







“refer_id”:“2”, – 外部营销渠道ID
“sourceType”: “promotion” – 来源类型
},
“err”: { --错误
“error_code”: “1234”, --错误码
“msg”: “***********” --错误信息
},
“ts”: 1585744374423 --跳入时间戳
}
启动日志:以启动为单位,及一次启动行为,生成一条启动日志。一条完整的启动日志包括一个启动记录,一个本次启动时的报错记录,以及启动时所处的环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
{
“common”: {
“ar”: “370000”,
“ba”: “Honor”,
“ch”: “wandoujia”,
“is_new”: “1”,
“md”: “Honor 20s”,
“mid”: “eQF5boERMJFOujcp”,
“os”: “Android 11.0”,
“sid”:“a1068e7a-e25b-45dc-9b9a-5a55ae83fc81”
“uid”: “76”,
“vc”: “v2.1.134”
},
“start”: {
“entry”: “icon”, --icon手机图标 notice 通知 install 安装后启动
“loading_time”: 18803, --启动加载时间
“open_ad_id”: 7, --广告页ID
“open_ad_ms”: 3449, – 广告总共播放时间
“open_ad_skip_ms”: 1989 – 用户跳过广告时点
},
“err”:{ --错误
“error_code”: “1234”, --错误码
“msg”: “***********” --错误信息
},
“ts”: 1585744304000
}
**服务器和JDK准备**
配置hadoop102、hadoop103、hadoop104三台主机(问题及Hadoop相关另行总结)
编写集群分发脚本xsync
1)xsync集群分发脚本
需求:循环复制文件到所有节点的相同目录下
需求分析:
①rsync命令原始拷贝
rsync -av /opt/module root@hadoop103:/opt/
②期望脚本:xsync要同步的文件名称
③说明:在/home/atguigu/bin这个目录下存放的脚本,atguigu用户可以在系统任何地方直接执行。
[atguigu@hadoop102 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/atguigu/.local/bin:/home/atguigu/bin
脚本实现:
①在用的家目录/home/atguigu下创建bin文件夹
[atguigu@hadoop102 ~]$ mkdir bin
②在/home/atguigu/bin目录下创建xsync文件,以便全局调用
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 ~]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e KaTeX parse error: Expected 'EOF', got '#' at position 23: … then #̲5. 获取父目录 …(cd -P $(dirname KaTeX parse error: Expected 'EOF', got '#' at position 19: …e); pwd) #̲6. 获取当前文件的名称 …(basename $file)
ssh $host “mkdir -p $pdir”
rsync -av
p
d
i
r
/
pdir/
pdir/fname
h
o
s
t
:
host:
host:pdir
else
echo $file does not exists!
fi
done
done
③修改脚本xsync具有执行权限
[atguigu@hadoop102 bin]$ chmod 777 xsync
④测试脚本
atguigu@hadoop102 bin]$ xsync xsync
**SSH无密登录配置**
说明:这里面只配置了hadoop102、hadoop103到其他主机的无密登录;因为hadoop102配置的是NameNode,hadoop103配置的是ResourceManager,都要求对其他节点无密访问。
1)hadoop102上生成公钥和私钥:
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id\_rsa(私钥)、id\_rsa.pub(公钥)。
2)将hadoop102公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
3)hadoop103上生成公钥和私钥:
[atguigu@hadoop103 .ssh]$ ssh-keygen -t rsa
4)拷贝操作亦同hadoop102
**JDK准备**
1)卸载三台节点上的现有JDK
[atguigu@hadoop102 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[atguigu@hadoop103 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
[atguigu@hadoop104 opt]# sudo rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps
操作批注:
(1)rpm -qa:表示查询所有已经安装的软件包
(2)grep -i:表示过滤时不区分大小写
(3)xargs -n1:表示一次获取上次执行结果的一个值
(4)rpm -e --nodeps:表示卸载软件
2)用XShell工具将JDK导入到hadoop102的****/********opt********/********software文件夹下面****
3)在Linux系统下的opt目录查看是否导入成功(ls)
4)解压JDK到****/opt/module目录下****(tar)
[atguigu@hadoop102 software]# tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
[atguigu@hadoop102 module]$ mv jdk1.8.0_212/ jdk-1.8.0
**5)配置JDK环境变量**
(1)新建/etc/profile.d/my\_env.sh文件(在module下sudo vim)
添加如下内容,然后保存(:wq)退出。
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk-1.8.0
export PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin
(2)让环境变量生效
[atguigu@hadoop102 software]$ source /etc/profile.d/my_env.sh
6)测试安装是否成功(java -version)
7)分发JDK(执行刚才的xsync脚本)
[atguigu@hadoop102 module]$ xsync /opt/module/jdk-1.8.0
8)分发环境变量配置文件
[atguigu@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
9)在hadoop103,hadoop104上分别执行source
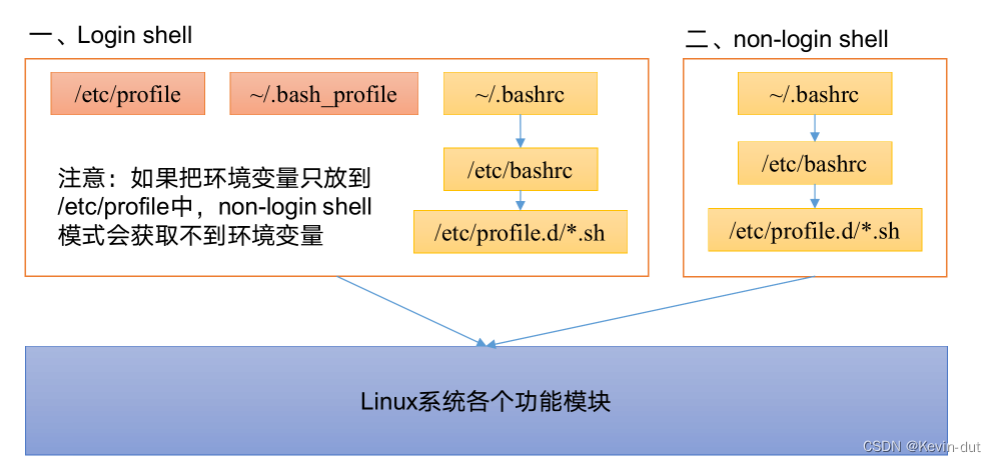
**环境变量配置说明**
Linux的环境变量可在多个文件中配置,如/etc/profile,/etc/profile.d/\*.sh,~/.bashrc,~/.bash\_profile等,下面说明上述几个文件之间的关系和区别。
bash的运行模式可以分为 **login shell 和 non-login shell**
(例如,我们通过终端,输入用户名、密码,登录系统之后,得到就是一个login shell。而当我们执行以下命令ssh hadoop103 command,在hadoop103执行command的就是一个non-login shell。)
这两种shell的主要区别在于,它们启动时会加载不同的配置文件,login shell启动时会加载/etc/profile,~/.bash\_profile,~/.bashrc。non-login shell启动时会加载~/.bashrc。
**数据模拟**
****1)将********application.yml********、********gmall-remake-mock-2023-02-17.jar********、********path.json********、********logback.xml********上传到hadoop********102********的/********opt/module/applog********目录下(需要 mkdir创建)****
2)配置文件
①application.yml文件:可以根据需求生成对应日期的用户行为日志
vim出文件后修改内容(照搬尚硅谷,太繁琐。。)
外部配置打开
logging.config: ./logback.xml
#http模式下,发送的地址
mock:
log:
type: “file” #“file” “http” “kafka” “none”
http:
url: “http://localhost:8090/applog”
kafka:
server: “hadoop102:9092,hadoop102:9092,hadoop102:9092”
topic: “topic_log”
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
url: jdbc:mysql://hadoop102:3306/gmall?characterEncoding=utf-8&allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=GMT%2B8
username: root
password: “000000”
driver-class-name: com.mysql.cj.jdbc.Driver
max-active: 20
test-on-borrow: true
mybatis-plus.global-config.db-config.field-strategy: not_null
mybatis-plus:
mapper-locations: classpath:mapper/*.xml
mybatis:
mapper-locations: classpath:mapper/*.xml
#业务日期, 并非Linux系统时间的日期,而是生成模拟数据的日期
mock.date: “2022-06-08”
日志是否写入数据库一份 写入z_log表中
mock.log.db.enable: 1
清空
mock.clear.busi: 1
清空用户
mock.clear.user: 0
批量生成新用户
mock.new.user: 0
#session次数
mock.user-session.count: 200
#设备最大值
mock.max.mid: 1000000
是否针对实时生成数据,若启用(置为1)则数据的 yyyy-MM-dd 与 mock.date 一致而 HH:mm:ss 与系统时间一致;若禁用则数据的 yyyy-MM-dd 与 mock.date 一致而 HH:mm:ss 随机分布,此处禁用
mock.if-realtime: 0
#访问时间分布权重
mock.start-time-weight: “10:5:0:0:0:0:5:5:5:10:10:15:20:10:10:10:10:10:20:25:30:35:30:20”
#支付类型占比 支付宝 :微信 :银联
mock.payment_type_weight: “40:50:10”
#页面平均访问时间
mock.page.during-time-ms: 20000
#错误概率 百分比
mock.error.rate: 3
#每条日志发送延迟 ms
mock.log.sleep: 100
#课程详情来源 用户查询,商品推广,智能推荐, 促销活动
mock.detail.source-type-rate: “40:25:15:20”
mock.if-cart-rate: 100
mock.if-favor-rate: 70
mock.if-order-rate: 100
mock.if-refund-rate: 50
#搜索关键词
mock.search.keyword: “java,python,多线程,前端,数据库,大数据,hadoop,flink”
#用户数据变化概率
mock.user.update-rate: 20
男女浏览品牌比重(11 品牌)
mock.tm-weight.male: “3:2:5:5:5:1:1:1:1:1:1”
mock.tm-weight.female: “1:5:1:1:2:2:2:5:5:5:5”
外连类型比重(5 种)
mock.refer-weight: “10:2:3:4:5”
线程池相关配置
mock.pool.core: 20
mock.pool.max-core: 100
②path.json, 用来配置访问路径,根据需求可以灵活配置用户点击路径
[
{“path”:[“start_app”,“home”, “search”, “good_list”,“good_detail”,“good_detail” ,“good_detail”,“cart”,“order”,“payment”,“mine”,“order_list”,“end”],“rate”:100 },
{“path”:[“start_app”,“home”, “good_list”,“good_detail”,“good_detail” ,“good_detail”,“cart”,“end”],“rate”:30 },
{“path”:[“start_app”,“home”, “activity1111”,“good_detail” ,“cart”,“good_detail”,“cart”,“order”,“payment”,“end”],“rate”:30 },
{“path”:[ “activity1111”,“good_detail” ,“activity1111” ,“good_detail”,“order”,“payment”,“end”],“rate”:200 },
{“path”:[ “start_app”,“home” ,“activity1111” ,“good_detail”,“order”,“payment”,“end”],“rate”:200 },
{“path”:[ “start_app”,“home” , “good_detail”,“order”,“payment”,“end”],“rate”:30 },
{“path”:[ “good_detail”,“order”,“payment”,“end”],“rate”:650 },
{“path”:[ “good_detail” ],“rate”:30 },
{“path”:[ “start_app”,“home”,“mine”,“good_detail” ],“rate”:30 },
{“path”:[ “start_app”,“home”, “good_detail”,“good_detail”,“good_detail”,“cart”,“order”,“payment”,“end” ],“rate”:200 },
{“path”:[ “start_app”,“home”, “search”,“good_list”,“good_detail”,“cart”,“order”,“payment”,“end” ],“rate”:200 }
]
③logback配置文件,可配置日志生成路径
<appender name="console_em" class="ch.qos.logback.core.ConsoleAppender">
<target>System.err</target>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<appender name="rollingFile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_HOME}/app.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern>
</rollingPolicy>
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<!-- 将某一个包下日志单独打印日志 -->
<logger name="com.atguigu.mock.util.LogUtil"
level="INFO" additivity="false">
<appender-ref ref="rollingFile" />
</logger>
<logger name="com.atguigu.gmallre.mock.task.UserMockTask" level="INFO" additivity="false" >
<appender-ref ref="console_em" />
</logger>
<root level="error" >
<appender-ref ref="console_em" />
<!-- <appender-ref ref="async-rollingFile" /> -->
</root>
3)生成日志
进入到/opt/module/applog路径,执行以下命令
[atguigu@hadoop102 applog]$ java -jar gmall-remake-mock-2023-02-17.jar test 100 2022-06-08
其中:
① 增加test参数为测试模式,只生成用户行为数据不生成业务数据。
② 100 为产生的用户session数一个session默认产生1条启动日志和5条页面方法日志。
③ 第三个参数为日志数据的日期,测试模式下不会加载配置文件,要指定数据日期只能通过命令行传参实现。
④ 三个参数的顺序必须与示例保持一致
⑤ 第二个参数和第三个参数可以省略,如果test后面不填写参数,默认为1000
在/opt/module/applog/log目录下查看生成日志
[atguigu@hadoop102 log]$ ll
集群日志生成脚本
(1)在/home/atguigu/bin目录下vim脚本lg.sh
(2)在脚本中编写如下内容
#!/bin/bash
echo "========== hadoop102 =========="
ssh hadoop102 "cd /opt/module/applog/; nohup java -jar gmall-remake-mock-2023-02-17.jar $1 $2 $3 >/dev/null 2>&1 &"
done
注:
①/opt/module/applog/为jar包及配置文件所在路径
②/dev/null代表Linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。
标准输入0:从键盘获得输入 /proc/self/fd/0
标准输出1:输出到屏幕(即控制台) /proc/self/fd/1
错误输出2:输出到屏幕(即控制台) /proc/self/fd/2
(3)修改脚本执行权限(chmod 777)
(4)将jar包及配置文件上传至hadoop103的/opt/module/applog/路径
(5)启动脚本
atguigu@hadoop102 module]$ lg.sh test 100
(6)分别在hadoop102、hadoop103的/opt/module/applog/log目录上查看生成的数据
[atguigu@hadoop102 log]$ ls
app.log
用户行为数据采集模块
用户行为日志数据通道:

环境准备
集群命令批量执行脚本xcall,vim后修改然后chmod777, 启动是$ xcall jps
#! /bin/bash
for i in hadoop102 hadoop103 hadoop104
do
echo --------- $i ----------
ssh $i "$*"
done
注:
jps 命令是 Java Virtual Machine Process Status Tool 的缩写,用于显示 Java 虚拟机(JVM)中正在运行的 Java 进程的信息。它通常用于识别在当前系统中正在运行的 Java 进程,以及它们的进程 ID(PID)和主类名。
jps 命令可以在命令行中直接运行,不需要任何参数。它会列出当前系统中正在运行的所有 Java 进程的信息,包括它们的 PID 和主类名。具体来说,jps 命令的输出包括以下信息:
- 进程 ID(PID):Java 进程的唯一标识符。
- 主类名(Main Class Name):启动 Java 进程时指定的主类名,即包含
main()方法的类。
jps 命令可以用于以下情况:
- 识别在系统中运行的 Java 进程,以便进行监控、调试或管理。
- 确定正在运行的 Java 进程的主类名,以便进一步分析或调试。
Hadoop安装
Zookeeper安装
Kafka安装
Flume安装
日志采集Flume
Apache Flume 是一个分布式、可靠且高可用的系统,用于收集、聚合和传输大量日志数据或事件数据到中心化数据存储中,如 Apache Hadoop 的 HDFS、Apache HBase、以及 Apache Kafka 等。它的主要作用是简化大规模数据的采集和传输过程,实现数据流的可靠传输,并提供了一套灵活的配置和可扩展的架构,使其能够适应不同类型和规模的数据采集需求。
按照规划,需要采集的用户行为日志存放在hadoop102,故需要在该节点配置日志采集Flume。日志采集Flume需要采集日志文件内容,并对日志格式(json)进行校验,然后将校验通过的日志发送到Kafka。↓
(注:
Flume 如何将采集的日志传输给 Kafka 的基本流程:
- 定义数据流配置: 首先,需要定义 Flume 的数据流配置,包括数据源、数据通道和数据目的地。数据源可以是各种数据来源,如日志文件、网络端口、消息队列等。数据通道用于在 Flume 内部缓存和传输数据。数据目的地则指定数据传输的最终目的地,如 Kafka、HDFS、HBase 等。
- 启动 Flume Agent: 根据定义的数据流配置,启动 Flume Agent。Flume Agent 是 Flume 的运行实例,负责接收、处理和传输数据。当 Agent 启动后,它会按照配置从数据源获取数据,并将数据传输到指定的目的地。
- (在Flume中使用KafkaChannel可省去这一步)配置 Kafka Sink: 在数据流配置中,需要配置一个 Kafka Sink,用于将数据传输到 Kafka。Kafka Sink 是 Flume 提供的一个插件,用于与 Kafka 交互并将数据写入 Kafka 的 Topic 中。在配置 Kafka Sink 时,需要指定 Kafka 的连接信息、Topic 名称等参数。
- 数据传输到 Kafka: 当 Flume Agent 运行时,它会从数据源获取数据,并通过配置的数据通道将数据传输到 Kafka Sink。Kafka Sink 将接收到的数据转换为 Kafka 的消息格式,并将消息写入指定的 Kafka Topic 中。
- 数据消费: 一旦数据写入 Kafka Topic,消费者可以使用 Kafka 提供的 API 或工具来消费这些数据。消费者可以订阅相应的 Topic,并实时获取到 Flume 传输的日志数据,进行后续的处理和分析。
通过以上流程,Flume 可以将采集的日志数据可靠地传输到 Kafka 中,实现数据的收集、传输和分发,为后续的数据处理和分析提供了可靠的数据来源。
)
此处可以选择Flume中TaildirSource和KafkaChannel组件,并配置日志校验拦截器。选择原因:
TaildirSource:
TaildirSource 是 Flume 提供的一个源(Source)组件,用于从文件系统中实时读取日志文件的内容,并将其发送到 Flume 的通道(Channel)中。它可以监视指定目录下的日志文件,不断地读取新增的日志内容,并将其转发给 Flume 的后续组件进行处理。TaildirSource 通常用于实时采集应用程序生成的日志数据。
TailDirSource相比ExecSource、SpoolingDirectorySource的优势。
TailDirSource:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传。
ExecSource可以实时搜集数据,但是在Flume不运行或者Shell命令出错的情况下,数据将会丢失。
SpoolingDirectorySource监控目录,支持断点续传。
Kafka********Channel
KafkaChannel 是 Flume 提供的一个通道(Channel)组件,用于与 Apache Kafka 集成,实现将数据从 Flume 传输到 Kafka 中。KafkaChannel 使用 Kafka 作为底层的数据存储和传输介质,将 Flume 接收到的数据写入 Kafka 的 Topic 中,以便后续的数据消费和处理。KafkaChannel 可以保证数据的可靠性和高吞吐量,适用于大规模的数据传输场景。
采用Kafka Channel,省去了Sink,提高了效率。
日志采集Flume关键配置如下:

日志采集Flume配置实操
1)创建Flume配置文件
在hadoop102节点的Flume的job目录下创建file_to_kafka.conf。(mkdir,vim)


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Flume 传输到 Kafka 中。KafkaChannel 使用 Kafka 作为底层的数据存储和传输介质,将 Flume 接收到的数据写入 Kafka 的 Topic 中,以便后续的数据消费和处理。KafkaChannel 可以保证数据的可靠性和高吞吐量,适用于大规模的数据传输场景。
采用Kafka Channel,省去了Sink,提高了效率。
日志采集Flume关键配置如下:
日志采集Flume配置实操
1)创建Flume配置文件
在hadoop102节点的Flume的job目录下创建file_to_kafka.conf。(mkdir,vim)
[外链图片转存中…(img-ly04jtwV-1714663602206)]
[外链图片转存中…(img-nXMnLjWR-1714663602207)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









