






网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
bool HeapEmpty(Heap* hp);
// TopK问题:找出N个数里面最大/最小的前K个问题。
// 比如:未央区排名前10的泡馍,西安交通大学王者荣耀排名前10的韩信,全国排名前10的李白。等等问题都是Topk问题,
// 需要注意:
// 找最大的前K个,建立K个数的小堆
// 找最小的前K个,建立K个数的大堆
void PrintTopK(int* a, int n, int k);
void TestTopk();
//打印堆
void HeapPrint(Heap* hp);
**Heap.c**
#include “Heap.h”
// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n)
{
assert(hp);
assert(a);
hp->_a = NULL;
hp->_capacity = hp->_size=0;
for (int i = 0; i < n; i++)
{
HeapPush(hp, a[i]);
}
}
//堆的销毁
void HeapDestory(Heap* hp)
{
assert(hp);
free(hp->_a);
hp->_a = NULL;
hp->_capacity = hp->_size =0;
}
//交换
void swap(HPDataType* p, HPDataType* c)
{
HPDataType temp = *p;
*p = *c;
*c = temp;
}
//向上调整
void AdjustUp(HPDataType* a, HPDataType child)
{
assert(a);
HPDataType parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
swap(&a[parent], &a[child]);
child=parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
if (hp->_capacity == hp->_size)
{
HPDataType NewCapacity = hp->_capacity == 0 ? 4 : 2hp->_capacity;
HPDataType tem = (HPDataType*)realloc(hp->_a, sizeof(HPDataType)*NewCapacity);
if (tem == NULL)
{
perror(“realloc fail”);
exit(-1);
}
hp->_a = tem;
hp->_capacity = NewCapacity;
}
hp->_a[hp->_size++] = x;
AdjustUp(hp->_a, hp->_size - 1);
}
//打印堆
void HeapPrint(Heap* hp)
{
for (int i = 0; i < hp->_size; ++i)
{
printf(“%d “, hp->_a[i]);
}
printf(”\n”);
}
//向下调整
void AdjustDown(HPDataType* a, HPDataType n, HPDataType parent)
{
assert(a);
HPDataType minchild = 2*parent+1;
while (minchild < n)
{
if (minchild + 1 < n&&a[minchild + 1]<a[minchild])
{
minchild++;
}
if (a[parent]>a[minchild])
{
swap(&a[parent], &a[minchild]);
parent = minchild;
minchild = 2 * parent + 1;
}
else
break;
}
}
// 堆的删除
void HeapPop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
swap(&hp->_a[0], &hp->_a[hp->_size-1]);
hp->_size--;
AdjustDown(hp->_a, hp->_size, 0);
}
// 堆的判空
bool HeapEmpty(Heap* hp)
{
assert(hp);
return hp->_size==0;
}
// 取堆顶的数据
HPDataType HeapTop(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
return hp->_a[0];
}
// 堆的数据个数
int HeapSize(Heap* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
return hp->_size;
}
Test.c
#define _CRT_SECURE_NO_WARNINGS
#include “Heap.h”
//测试
void testHeap()
{
HPDataType a[4] = { 1, 5, 7, 8 };
Heap hp;
HeapCreate(&hp,a, 4);
HeapPush(&hp,15);
HeapPush(&hp, 17);
HeapPrint(&hp);
HeapPop(&hp);
HeapPrint(&hp);
}
int main()
{
testHeap();
return 0;
}
#### 堆的应用
**排序**
通过上面对向上调整和向下调整的时间复杂度进行对比,我们发现向下调整是更加节省时间,我们选择使用向下调整建堆。那么在升序或者降序的时候我们该选择建大堆还是建小堆呢?

当我们以为用小根堆然后进行对它排序会更加节约时间,实际上我们发现是走不通的。所以我们应该换种思路:
**建堆**
>
> 升序:建大堆 降序:建小堆
>
>
>
利用堆删除思想来进行排序:
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
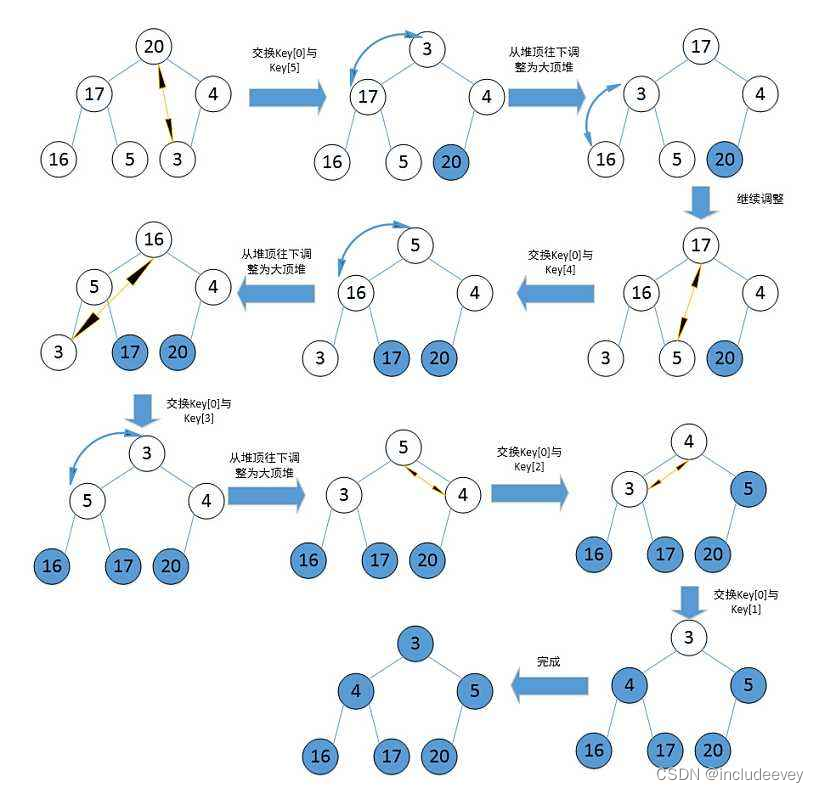
**实现代码**
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <assert.h>
void swap(int* p, int* c)
{
int temp = *p;
p = c;
c = temp;
}
void AdjustUp(int a, int child)
{
assert(a);
int parent = (child - 1) / 2;
while (child>0)
{
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void AdjustDown(int a, int n, int parent)
{
assert(a);
int minchild = 2parent+1;
while (minchild < n)
{
if (minchild + 1 < n && a[minchild] > a[minchild + 1])
{
minchild++;
}
if (a[minchild] < a[parent])
{
swap(&a[minchild], &a[parent]);
parent = minchild;
minchild = 2 * parent + 1;
}
else
break;
}
}
// 对数组进行堆排序
void HeapSort(int* a, int n)
{
向上建小根堆
//for (int i = 0; i <n; i++)
//{
// AdjustUp(a, n-1);
//}
//向下建立小根堆
for (int i = (n - 1-1) / 2; i >=0 ; i--)
{
AdjustDown(a, n,i);
}
//如何选次小
//升序 --建大堆 第一个与最后一个交换 把最后一个不看成堆里的 向下调整
//降序 --建小堆
int i = 1;
while (i < n)
{
swap(&a[0], &a[n-i]);
AdjustDown(a, n-i, 0);
i++;
}
}
int main()
{
int arr[] = { 1, 51, 31, 4, 8, 6, 78,14,16,78 };
HeapSort(arr,sizeof(arr)/sizeof(int));
int len = sizeof(arr) / sizeof(int);
for (int i = 0; i < len; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
演示结果:

#### TOP-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前1 0名、世界500强、富豪榜、游戏中前1 00的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能 数据都不能一下子全部加载到内存中)。
最佳的方式就是用堆来解决,基本思路如下:
1 . 用数据集合中前K个元素来建堆 前k个最大的元素,则建小堆 前k个最小的元素,则建大堆
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素

**实现代码**
#define _CRT_SECURE_NO_WARNINGS
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
void swap(int* p, int* c)
{
int temp = *p;
*p = c;
c = temp;
}
void AdjustUp(int a, int child)
{
assert(a);
int parent = (child - 1) / 2;
while (child>0)
{
if (a[child] < a[parent])
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void AdjustDown(int a, int n, int parent)
{
assert(a);
int minchild = 2 * parent + 1;
while (minchild < n)
{
if (minchild + 1 < n&&a[minchild] > a[minchild + 1])
{
minchild++;
}
if (a[minchild] < a[parent])
{
swap(&a[minchild], &a[parent]);
parent = minchild;
minchild = 2 * parent + 1;
}
else
break;
}
}
// 对数组进行堆排序
void HeapSort(int* a, int n)
{
向上建小根堆
//for (int i = 0; i <n; i++)
//{
// AdjustUp(a, n-1);
//}
//向下建立小根堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
//如何选次小
//升序 --建大堆 第一个与最后一个交换 把最后一个不看成堆里的 向下调整
//降序 --建小堆
int i = 1;
while (i < n)
{
swap(&a[0], &a[n - i]);
AdjustDown(a, n - i, 0);
i++;
}
}
void KOP_K(int* a, int n,int k)
{
//新建一个堆
int* heap = (int*)malloc(sizeof(int)*k);
if (heap == NULL)
{
perror(“malloc fail”);
exit(-1);
}
//
for (int i = 0; i <k; i++)
{
heap[i] = a[i];
}
for (int i = k; i < n; i++)
{
if (a[i]>heap[0])
{
heap[0] = a[i];
AdjustDown(heap, k, 0);
}
}
for (int i = 0; i < k; ++i)
{
printf("%d ", heap[i]);
}
free(heap);
heap = NULL;
}
int main()
{
int arr[] = { 1, 51, 31, 4, 8, 6, 78, 14, 16, 78 };
int len = sizeof(arr) / sizeof(int);
HeapSort(arr,len );
int k = 3;
KOP_K(arr,len,k);
return 0;
}
演示结果:

### 二叉树链式结构的实现
#### 前置说明
在学习二叉树的基本操作前,需先要创建一棵二叉树,然后才能学习其相关的基本操作。由于现在大家对二 叉树结构掌握还不够深入,为了降低大家学习成本,此处手动快速创建一棵简单的二叉树,快速进入二叉树 操作学习,等二叉树结构了解的差不多时,我们反过头再来研究二叉树真正的创建方式。
BTNode* CreateTree()
{
BTNode* n1 = (BTNode*)malloc(sizeof(BTNode));
assert(n1);
BTNode* n2 = (BTNode*)malloc(sizeof(BTNode));
assert(n2);
BTNode* n3 = (BTNode*)malloc(sizeof(BTNode));
assert(n3);
BTNode* n4 = (BTNode*)malloc(sizeof(BTNode));
assert(n4);
BTNode* n5 = (BTNode*)malloc(sizeof(BTNode));
assert(n5);
BTNode* n6 = (BTNode*)malloc(sizeof(BTNode));
assert(n6);
BTNode* n7 = (BTNode*)malloc(sizeof(BTNode));
assert(n7);
n1->_data = 1;
n2->_data = 2;
n3->_data = 3;
n4->_data = 4;
n5->_data = 5;
n6->_data = 6;
n7->_data = 7;
n1->_left = n2;
n1->_right = n4;
n2->_left = n3;
n2->_right = NULL;
n4->_left = n5;
n4->_right = n6;
n3->_left = NULL;
n3->_right = NULL;
n5->_left = NULL;
n5->_right = NULL;
n6->_left = NULL;
n6->_right = NULL;
n3->_right = n7;
n7->_left = NULL;
n7->_right = NULL;
return n1;
}
#### 二叉树的遍历
学习二叉树结构,最简单的方式就是遍历。所谓二叉树遍历(Traversal)是按照某种特定的规则,依次对二叉 树中的节点进行相应的操作,并且每个节点只操作一次。访问结点所做的操作依赖于具体的应用问题。 遍历是二叉树上最重要的运算之一,也是二叉树上进行其它运算的基础。
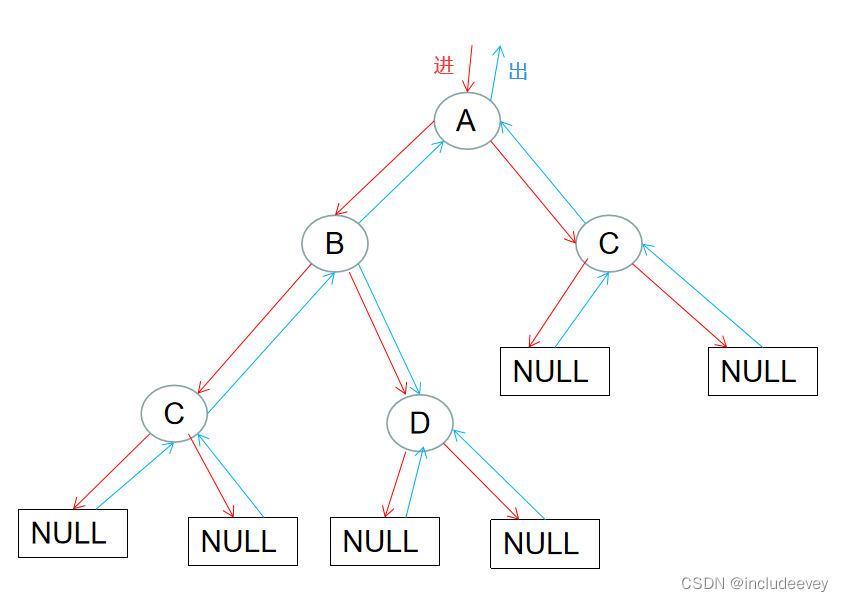
**前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点的操作发生在遍历其左右子树之前。**

**中序遍历(Inorder Traversal)——访问根结点的操作发生在遍历其左右子树之中(间)。**

**后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。**
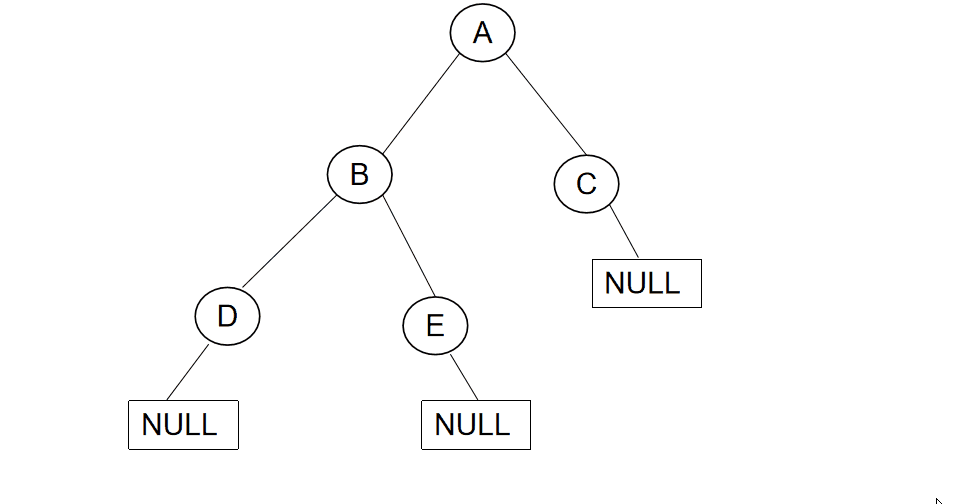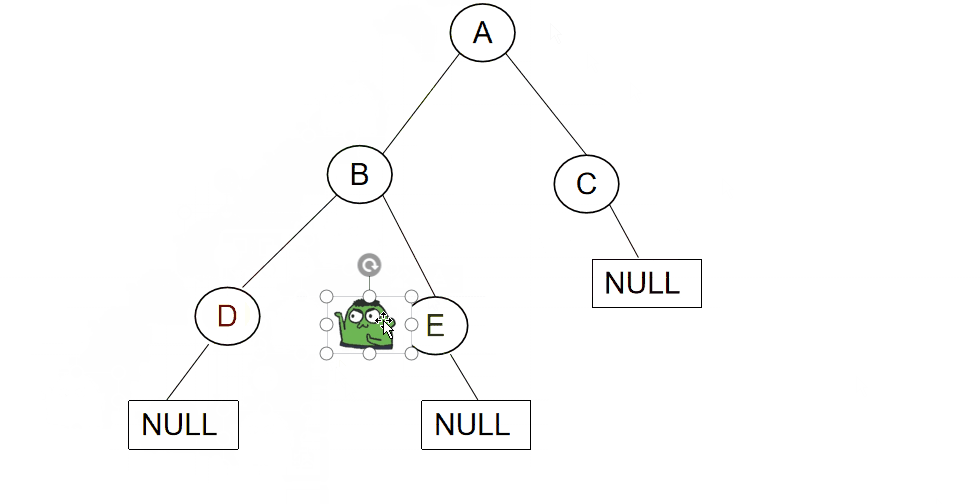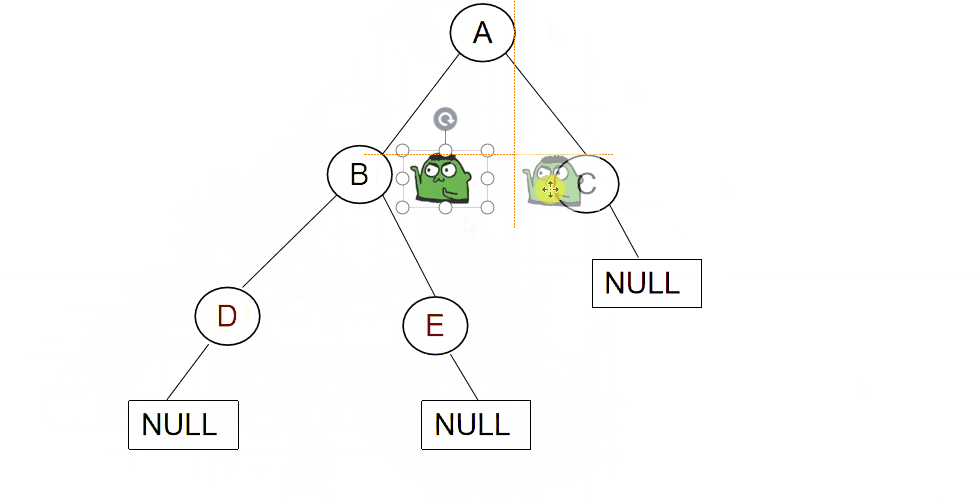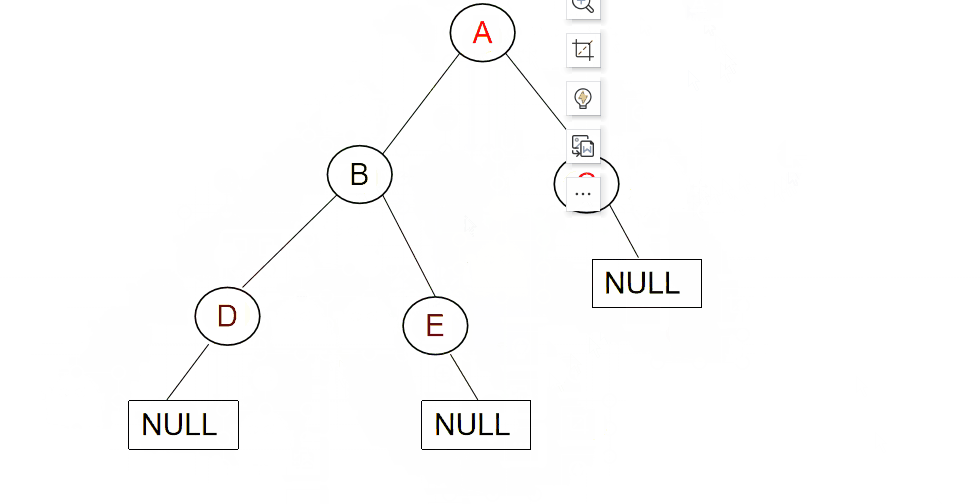
由于被访问的结点必是某子树的根,所以N(Node)、 L(Left subtree)和R(Right subtree)又可解释为 根、根的左子树和根的右子树。 NLR、 LNR和LRN分别又称为先根遍历、中根遍历和后根遍历。
>
> // 二叉树前序遍历
>
>
> void PreOrder( BTNode\* root ) ;
>
>
> // 二叉树中序遍历
>
>
> void InOrder( BTNode\* root ) ;
>
>
> // 二叉树后序遍历
>
>
> void PostOrder( BTNode\* root ) ;
>
>
>
**前序遍历递归图解:**
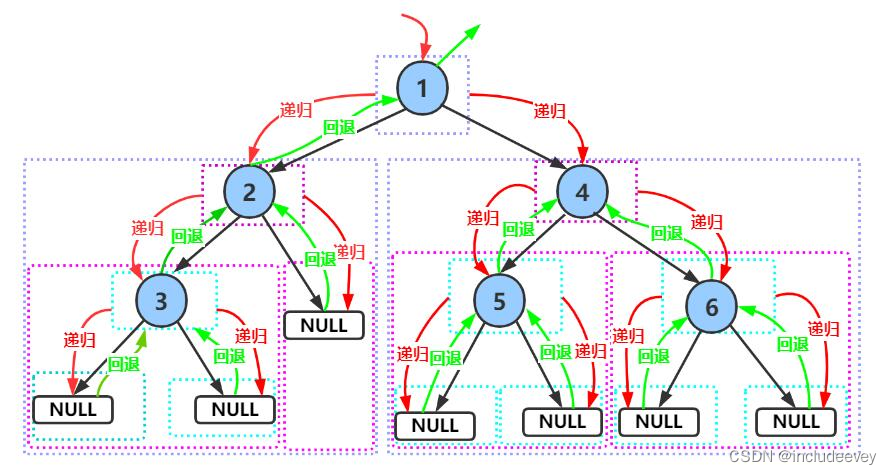

#### 层序遍历
层序遍历最主要的通过队列(先进先出)的方式进行遍历,通过上一层的节点出的时候带入下一层节点。

>
> // 层序遍历
>
>
> void LevelOrder( BTNode\* root ) ;
>
>
>
#### 判断二叉树是否是完全二叉树
这里我们还是通过层序遍历进行判断,通过一层一层的走,遇到空之后,后续层序不能有非空,如果有非空就不是完全二叉树。
**错误展示:**
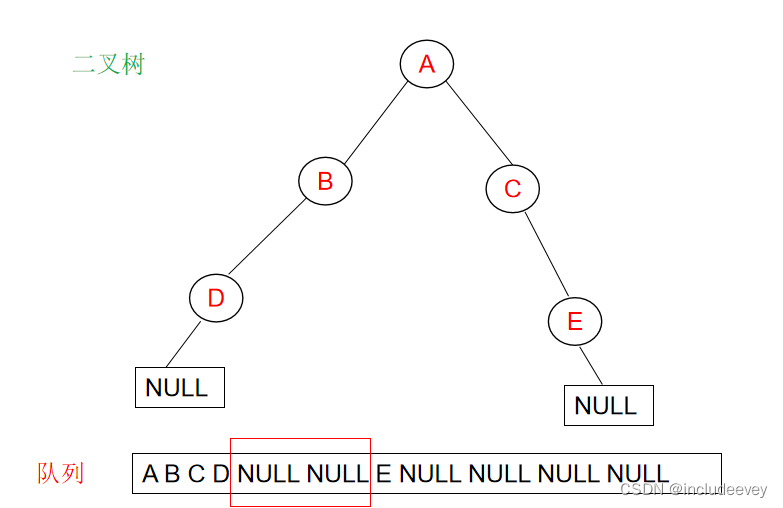
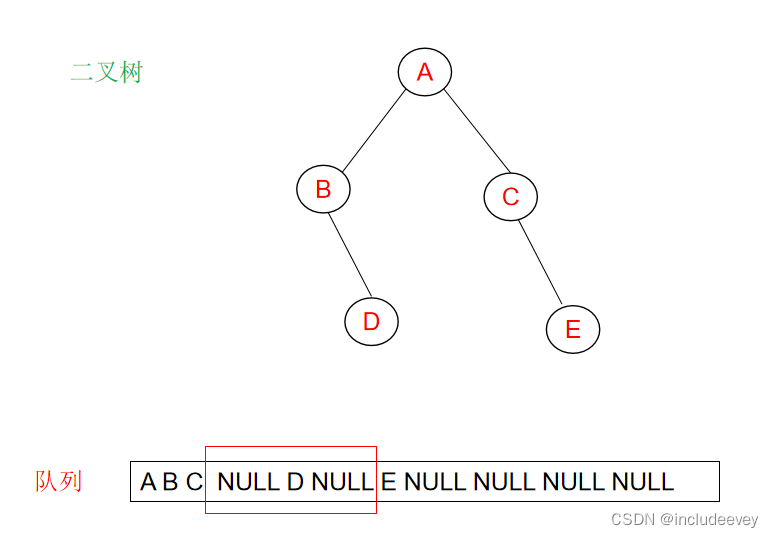
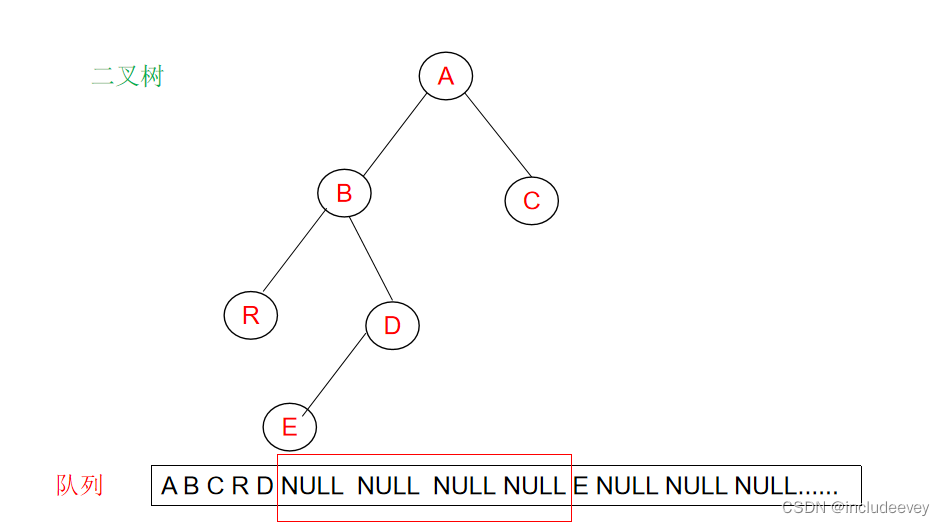
**正确展示:**
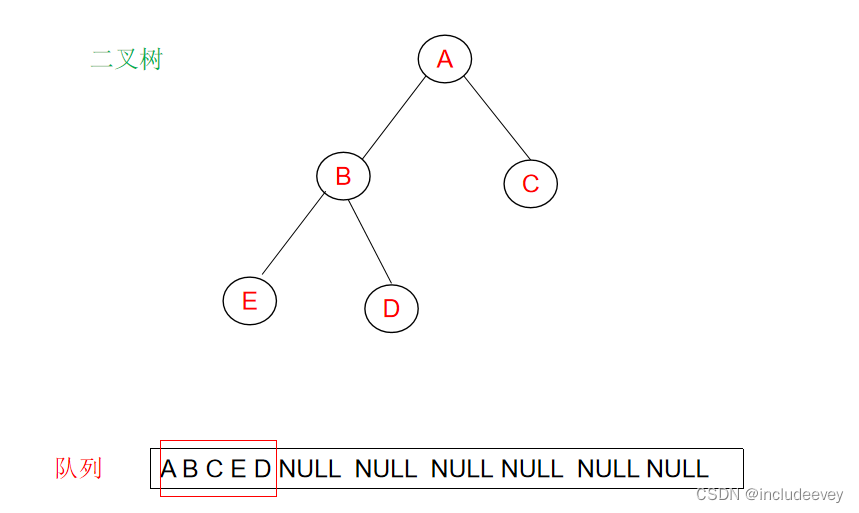
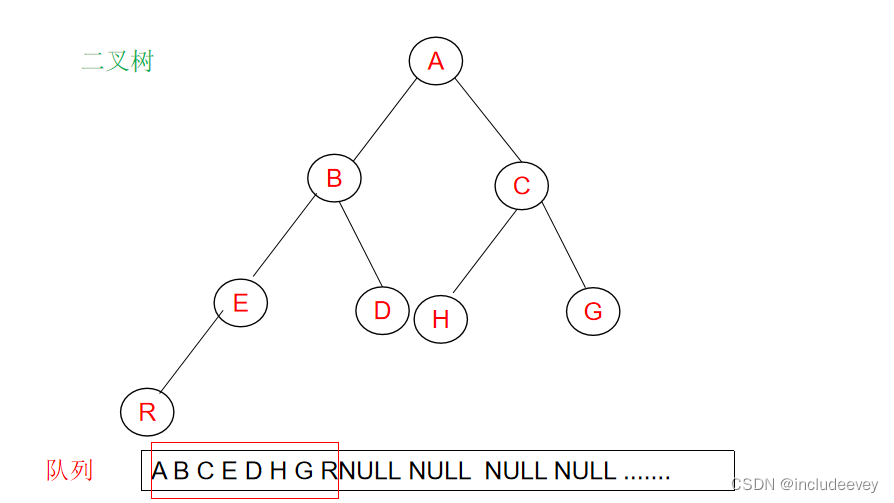
>
> // 判断二叉树是否是完全二叉树
>
>
> int BinaryTreeComplete(BTNode\* root)
>
>
>
#### 二叉树代码实现
实现层序遍历会用到队列的实现,这里就不用写出来了,如果自己需要就大家就可以看一下[数据结构--栈,队列](https://bbs.csdn.net/topics/618545628)。
**BinaryTree.h**
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
typedef int BTDataType;
typedef struct BinaryTreeNode
{
BTDataType _data;
struct BinaryTreeNode* _left;
struct BinaryTreeNode* _right;
}BTNode;
// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi);
// 二叉树销毁
void BinaryTreeDestory(BTNode* root);
// 二叉树节点个数
int BinaryTreeSize(BTNode* root);
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root);
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k);
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root);
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root);
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root);
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root);
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root);
**BinaryTree.c**
#define _CRT_SECURE_NO_WARNINGS
#include “BinaryTree.h”
#include “Queue.h”
// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi)
{
BTNode* tem = (BTNode*)malloc(sizeof(BTNode));
if (a==NULL)
return NULL;
if (a[*pi] == "#" || n >= *pi)
{
(*pi)++;
return NULL;
}
tem->_data = a[*pi];
(*pi)++;
tem->_left = BinaryTreeCreate(a, n, pi);
tem->_right = BinaryTreeCreate(a, n, pi);
return tem;
}
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL “);
return;
}
printf(”%d ", root->_data);
BinaryTreePrevOrder(root->_left);
BinaryTreePrevOrder(root->_right);
}
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
BinaryTreePrevOrder(root->_left);
printf("%d ", root->_data);
BinaryTreePrevOrder(root->_right);
}
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
BinaryTreePrevOrder(root->_left);
BinaryTreePrevOrder(root->_right);
printf("%d ", root->_data);
}
// 二叉树节点个数
int BinaryTreeSize(BTNode* root)
{
if (root == NULL)
return 0;
return BinaryTreeSize(root->_left) + BinaryTreeSize(root->_left) + 1;
}
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root)
{
if (root == NULL)
return 0;
if (root->_left == NULL&&root->_right==NULL)
return 1;
return BinaryTreeLeafSize(root->_left) + BinaryTreeLeafSize(root->_right);
}
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{
assert(k > 0);
if (root == NULL)
return 0;
if (k == 1)
return 1;
return BinaryTreeLevelKSize(root->_left, k - 1) + BinaryTreeLevelKSize(root->_right, k - 1);
}
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{
BTNode* left, *right;
if (root == NULL)
return NULL;
if (root->_data == x)
return root;
left= BinaryTreeFind(root->_left, x);
if (left)
return left;
right = BinaryTreeFind(root->_right, x);
if (right)
return right;
return NULL;
}
// 二叉树销毁
void BinaryTreeDestory(BTNode* root)
{
if (root == NULL)
return ;
BinaryTreeDestory(root->_left);
BinaryTreeDestory(root->_right);
free(root);
}
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root)
{
Queue q;
QueueInit(&q); //初始化队列
if (root != NULL)
QueuePush(&q, root);//将二叉树根节点入队
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);//获取对头元素
QueuePop(&q);//队头出队列
printf(“%d”, front->_data);//打印
if (front->_left)
QueuePush(&q, front->_left);//二叉树做左不为空,进入队列
if (front->_right)
QueuePush(&q, front->_right);//二叉树做右不为空,进入队列
}
printf("\n");
QueueDestroy(&q);//销毁队列
}
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root)
{
Queue q;
QueueInit(&q);
if (root != NULL)
QueuePush(&q, root);
while (!QueueEmpty(&q))//通过层序遍历入队列
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
if (front == NULL)
break;
QueuePush(&q, front->_left);
QueuePush(&q, front->_right);
}
while (!QueueEmpty(&q))//通过出队,如果后续层序有非空为false
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
if (front != NULL)
{
QueueDestroy(front);
return false;
}
}
QueueDestroy(&q);
return true;
}
**Test.c**
#define _CRT_SECURE_NO_WARNINGS
#include “BinaryTree.h”
#include “Queue.h”
BTNode* CreateTree()
{
BTNode* n1 = (BTNode*)malloc(sizeof(BTNode));
assert(n1);
BTNode* n2 = (BTNode*)malloc(sizeof(BTNode));
assert(n2);
BTNode* n3 = (BTNode*)malloc(sizeof(BTNode));
assert(n3);
BTNode* n4 = (BTNode*)malloc(sizeof(BTNode));
assert(n4);
BTNode* n5 = (BTNode*)malloc(sizeof(BTNode));
assert(n5);
BTNode* n6 = (BTNode*)malloc(sizeof(BTNode));
assert(n6);
BTNode* n7 = (BTNode*)malloc(sizeof(BTNode));
assert(n7);
n1->_data = 1;
n2->_data = 2;
n3->_data = 3;
n4->_data = 4;
n5->_data = 5;
n6->_data = 6;
n7->_data = 7;
n1->_left = n2;
n1->_right = n4;
n2->_left = n3;
n2->_right = NULL;
n4->_left = n5;
n4->_right = n6;
n3->_left = NULL;
n3->_right = NULL;
n5->_left = NULL;
n5->_right = NULL;
n6->_left = NULL;
n6->_right = NULL;
n3->_right = n7;
n7->_left = NULL;
n7->_right = NULL;
return n1;
}
int main()
{
BTNode* root = CreateTree();
BinaryTreePrevOrder(root);
printf(“\n”);
BinaryTreeInOrder(root);
printf(“\n”);
printf("%d\n", BinaryTreeSize(root));
printf("%d\n", BinaryTreeLeafSize(root));
printf("%d\n", BinaryTreeLevelKSize(root, 3));
BTNode* ret= BinaryTreeFind(root, 4);
ret->_data = 8;
BinaryTreePrevOrder(root);
return 0;
}
### 二叉树基础练习
为了更加深入学习二叉树,我们通过例题进行练习来加深理解与巩固知识。
#### [单值二叉树](https://bbs.csdn.net/topics/618545628)
**解析:**
我们通过自己检查自己的方法,通过遍历用根节点对每个节点进行判断,如果遍历完了null则正确,如果遍历期间有节点值与根节点值不相等则为错误。
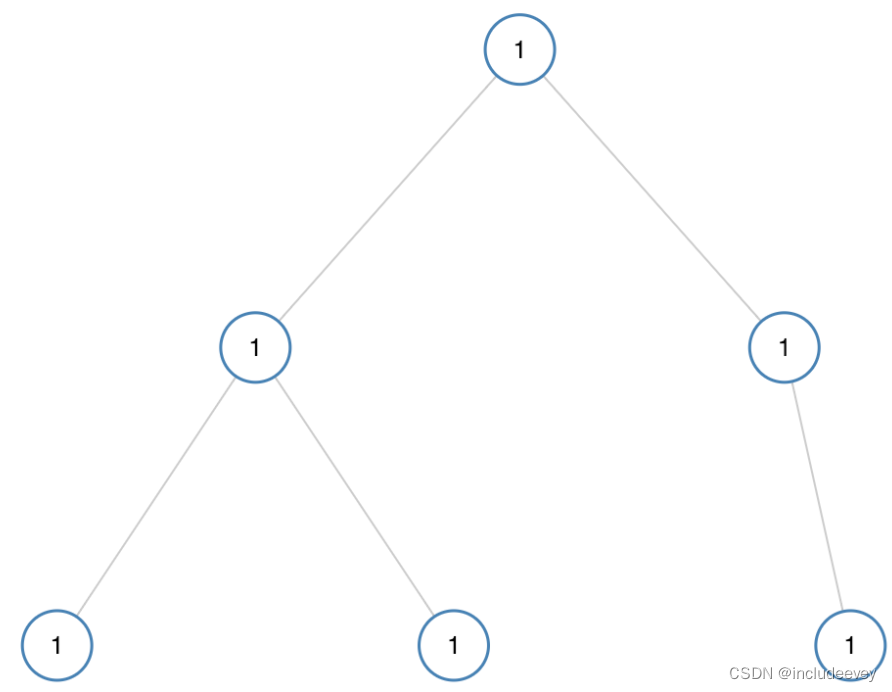
**代码:**
bool isUnivalTree(struct TreeNode* root){
if(root==NULL)
return true;
if(root->left&&root->left->val!=root->val)
return false;
if(root->right&&root->right->val!=root->val)
return false;
return isUnivalTree(root->left)&&isUnivalTree(root->right);
}
#### **[检查两颗树是否相同](https://bbs.csdn.net/topics/618545628)**

**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
为了更加深入学习二叉树,我们通过例题进行练习来加深理解与巩固知识。
#### [单值二叉树](https://bbs.csdn.net/topics/618545628)
**解析:**
我们通过自己检查自己的方法,通过遍历用根节点对每个节点进行判断,如果遍历完了null则正确,如果遍历期间有节点值与根节点值不相等则为错误。

**代码:**
bool isUnivalTree(struct TreeNode* root){
if(root==NULL)
return true;
if(root->left&&root->left->val!=root->val)
return false;
if(root->right&&root->right->val!=root->val)
return false;
return isUnivalTree(root->left)&&isUnivalTree(root->right);
}
#### **[检查两颗树是否相同](https://bbs.csdn.net/topics/618545628)**
[外链图片转存中...(img-rOb8VNVq-1715761685533)]
[外链图片转存中...(img-q6xr1xDs-1715761685533)]
[外链图片转存中...(img-a0CxjxJv-1715761685534)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 2807
2807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









