






网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
这个实验主要是熟悉fork()、pipe()、read()、write()、getpid() 等函数的使用方法
流程:
- 在user/目录下,创建一个pingpong.c文件;
- 编写代码
#include "kernel/types.h"
#include "user/user.h"
//管道需要一个数组,来存放写入端(第二个元素)和读取端(第一个元素)
int main()
{
//自定义一个父子进程间发送的byte
char buf[] = {'a'};
//定义两个管道数组
int p1[2];
int p2[2];
int pid;
//创建管道
pipe(p1); //父进程发,子进程读
pipe(p2); //子进程发,父进程读
//注意这里的顺序,一定要先创建好管道在创建子进程
//因为子进程要copy父进程的所有内容,如果后创建管道会出现问题
int ret = fork();
if(ret == 0){ //子进程
//获取当前的pid(用来确认打印出来是子进程的pid)
pid = getpid();
//关闭p1的写入端、p2的读取端(这两个不需要用到,最好关闭)
close(p1[1]);
close(p2[0]);
//如果从p1管道读到了内容,长度为1,就说明收到了父进程的byte
if(read(p1[0],buf,1) == 1){
printf("%d: received ping\n", pid);
}
//向p2管道写入一个byte
write(p2[1], buf, 1);
exit(0);
}else{
pid = getpid();
//同上原因
close(p1[0]);
close(p2[1]);
//向管道p1写入一个byte
write(p1[1],buf,1);
//如果读到了p2管道的byte,说明父进程收到了子进程发送的byte
if(read(p2[0],buf,1) == 1) {
printf("%d: received pong\n", pid);
}
exit(0);
}
}
}
- 在Makefile文件里面UPROGS 添加 $U/_pingpong\;
UPROGS=\
$U/_cat\
$U/_echo\
$U/_forktest\
$U/_grep\
...
$U/_sleep\
$U/_pingpong\ //添加进Makefile
- 直接重新编译make qemu,或者用测试脚本测试,我这里就放一下用脚本测试的方法和结果;
jimmy@ubuntu:~/xv6-labs-2020$ ./grade-lab-util pingpong
make: 'kernel/kernel' is up to date.
== Test pingpong == pingpong: OK (1.4s)
primes函数实现
1.写一个素数筛选的程序,需要用到多进程和管道,这道题理解主要靠下面的图。
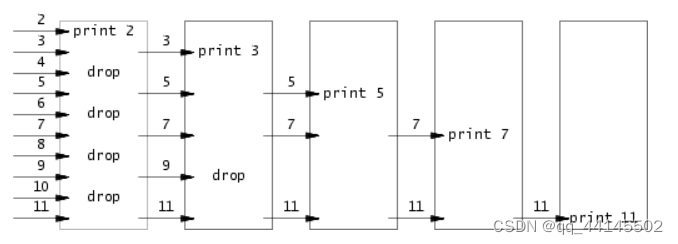
大概流程就是,输入2-11,然后发现2是素数,然后将能被2整除的素数全部筛掉。然后发现3是素数,在第二个阶段中将能被3整除的筛掉。
(牢记:每个进程的第一个数必定是素数)
2.根据上面的描述,需要写一个递归函数,这个函数要做的就是让父进程判断当前所有的数字中有没有能被第一个数整除的,如果不能整除,就用子进程把它送到下一次递归。然后利用这种链式结构,就像上面的图一样,完成筛选。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
void* child(int* p)
{
// 关闭上一个进程的写入端
close(p[1]);
int num;
//如果管道为空,说明已经筛选结束,直接关闭读取端,退出即可
if (read(p[0], &num, sizeof(num)) == 0)
{
close(p[0]);
exit(0);
}
//因为筛选规则,管道里面的第一个数一定是质数
printf("prime %d\n", num);
//创建一个管道用来写入这一轮被筛选的数据
int cp[2];
pipe(cp);
//将数据写入子进程中
if (fork() == 0) /
{
//一直递推,形成一种链式结构,让所有不能被当前质数整除的数据(在cp中)传递到下一个进程
child(cp);
}else { //处理从上一个进程收进来的管道数据
close(cp[0]);
int nnum;
//管道数据不会因为读而减少,因此子进程可以循环读,
//将所有不能被当前质数整除的数据传递到孙子进程的管道cp
while(read(p[0], &nnum, sizeof(nnum)))
// process 1 write an number, then process 2 read from the pipe
{
//不能被整除,就放到cp管道
if (nnum % num != 0)
{
write(cp[1], &nnum, sizeof(nnum));
}
}
//关闭cp的写入端
close(cp[1]);
wait(0);
}
exit(0);
}
int main(int argc, char const *argv[])
{
int p[2];
pipe(p);
//父进程初始化管道数据,然后用子进程来处理,并以此形成一种链式结构
if (fork() == 0) // child process
{
child(p);
}
else // parent process
{
close(p[0]);
for (int i = 2; i <= 35; i++)
{
write(p[1], &i, sizeof(i));
}
close(p[1]);
wait(0);
}
exit(0);
}
- 在Makefile文件里面UPROGS 添加 $U/_primes\;
UPROGS=\
$U/_cat\
$U/_echo\
$U/_forktest\
$U/_grep\
...
$U/_sleep\
$U/_pingpong\
$U/_primes\ //添加进Makefile
- 直接重新编译make qemu,或者用测试脚本测试,我这里就放一下用脚本测试的方法和结果;
jimmy@ubuntu:~/xv6-labs-2020$ ./grade-lab-util primes
make: 'kernel/kernel' is up to date.
== Test primes == primes: OK (1.0s)
find函数
1.这个函数主要是用来找文件的路径,这个和ls命令有很多类似的地方,比如要读取目录树,确定当前是目录还是文件等等。因此,参考ls函数的源码来修改即可.
注意:要求不要对’.‘或者’…'进行递归,而且需要使用strcmp()函数来比较两个字符串。
2.首先写一个函数basename,这个函数用来返回一个完整路径下的文件名。(用于这个路径下的文件是不是target文件)
例如:“/home/user/documents/file.txt” -> file.txt
char *basename(char *pathname) {
char *prev = 0;
//分割出以第一个'/'为结尾的字符串
//cur+1就索引到了'/'之后的第一个字符
char *curr = strchr(pathname, '/');
//循环找,直到找到最后的文件名然后返回
while (curr != 0) {
prev = curr;
curr = strchr(curr + 1, '/');
}
return prev;
}
3.接下来写一个find函数,这个函数用于递归查找所有目录里,包含目标字符串的文件,并且打印出来,这个函数就是在ls函数的基础上修改的。
void find(char * curr_path, char * target)
{
char buf[512], *p;
int fd;
struct dirent de;
struct stat st;
//当前路径下已经搜索完了或者文件不存在,就返回
if((fd = open(curr_path, 0)) < 0){
fprintf(2, "find: cannot open %s\n", curr_path);
return;
}
if(fstat(fd, &st) < 0){
fprintf(2, "find: cannot stat %s\n", curr_path);
close(fd);
return;
}
//判断当前类型
switch(st.type){
//如果是文件,说明搜索到底了
case T_FILE:;
char *file_name = basename(curr_path); //找到文件名
int match = 1;
//如果不是要找的文件名或者为空
if(file_name == 0 || strcmp(file_name+1, target) != 0){
match = 0;
}
//匹配成功,就把当前路径答应出来
if(match){
printf("%s\n",curr_path);
}
close(fd);
break;
//如果是一个目录,说明还要接着递归搜索
case T_DIR:
if(strlen(curr_path) + 1 + DIRSIZ + 1 > sizeof buf){
printf("find: path too long\n");
break;
}
strcpy(buf, curr_path);
p = buf+strlen(buf);
*p++ = '/';
while(read(fd, &de, sizeof(de)) == sizeof(de)){
if(de.inum == 0)
continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
if(stat(buf, &st) < 0){
printf("find: cannot stat %s\n", buf);
continue;
}
if(strcmp(buf+strlen(buf)-2, "/.") != 0 && strcmp(buf+strlen(buf)-3, "/..") != 0) {
find(buf, target); // 递归查找
}
}
break;
}
close(fd);
}
}
4.最后是主函数,只需要做一个参数数目判断,然后调用find函数即可。
int main(int argc, char* argv[])
{
if (argc != 3) {
fprintf(2, "usage: find [directory] [target filename]\n");
exit(1);
}
find(argv[1], argv[2]);
exit(0);
}
5.在Makefile文件里面UPROGS 添加 $U/_find\;
UPROGS=\
$U/_cat\
$U/_echo\
$U/_forktest\
$U/_grep\
...
$U/_sleep\
$U/_pingpong\
$U/_primes\
$U/_find\ //添加进Makefile
- 直接重新编译make qemu,或者用测试脚本测试,我这里就放一下用脚本测试的方法和结果;
jimmy@ubuntu:~/xv6-labs-2020$ ./grade-lab-util find
make: 'kernel/kernel' is up to date.
== Test find, in current directory == find, in current directory: OK (2.1s)
== Test find, recursive == find, recursive: OK (0.7s)
xargs函数
1.这个实验是写一个用来传参和执行命令的函数,主要有两个功能:一是可以实现对以’\n’为结尾的指令进行划分,然后执行,二是可以从管道获取其他命令(主要是指标准输入)传过来的参数。举个例子:
$ echo "1\n2" | xargs -n 1 echo line
xrags会将从管道将stdin输入"1\n2"拼接在echo line后:
$ echo line 1
$ \n
$ echo line 2
运行结果为:
$ line 1
$ line 2
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
接在echo line后:
$ echo line 1
$ \n
$ echo line 2
运行结果为:
$ line 1
$ line 2
[外链图片转存中...(img-7El8imAW-1715750367680)]
[外链图片转存中...(img-JspZ0K9d-1715750367680)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









