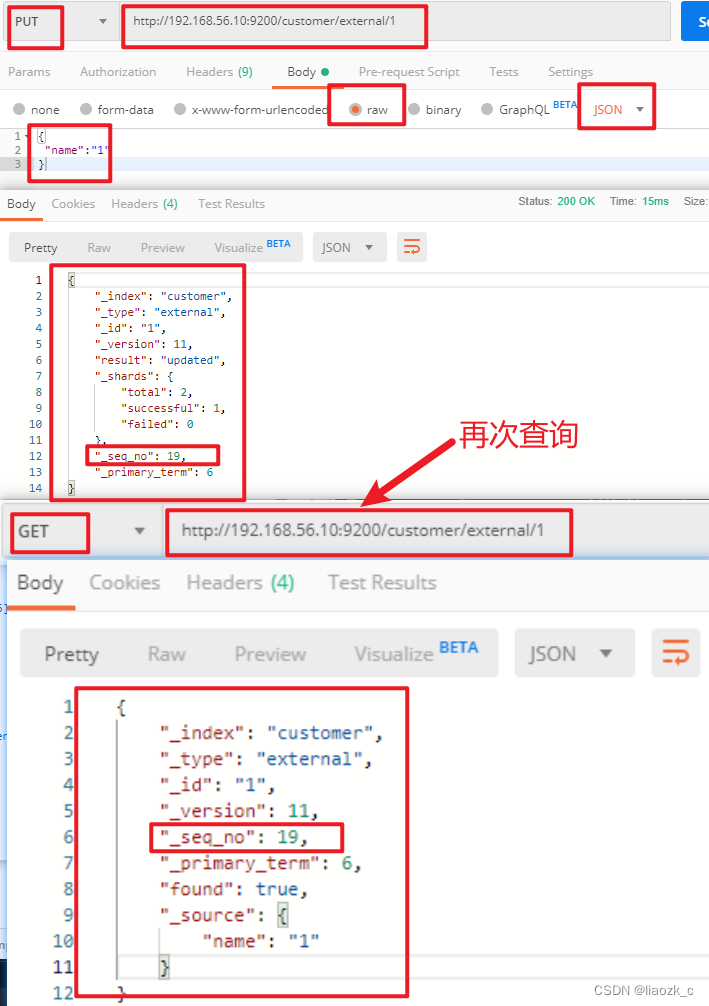
#### (2)将name更新为2,更新过程中使用seq\_no=18
PUT http://192.168.56.10:9200/customer/external/1?if\_seq\_no=18&if\_primary\_term=6
结果为:
{
“error”: {
“root_cause”: [
{
“type”: “version_conflict_engine_exception”,
“reason”: “[1]: version conflict, required seqNo [18], primary term [6]. current document has seqNo [19] and primary term [6]”,
“index_uuid”: “mG9XiCQISPmfBAmL1BPqIw”,
“shard”: “0”,
“index”: “customer”
}
],
“type”: “version_conflict_engine_exception”,
“reason”: “[1]: version conflict, required seqNo [18], primary term [6]. current document has seqNo [19] and primary term [6]”,
“index_uuid”: “mG9XiCQISPmfBAmL1BPqIw”,
“shard”: “0”,
“index”: “customer”
},
“status”: 409
}
出现更新错误。
#### (3)查询新的数据
GET http://192.168.56.10:9200/customer/external/1
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “1”,
“_version”: 11,
“_seq_no”: 19,
“_primary_term”: 6,
“found”: true,
“_source”: {
“name”: “1”
}
}
能够看到\_seq\_no变为19
#### (4)再次更新,更新成功
PUT http://192.168.56.10:9200/customer/external/1?if\_seq\_no=19&if\_primary\_term=1
### 4、更新文档\_update
POST customer/externel/1/_update
{
“doc”:{
“name”:“111”
}
}
或者
POST customer/externel/1
{
“doc”:{
“name”:“222”
}
}
或者
PUT customer/externel/1
{
“doc”:{
“name”:“222”
}
}
不同:带有update情况下
* POST操作会对比源文档数据,如果相同不会有什么操作,文档version不增加。
* PUT操作总会重新保存并增加version版本
POST时带\_update对比元数据如果一样就不进行任何操作。
看场景:
* 对于大并发更新,不带update
* 对于大并发查询偶尔更新,带update;对比更新,重新计算分配规则
#### (1)POST更新文档,带有\_update
http://192.168.56.10:9200/customer/external/1/\_update
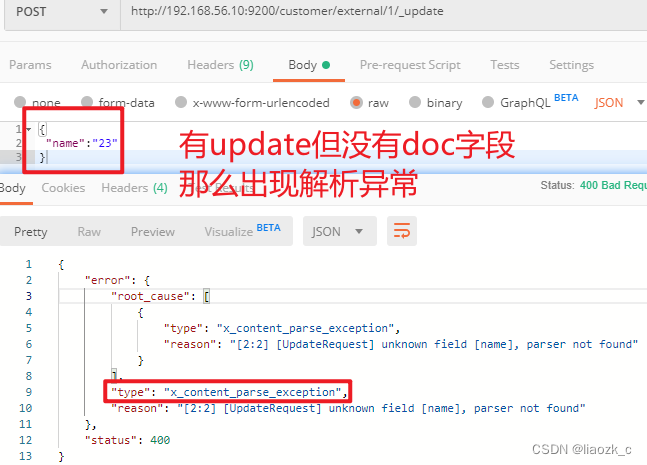
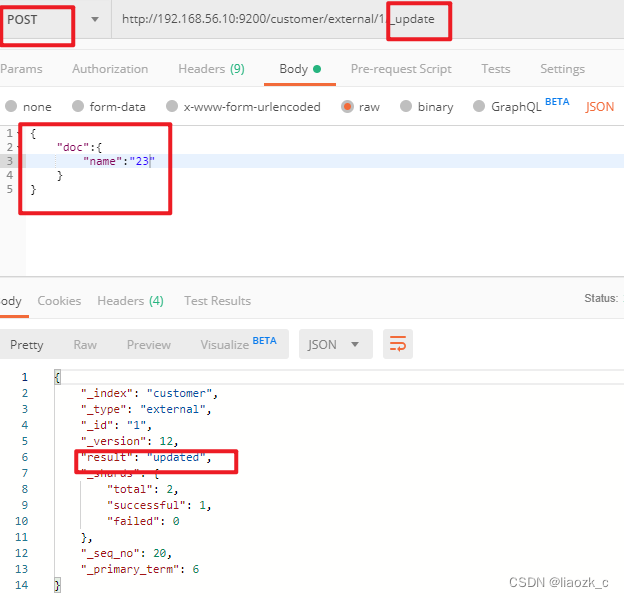
如果再次执行更新,则不执行任何操作,序列号也不发生变化,返回:
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “1”,
“_version”: 12,
“result”: “noop”, // 无操作
“_shards”: {
“total”: 0,
“successful”: 0,
“failed”: 0
},
“_seq_no”: 20,
“_primary_term”: 6
}
POST更新方式,会对比原来的数据,和原来的相同,则不执行任何操作(version和\_seq\_no)都不变。
#### (2)POST更新文档,不带\_update
在更新过程中,重复执行更新操作,数据也能够更新成功,不会和原来的数据进行对比
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “1”,
“_version”: 13,
“result”: “updated”,
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 21,
“_primary_term”: 6
}
### 5、删除文档或索引
DELETE customer/external/1
DELETE customer
**注**:elasticsearch并没有提供删除类型的操作,只提供了删除索引和文档的操作。
实例:删除id=1的数据,删除后继续查询
DELETE http://192.168.56.10:9200/customer/external/1
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “1”,
“_version”: 14,
“result”: “deleted”,
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 22,
“_primary_term”: 6
}
再次执行DELETE http://192.168.56.10:9200/customer/external/1
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “1”,
“_version”: 15,
“result”: “not_found”,
“_shards”: {
“total”: 2,
“successful”: 1,
“failed”: 0
},
“_seq_no”: 23,
“_primary_term”: 6
}
GET http://192.168.56.10:9200/customer/external/1
{
“_index”: “customer”,
“_type”: “external”,
“_id”: “1”,
“found”: false
}
**删除索引**
实例:删除整个costomer索引数据
删除前,所有的索引http://192.168.56.10:9200/\_cat/indices
green open .kibana_task_manager_1 DhtDmKrsRDOUHPJm1EFVqQ 1 0 2 0 31.3kb 31.3kb
green open .apm-agent-configuration vxzRbo9sQ1SvMtGkx6aAHQ 1 0 0 0 283b 283b
green open .kibana_1 rdJ5pejQSKWjKxRtx-EIkQ 1 0 8 3 28.8kb 28.8kb
yellow open customer mG9XiCQISPmfBAmL1BPqIw 1 1 9 1 8.6kb 8.6kb
删除“ customer ”索引
DELTE http://192.168.56.10:9200/customer
响应:
{
“acknowledged”: true
}
删除后,所有的索引http://192.168.56.10:9200/\_cat/indices
green open .kibana_task_manager_1 DhtDmKrsRDOUHPJm1EFVqQ 1 0 2 0 31.3kb 31.3kb
green open .apm-agent-configuration vxzRbo9sQ1SvMtGkx6aAHQ 1 0 0 0 283b 283b
green open .kibana_1 rdJ5pejQSKWjKxRtx-EIkQ 1 0 8 3 28.8kb 28.8kb
### 6、ES的批量操作——bulk
匹配导入数据
POST http://192.168.56.10:9200/customer/external/\_bulk
两行为一个整体
{“index”:{“_id”:“1”}}
{“name”:“a”}
{“index”:{“_id”:“2”}}
{“name”:“b”}
注意格式json和text均不可,要去kibana里Dev Tools
语法格式:
{action:{metadata}}\n
{request body }\n
{action:{metadata}}\n
{request body }\n
这里的批量操作,当发生某一条执行发生失败时,其他的数据仍然能够接着执行,也就是说彼此之间是独立的。
bulk api以此按顺序执行所有的action(动作)。如果一个单个的动作因任何原因失败,它将继续处理它后面剩余的动作。当bulk api返回时,它将提供每个动作的状态(与发送的顺序相同),所以您可以检查是否一个指定的动作是否失败了。
实例1: 执行多条数据
POST /customer/external/_bulk
{“index”:{“_id”:“1”}}
{“name”:“John Doe”}
{“index”:{“_id”:“2”}}
{“name”:“John Doe”}
执行结果
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{
“took” : 318, 花费了多少ms
“errors” : false, 没有发生任何错误
“items” : [ 每个数据的结果
{
“index” : { 保存
“_index” : “customer”, 索引
“_type” : “external”, 类型
“_id” : “1”, 文档
“_version” : 1, 版本
“result” : “created”, 创建
“_shards” : {
“total” : 2,
“successful” : 1,
“failed” : 0
},
“_seq_no” : 0,
“_primary_term” : 1,
“status” : 201 新建完成
}
},
{
“index” : { 第二条记录
“_index” : “customer”,
“_type” : “external”,
“_id” : “2”,
“_version” : 1,
“result” : “created”,
“_shards” : {
“total” : 2,
“successful” : 1,
“failed” : 0
},
“_seq_no” : 1,
“_primary_term” : 1,
“status” : 201
}
}
]
}
实例2:对于整个索引执行批量操作
POST /_bulk
{“delete”:{“_index”:“website”,“_type”:“blog”,“_id”:“123”}}
{“create”:{“_index”:“website”,“_type”:“blog”,“_id”:“123”}}
{“title”:“my first blog post”}
{“index”:{“_index”:“website”,“_type”:“blog”}}
{“title”:“my second blog post”}
{“update”:{“_index”:“website”,“_type”:“blog”,“_id”:“123”}}
{“doc”:{“title”:“my updated blog post”}}
运行结果:
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{
“took” : 304,
“errors” : false,
“items” : [
{
“delete” : { 删除
“_index” : “website”,
“_type” : “blog”,
“_id” : “123”,
“_version” : 1,
“result” : “not_found”, 没有该记录
“_shards” : {
“total” : 2,
“successful” : 1,
“failed” : 0
},
“_seq_no” : 0,
“_primary_term” : 1,
“status” : 404 没有该
}
},
{
“create” : { 创建
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

{
"create" : { 创建
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
[外链图片转存中…(img-KNuaWbaW-1712829723774)]
[外链图片转存中…(img-aHkNDv4g-1712829723775)]
[外链图片转存中…(img-GMwJMxRS-1712829723776)]
[外链图片转存中…(img-ooWVKoE5-1712829723776)]
[外链图片转存中…(img-Uy7URqm7-1712829723777)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-VrGvj1On-1712829723777)]
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









