







+ **监控需求**
- 问题:数据量越来越大,机器数量越来越多,如何保证所有服务器稳定的的运行,确保所有业务不掉线?
* 资源:CPU、内存、磁盘、网络
* 阈值:80%
- 解决:高效的监控系统可以对运维数据进行分析整理,将运维工作透明化可视化,方便运维人员及时找出问题,保障**系统稳定运行,提高运维效率**,满足不同业务需求,**适用不同服务器场景**,也是决定运维成本和效率的重要因素
- 需求
* **覆盖式监控**:监控所有机器、所有服务的运行
* **统一监控内容**:CPU、内存、磁盘、网络IO
* **分离告警和显示**:实时的监控机器负载,程序运行,并针对不同业务实现不同方式的告警和报表
+ **常见工具**
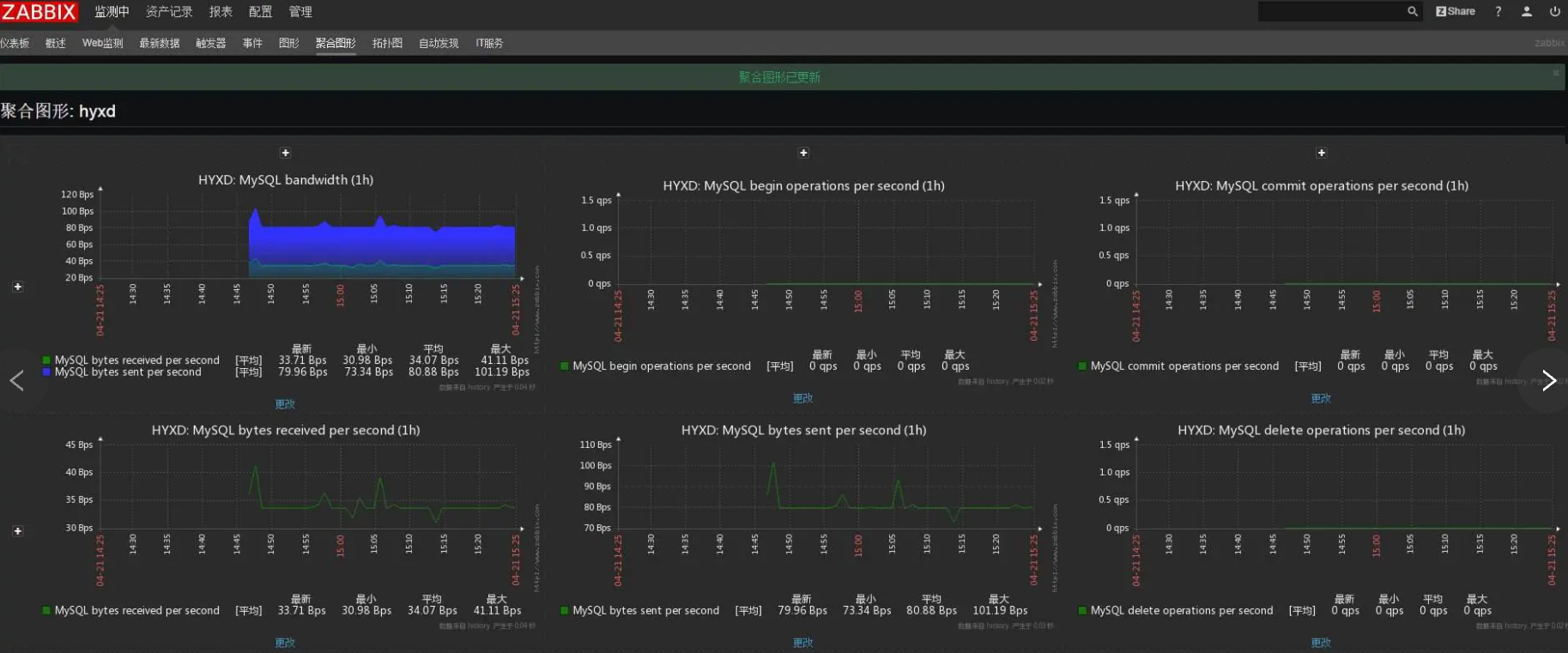
- **zabbix**
```
基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案
zabbix能监视各种网络参数,保证服务器系统的安全运营
提供灵活的通知机制以让系统管理员快速定位/解决存在的各种问题
```
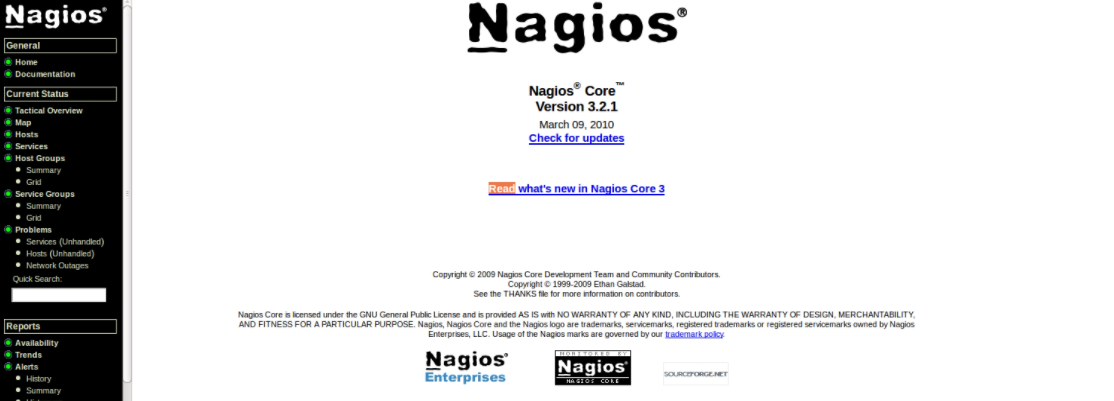
- **Nagios**
```
一款开源的免费网络监视工具,能有效监控Windows、Linux和Unix的状态,交换机路由器等网络设备,打印机等
在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知
```
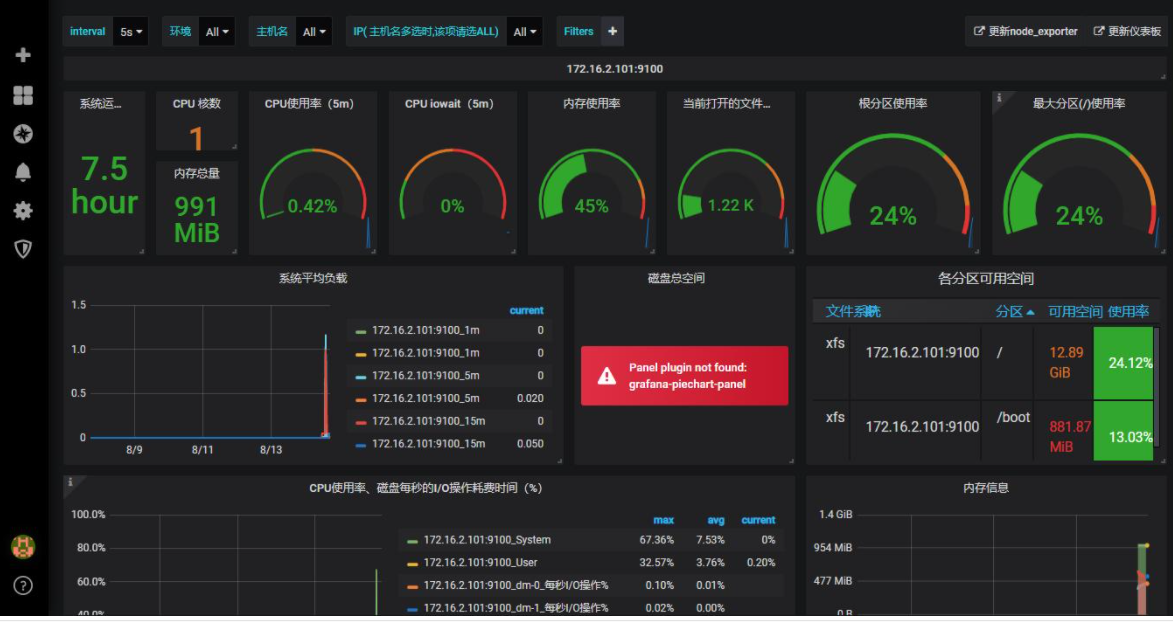
- **Prometheus**
```
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB),它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。
2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
```
-
小结
- 了解服务器性能监控需求及常见监控工具

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**














 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









