







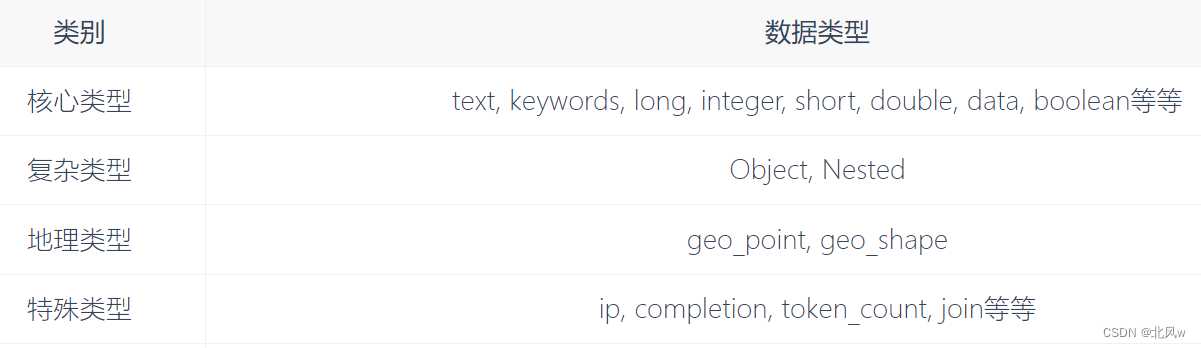
- 哪些字段包含数字,日期或地理位置。
- 是否应将文档中所有字段的值索引到catch-all _all字段中。
- 日期值的格式。
- 自定义规则以控制动态添加字段的映射。
映射是用于定义ES对索引中字段的存储类型、分词方式和是否存储等信息,就像数据库中的 schema ,描述了文档可能具有的字段或属性、每个字段的数据类型。只不过关系型数据库建表时必须指定字段类型,而ES对于字段类型可以不指定然后动态对字段类型猜测,也可以在创建索引时具体指定字段的类型
对字段类型根据数据格式自动识别的映射称之为动态映射(Dynamic mapping),我们创建索引时具体定义字段类型的映射称之为静态映射或显示映射(Explicit mapping)
为什么我们创建索引时需要建立静态映射而不使用动态映射?
通过对字段类型的了解我们知道有些字段需要明确定义的,例如某个字段是text类型还是keword类型差别是很大的,时间字段也许我们需要指定它的时间格式,还有一些字段我们需要指定特定的分词器等等。如果采用动态映射是不能精确做到这些的,自动识别常常会与我们期望的有些差异。
所以创建索引给的时候一个完整的格式应该是指定分片和副本数以及Mapping的定义
PUT my_index
{
"settings" : {
"number_of_shards" : 5,
"number_of_replicas" : 1
}
"mappings": {
"_doc": {
"properties": {
"title": { "type": "text" },
"name": { "type": "text" },
"age": { "type": "integer" },
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
}
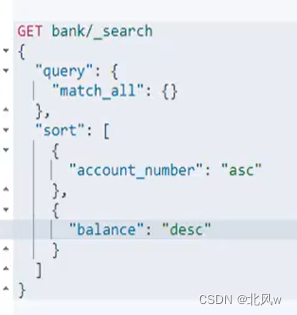
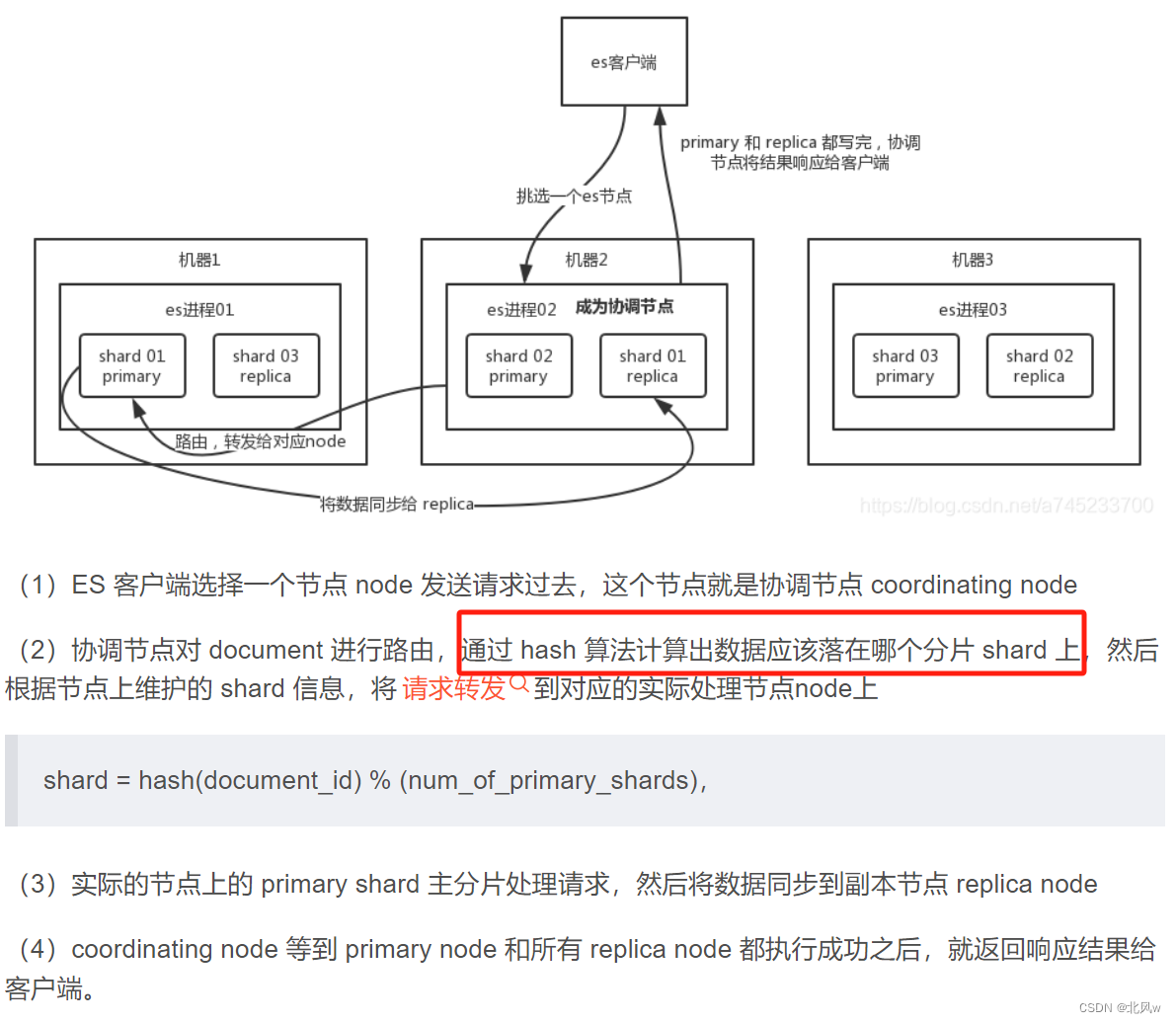
ES的两种查询方式
一个是通过使用 RESTrequestURl 发送搜索参数(uri+检索参数)

另一个是通过使用RESTrequestbody 来发送它们(uri请求体)
queryDSL查询语言
ES读取数据的详细流程
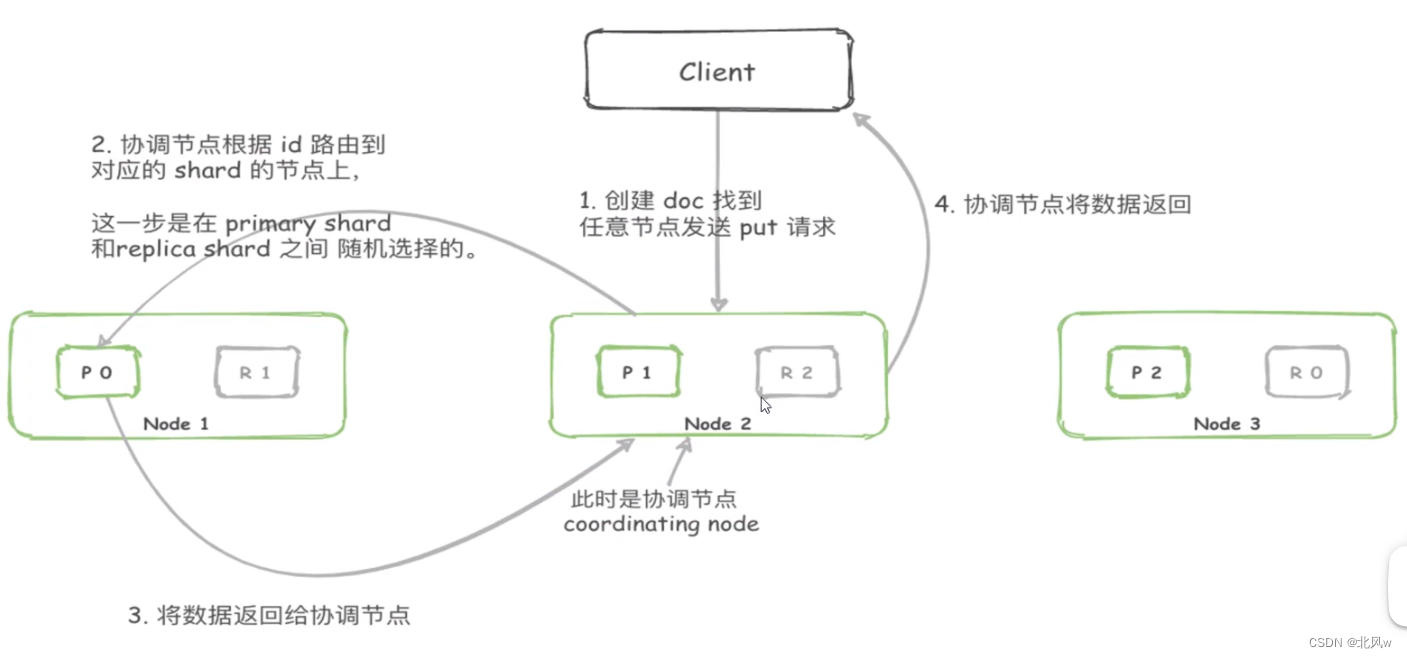
1、根据id值进行查找 GET /[index]/_doc/[_id]

1、转发给协调节点
2、协调节点找到对应id的数据分片,将请求转发给该分片对应的节点
3、节点处理请求并交给协调节点(唯一id所以不需要排序)
4、协调节点再转发给客户端
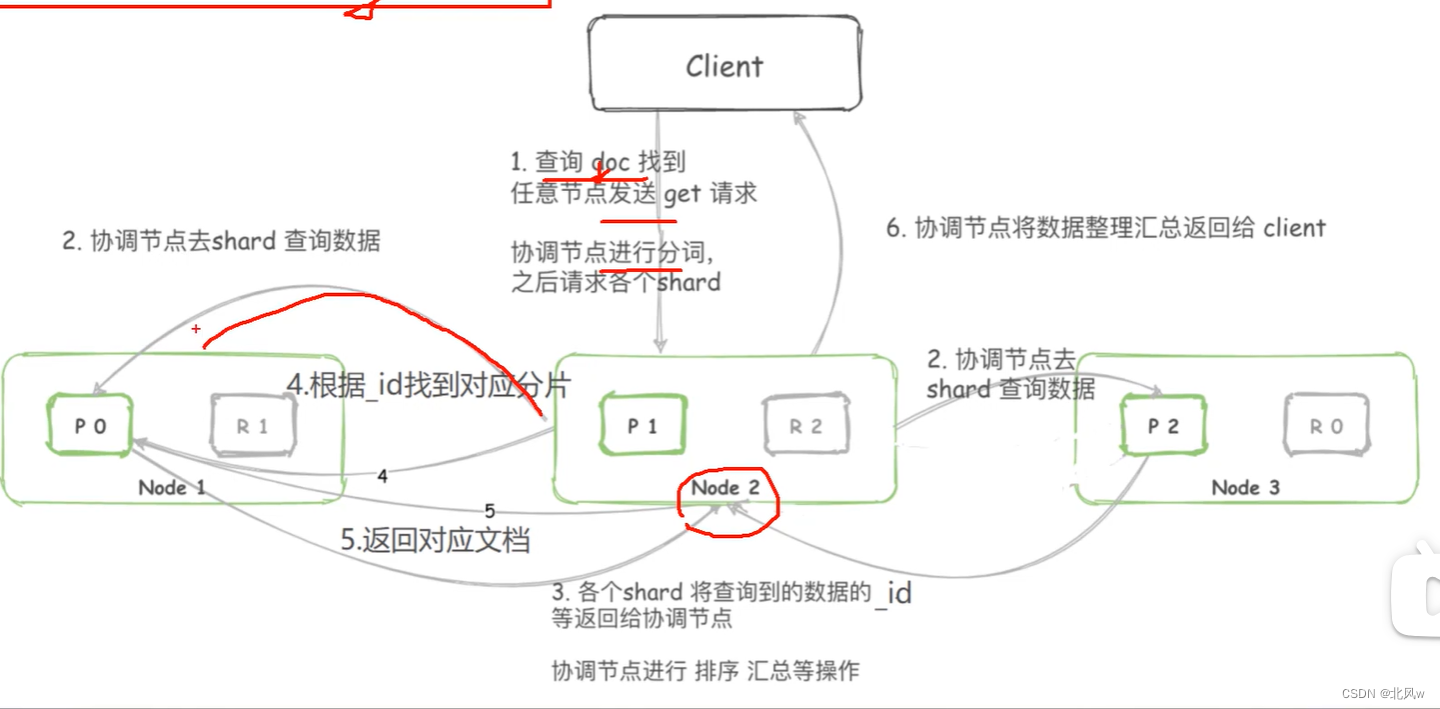
2、根据字段值检索对应的数据 GET /index]/ search?q=[field]: [value]
先找到对应的id,再查找对应的数据

1、转发给协调节点
2、协调节点进行分词等操作,向所有分片的节点查询数据
3、节点处理请求并将数据id交给协调节点
4、协调节点再根据id查找对应的分片找到对应的节点
5、各节点找到对应的数据给协调节点
6、此时可能存在多个id对应的数据(文档)存在该字段,需要进行排序汇总
4、协调节点再转发给客户端

ES写入数据的详细流程
ES的更新和删除流程

ElasticSearch 如何保证数据一致性
乐观并发控制 - 版本号
ES 数据并发冲突控制是基于的乐观锁和版本号的机制
一个document第一次创建的时候,它的_version内部版本号就是1;以后,每次对这个document执行修改或者删除操作,都会对这个_version版本号自动加1;哪怕是删除,也会对这条数据的版本号加1(假删除)。
客户端对es数据做更新的时候,如果带上了版本号,那带的版本号与es中文档的最新版本号一致才能修改成功,否则抛出异常。如果客户端没有带上版本号,首先会读取最新版本号才做更新尝试,这个尝试类似于CAS操作,可能需要尝试很多次才能成功。乐观锁的好处是不需要互斥锁的参与。
es节点更新之后会向副本节点同步更新数据(同步写入),直到所有副本都更新了才返回成功。

乐观并发控制 - 外部系统
版本号(version)只是其中一个实现方式,我们还可以借助外部系统使用版本控制,一个常见的设置是使用其它数据库作为主要的数据存储,使用 Elasticsearch 做数据检索, 这意味着主数据库的所有更改发生时都需要被复制到 Elasticsearch ,如果多个进程负责这一数据同步,你可能遇到类似于之前描述的并发问题。
如果你的主数据库已经有了版本号,或一个能作为版本号的字段值比如 timestamp,那么你就可以在 Elasticsearch 中通过增加 version_type=external到查询字符串的方式重用这些相同的版本号,版本号必须是大于零的整数, 且小于 9.2E+18(一个 Java 中 long 类型的正值)。
外部版本号的处理方式和我们之前讨论的内部版本号的处理方式有些不同, Elasticsearch 不是检查当前 _version 和请求中指定的版本号是否相同,而是检查当前_version 是否小于指定的版本号。如果请求成功,外部的版本号作为文档的新_version 进行存储。
外部版本号不仅在索引和删除请求是可以指定,而且在创建新文档时也可以指定。
例如,要创建一个新的具有外部版本号 5 的博客文章,我们可以按以下方法进行:
PUT /website/blog/2?version=5&version_type=external
{
"title": "My first external blog entry",
"text": "Starting to get the hang of this..."
}
在响应中,我们能看到当前的 _version 版本号是 5 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 5,
"created": true
}
现在我们更新这个文档,指定一个新的 version 号是 10 :
PUT /website/blog/2?version=10&version_type=external
{
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}
请求成功并将当前 _version 设为 10 :
{
"_index": "website",
"_type": "blog",
"_id": "2",
"_version": 10,
"created": false
}
如果你要重新运行此请求时,它将会失败,并返回像我们之前看到的同样的冲突错误,因为指定的外部版本号不大于 Elasticsearch 的当前版本号
近实时性搜索
索引是写入到磁盘的过程是这怎样的?是否是直接调 fsync 物理性地写入磁盘?
ES并没有每新增一条数据就增加一个段到磁盘上,而是采用延迟写的策略
每当有新增的数据时,就将其先写入到内存中,在内存和磁盘之间是文件系统缓存(FileSystem cache),当达到默认的时间(1秒钟)或者内存的数据达到一定量时,会触发一次刷新(Refresh),将内存中的数据生成到一个新的段(segment)上并缓存到文件缓存系统 上,稍后再被刷新到磁盘中并生成提交点。
内存使用的是ES的JVM内存,而文件缓存系统使用的是操作系统的内存。新的数据会继续的被写入内存,但内存中的数据并不是以段的形式存储的,因此不能提供检索功能。由内存刷新到文件缓存系统的时候会生成了新的段,并将段打开以供搜索使用,而不需要等到被刷新到磁盘。
在 Elasticsearch 中,写入和打开一个新段的轻量的过程叫做 refresh (即内存刷新到文件缓存系统)。 默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 Elasticsearch 是近实时搜索,因为文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。我们也可以手动触发 refresh,POST /_refresh 刷新所有索引,POST /nba/_refresh刷新指定的索引。
事务日志
虽然通过延时写的策略可以减少数据往磁盘上写的次数提升了整体的写入能力,但是我们知道文件缓存系统也是内存空间,属于操作系统的内存,只要是内存都存在断电或异常情况下丢失数据的危险。
为了避免丢失数据,Elasticsearch添加了事务日志(Translog),事务日志记录了所有还没有持久化到磁盘的数据。

- 一个新文档被索引之后,先被写入到内存中,但是为了防止数据的丢失,会追加一份数据到事务日志中。不断有新的文档被写入到内存,同时也都会记录到事务日志中。这时新数据还不能被检索和查询。
- 当达到默认的刷新时间或内存中的数据达到一定量后,会触发一次 refresh,将内存中的数据以一个新段形式刷新到文件缓存系统中并清空内存。这时虽然新段未被提交到磁盘,但是可以提供文档的检索功能且不能被修改。
- 随着新文档索引不断被写入,当日志数据大小超过512M或者时间超过30分钟时,会触发一次 flush。内存中的数据被写入到一个新段同时被写入到文件缓存系统,文件系统缓存中的数据通过 fsync 刷新到磁盘中,生成提交点,日志文件被删除,创建一个空的新日志。(fsync会确保一直到写磁盘操作结束才会返回,所以当你的程序使用这个函数并且它成功返回时,就说明数据肯定已经安全的落盘了)
通过这种方式当断电或需要重启时,ES不仅要根据提交点去加载已经持久化过的段,还需要工具Translog里的记录,把未持久化的数据重新持久化到磁盘上,避免了数据丢失的可能
段合并
为什么会有段合并?
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段然后合并查询结果,所以段越多,搜索也就越慢
Elasticsearch通过在后台定期进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档不会被拷贝到新的大段中。合并的过程中不会中断索引和搜索
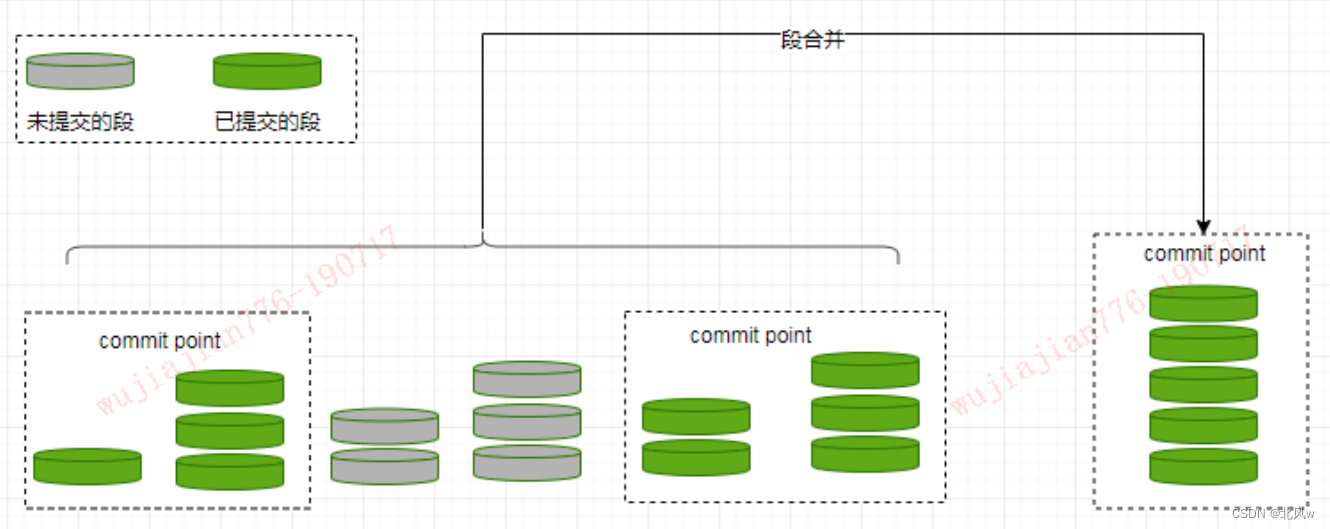
段合并在进行索引和搜索时会自动进行,合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中,这些段既可以是未提交的也可以是已提交的。合并结束后老的段会被删除,新的段被 flush 到磁盘,同时写入一个包含新段(已排除旧的被合并的段)的新提交点,新的段被打开可以用来搜索。
段合并的计算量庞大, 而且还要吃掉大量磁盘 I/O,段合并会拖累写入速率,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。
文档存储原理
文档是如何路由到分片中的
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
所有的文档 API( get 、 index 、 delete 、 bulk 、 update 以及 mget )都接受一个叫做 routing 的路由参数 ,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
822)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-J3iXd0R8-1712959221823)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









