







 本文介绍了分治算法的核心步骤,特别是二分搜索策略在有序序列中的应用,包括问题分解、子问题求解和合并,以及二分搜索的时间复杂度分析。同时还提到了相关学习资源,如适合不同水平的学习材料和系统化的学习资料库。
本文介绍了分治算法的核心步骤,特别是二分搜索策略在有序序列中的应用,包括问题分解、子问题求解和合并,以及二分搜索的时间复杂度分析。同时还提到了相关学习资源,如适合不同水平的学习材料和系统化的学习资料库。
(3)子问题的解可以合并为原问题的解。
分治算法秘籍
(1)分解:将想要解决的问题分解为若干规模较小、相互独立、与原问题形式相同的子问题。
(2)治理:求解各个子问题。由于各个子问题与原问题形式相同,知识规模较小而已,因此当子问题划分的足够小时,就可以使用较简单的方法来解决。
(3)合并:按原问题的要求,将子问题的解逐层合并,构成原问题的解。
二分搜索
算法题目
某大型娱乐节目在玩猜数字游戏:主持人在女嘉宾的手心写一个10以内的整数,让女嘉宾的老公猜主持人写的数字是几,女嘉宾只能提示大了或小了,并且只有3次机会。
问题分析
从问题描述看,如果是n个数,那么最坏的情况需要猜分搜索n次才能成功。其实完全没必要一个数一个数地猜,因为这些数是有序的。可以使用二分搜索策略,每次和中间的元素做比较。如果比中间元素小,就在前半部分查找;如果比中间元间素大,就在后半部分查找。
算法步骤
一维 数组S[ ]用于存储有序序列,变量low 和high分别表示查找范围的下界和上界,middle 表示查找范围的中间位置,x为特定的查找元素。
(1)初始化。令low=0、high=n-1, 分别指向有序数组S[ ]中的第一个元素和最后一个元素。
(2) middle=(low+high)/2, 指向查找范围的中间元素。
(3) 如果low ≤ high, 转向步骤(4), 否则算法结束。
(4)如果 x = S[middle] , 则查找成功,算法结束。如果x > S[middle] , 则令low = middle + 1;否则令 high = middle - 1,转向步骤(2)。
完美图解
在有序序列 (5,8. 15, 17. 25, 30. 34, 39, 45,52, 60) 中查找元素17的详细过程如下。
(1) 确定合适的数据结构。用一维数组S[ ]存储该有序序列,x = 17, 如下图所示。

(2) 初始化。令low = 0、high = 10, 计算 middle=(low+high)/2=5 , 如下图所示。

(3) 将 x 与 S[middle] 做比较。S[middle] = 30, x<S[middle],令high = middle-1,在序列的前半部分查找,搜索范围缩小到子问题S[0…middle-1] , 如下图所示。

(4) 计算 middle = (low+high) / 2 = 2,如下图所示。
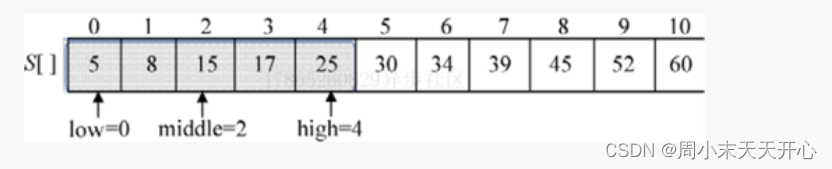
(5) 将x 与 S[middle]做比较。S[middle]=15, x>S[middle], 令low = middle+1,在序列的后半部分查找,搜索范围缩小到子问题S[midde] +1…high],如下图所示。

(6) 计算 midde=(low+high)/2=3,如下图所示。

(7)将 x 与 S[middle]做比较。x = S[middle] = 17,查找成功,算法结束。
算法详解
下面使用BinarySearch(int s[ ] , int n , int x)函数实现二分搜索,其中s[ ]为有序数组,n为元素个数,x 为特定的查找元素。首先,令low指向有序数组的第一个元素,同时令high 指向有序数组的最后一个元素。如果 low <= high,则令 middle = (low + high) / 2,也就是令 middle 指向查找范围的中间元素。如果x = S[middle],则查找成功,返回元素的下标。如果x > S[middle],则令low = middle+1,在后半部分搜索;否则令high = middle -1, 在前半部分搜索。
一般情况下,如果low和high的数值不大,可以采用 middle=(low+high)/2 或者 middle = (low + high) >> 1。如果low和high的数值特别大,为避免low+high溢出,可以采用 middle = low+(high-low)/2。
int BinarySearch(int s[], int n, int x) { //二分搜索
int low = 0, high = n - 1;
//low 指向有序数组的第一个元素,high 指向有序数组的最后一个元素
while(low <= high) {
int middle = (low + high) / 2;
//middle 指向查找范围的中间元素
if(x == s[middle]) { //查找成功
return middle;
} else if(x > s[middle]) {
//x 大于中间元素,在前半部分查找
low = middle + 1;
} else {
//x 小于中间元素,在后半部分查找
high = middle - 1;
}
}
return -1;
}
算法分析
(1)时间复杂度:
sort 排序函数的时间复杂度为 O(nlogn),如果数列本身有序,那么这部分不用考虑。二分查找算法的时间复杂的怎么计算呢?如果用 T(n) 表示 n 个有序元素的二分查找算法的时间复杂度,那么
1)当 n = 1 时,需要进行一次比较,T(n) = O(1)。
2)当 n > 1 时,需要将特定元素和中间元素做比较,时间复杂度为 O(1)。如果比较不成功,则需要在前半部分或后半部分查找,问题的规模缩小了一半,时间复杂度变为 T(n / 2)。
当 n = 1 时,T(n) = O(1);当 n > 1 时,T(n) = T(n / 2) + O(1)。
3)当 n > 1 时,可以进行递归求解。
T(n) = T(n / 2) + O(1)
= T(n / 2 * 2) + 2O(1)
= T(n / 2 * 2 * 2) + 3O(1)
=……
= T(n / 2 的x次方) + xO(1)
递归最终的数据规模为1,也就是说,n / 2 的x次方 = 1。由于 n = 2 的x次方,因此 x = logn。
二分查找算法的时间复杂度为O(logn)


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
,涵盖了95%以上大数据知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1403
1403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









