







环境:
- mybatis-plus
- easyexcel
- lambok
- mysql数据库
首先准备100万条数据,为了方便,我用mybatis-plus循环100万次插入同一条数据数据,(注意:此处要给每一条数据设置唯一不重复的主键,后面优化sql会用到索引)
//插入
@Autowired
private ExamItemService examItemService;
@Test
public void insert() {
for (int i = 0; i < 1000000; i++) {
ExamItem examItem = new ExamItem(i, 对象其他变量赋值);//可以多设置些属性,方便对比
examItemService.save(examItem);
}
这是数据库中的所有100万条数据

一次性导出所有数据
我们先来试一下一次性把100万条数据一次性全部导出到一个excel文件中。
//单次查询,全量导出
@Test
public void export() {
long beginTime = System.currentTimeMillis();
List list = examItemService.list();
long overQueryTime = System.currentTimeMillis();
String fileName = “写你自己准备存excel的文件夹路径,要提前创建好,否则会当成文件名放在工程的根目录下” + “一次性全部导出” + “.xlsx”;
EasyExcel.write(fileName, ExamItem.class).sheet(“一次性导出结果”).doWrite(list);
long endTime = System.currentTimeMillis();
System.out.println(“查询耗时:” + (overQueryTime - beginTime) / 1000D);
System.out.println(“导出耗时:” + (endTime - overQueryTime) / 1000D);
System.out.println(“总耗时:” + (endTime - beginTime) / 1000D);
}
| 总耗时:42.263 |
|---|
| 查询耗时:9.863 |
| 导出耗时:32.4 |
可以看出,主要的耗时都集中在导出中。
注:excel2007版本,即后缀名为.xlsx的excel文件,一个文件最多能存储104万行数据,所以100万条数据已经比较接近excel的极限值了,所以打开加载可能要稍等下。
下图为jconsole工具在进程运行期间的参数展示,可以看出内存几乎和CPU占有率都挺高的
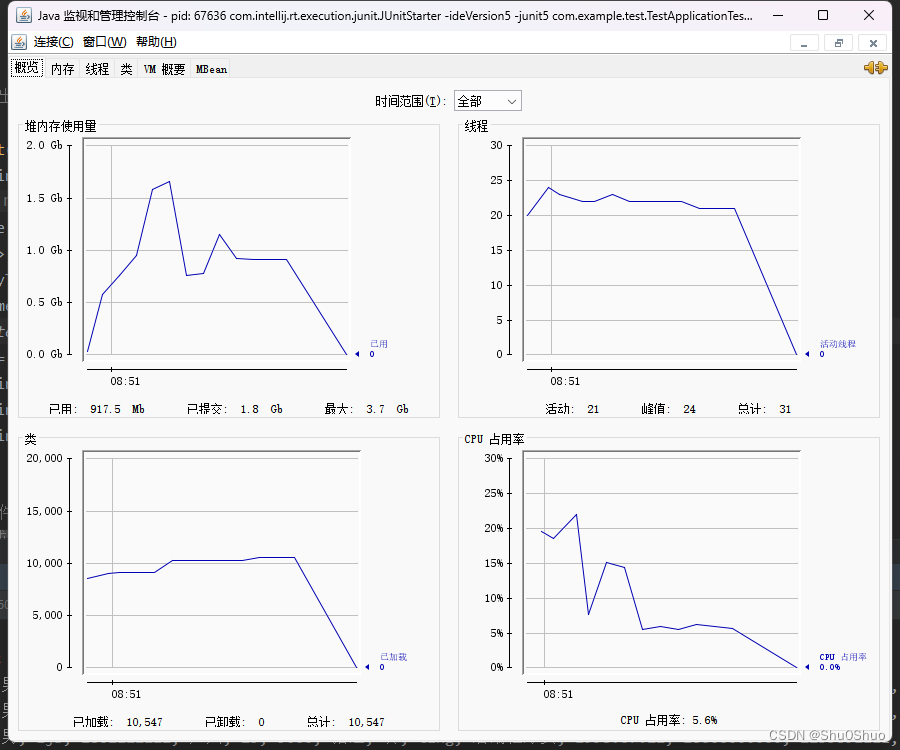
把所有数据导出到十个文件中
多次查询,多个文件,单次写入,100万条数据,分成10个文件,每个文件的10万条数据都是单次写入。即每次都查出十万条数据导出到一个excel中。
public void export4() {
long t1 = System.currentTimeMillis();
long query = 0;
long write = 0;
for (int i = 0; i < 10; i++) {
long t3 = System.currentTimeMillis();
String fileName = “写你自己准备存excel的文件夹路径” + “单次写入” + i + “.xlsx”;
ExcelWriter excelWriter = EasyExcel.write(fileName, ExamItem.class).build();
WriteSheet writeSheet = EasyExcel.writerSheet(“单次写入”).build();
QueryWrapper queryWrapper = new QueryWrapper<>();
// select * from exam_item limit i100000,100000(从i100000开始,查100000条数据)
queryWrapper.last("limit " + i * 100000 + “,100000”);
List memberInfos = examItemService.list(queryWrapper);
long t4 = System.currentTimeMillis();
excelWriter.write(memberInfos, writeSheet);
excelWriter.finish();
long t5 = System.currentTimeMillis();
System.out.println(“第”+i+“个文件的查询时间:” + (t4-t3) / 1000D);
System.out.println(“第”+i+“个文件的写入时间:” + (t5-t4) / 1000D);
query += (t4-t3);
write += (t5-t4);
}
long t2 = System.currentTimeMillis();
System.out.println(“耗时:” + (t2 - t1) / 1000D);
System.out.println(“总查询耗时:” + query / 1000D);
System.out.println(“总写耗时:” + write / 1000D);
}
| 耗时:33.145 |
|---|
| 总查询耗时:7.037 |
| 总写耗时:26.108 |
其实和一次性全部导出的区别就在于用做了十次循环,每次循环单独做数据查询、文件导出。
观察内存和CPU的变化,可以发现堆内存下降到了1G左右,CPU占有率显著下降。

分成十个文件,每个文件分十次写入
多次查询,多个文件,多次写入。100万条数据,分成10个文件,每个文件的10万条数据分10次写入,每次写入1万条数据
public void export5() {
long t1 = System.currentTimeMillis();
long query = 0;
long write = 0;
for (int i = 0; i < 10; i++) {
String fileName = “写你自己准备存excel的文件夹路径” + “分页导出” + i + “.xlsx”;
ExcelWriter excelWriter = EasyExcel.write(fileName, ExamItem.class).build();
WriteSheet writeSheet = EasyExcel.writerSheet(“分页导出”).build();
for (int j = 0; j < 10; j++) {
long t3 = System.currentTimeMillis();
// 分页去数据库查询数据 这里可以去数据库查询每一页的数据
QueryWrapper queryWrapper = new QueryWrapper<>();
queryWrapper.last("limit " + (10 * i + j) * 10000 + “,10000”);
List memberInfos = examItemService.list(queryWrapper);
long t4 = System.currentTimeMillis();
excelWriter.write(memberInfos, writeSheet);
long t5 = System.currentTimeMillis();
System.out.println(“一万条数据第”+i+“个文件的第”+j+“次查询时间:” + (t4-t3) / 1000D);
System.out.println(“一万条数据第”+i+“个文件的第”+j+“次写入时间:” + (t5-t4) / 1000D);
query += (t4-t3);
write += (t5-t4);
}
excelWriter.finish();
}
long t2 = System.currentTimeMillis();
System.out.println(“总耗时:” + (t2 - t1) / 1000D);
System.out.println(“总查询耗时:” + query / 1000D);
System.out.println(“总写耗时:” + write / 1000D);
}
改动就是改成了两层循环,外层循环负责写入十次文件,内层循环负责每个文件写十次,每次写入1万条数据。
| 总耗时:55.701 |
|---|
| 总查询耗时:29.27 |
| 总写耗时:16.3 |
写入时间进一步减少,但是查询时间再增加,总时间反而变的更多了。
而堆内存的使用量进一步降低,CPU基本没有明显变化。
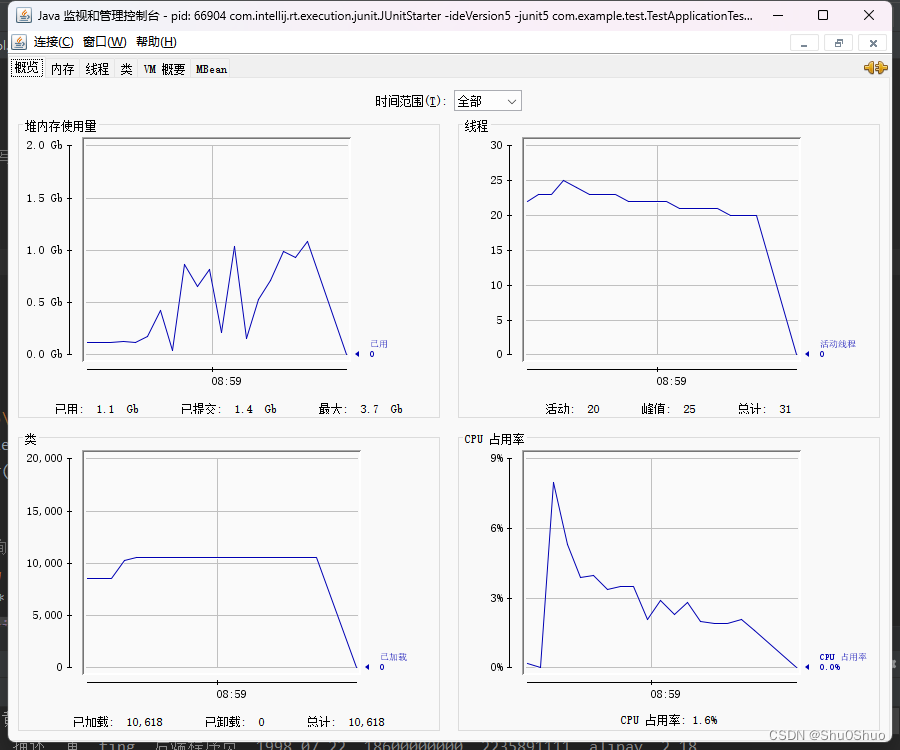
分成十个文件,每个文件分十次写入
easyexcel的官网给的简单写代码里有这么一行注释。
//在数据量不大的情况下可以使用(5000以内,具体也要看实际情况),数据量大参照 重复多次写入
于是有了思考,上面的方法虽然CPU占用很平稳,也不高,但是总时长却变长了。是不是因为easyexcel的单次写入性能性价比最高极限是5000条数据,所以,我们尝试把每次写入1万条数据再次拆分,变成每次写入5000条。
多次查询,多个文件,多次写入。100万条数据,分成10个文件,每个文件的10万条数据分20次写入,每次写入5千条数据
public void export6() {
long t1 = System.currentTimeMillis();
long query = 0;
long write = 0;
for (int i = 0; i < 10; i++) {
String fileName = “写你自己准备存excel的文件夹路径” + “分页导出-5000-” + i + “.xlsx”;
ExcelWriter excelWriter = EasyExcel.write(fileName, ExamItem.class).build();
WriteSheet writeSheet = EasyExcel.writerSheet(“分页导出”).build();
for (int j = 0; j < 20; j++) {
long t3 = System.currentTimeMillis();
// 分页去数据库查询数据 这里可以去数据库查询每一页的数据
QueryWrapper queryWrapper = new QueryWrapper<>();
queryWrapper.last("limit " + (20 * i + j) * 5000 + “,5000”);
List memberInfos = examItemService.list(queryWrapper);
long t4 = System.currentTimeMillis();
excelWriter.write(memberInfos, writeSheet);
long t5 = System.currentTimeMillis();
System.out.println(“一万条数据第”+i+“个文件的第”+j+“次查询时间:” + (t4-t3) / 1000D);
System.out.println(“一万条数据第”+i+“个文件的第”+j+“次写入时间:” + (t5-t4) / 1000D);
query += (t4-t3);
write += (t5-t4);
}
excelWriter.finish();
}
long t2 = System.currentTimeMillis();
System.out.println(“总耗时:” + (t2 - t1) / 1000D);
System.out.println(“总查询耗时:” + query / 1000D);
System.out.println(“总写耗时:” + write / 1000D);
}
| 总耗时:82.946 |
|---|
| 总查询耗时:55.168 |
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

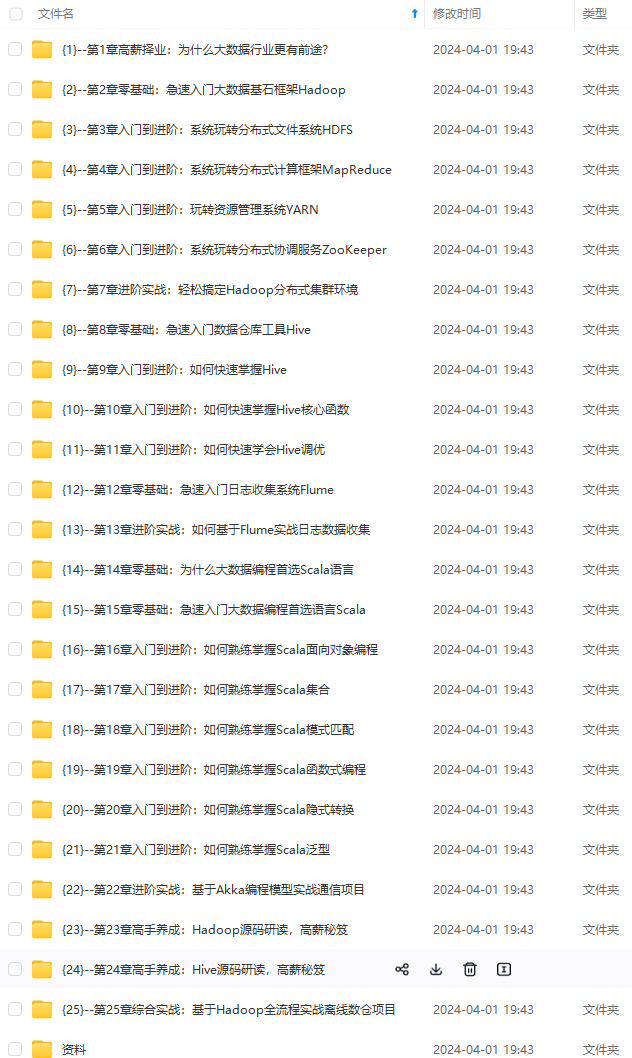
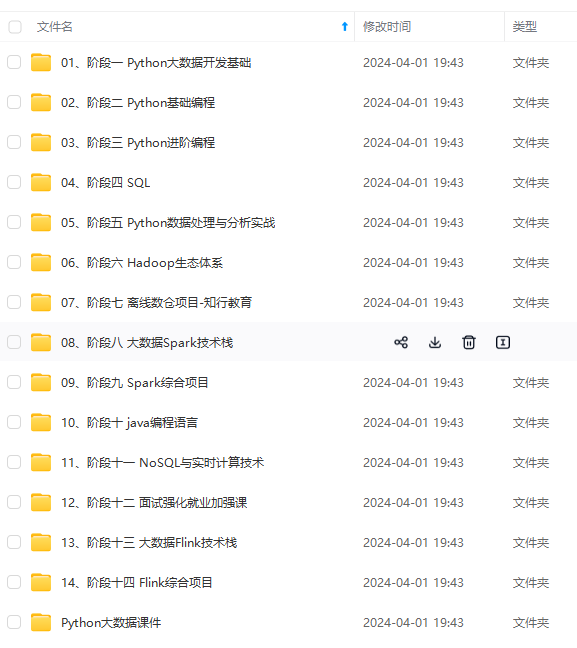

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

转存中…(img-NMB0kuHX-1712515634323)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-ZXfqBeYQ-1712515634323)]















 1706
1706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









