







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
位置:vi /.bash_profile
添加环境变量
export ZK_HOME=/usr/local/src/zookeeper
export PATH=$PATH:$ZK_HOME/bin
3.配置zoo.cfg配置文件
先创建存放ZK的数据文件和配置文件的zkdata目录mkdir zkdata
配置zoo.cfg文件,在文件中添加下面内容
dataDir=/usr/local/src/zookeeper/zkdata
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
4.分发到其他节点
scp -r zookeeper/ root@slave2:/usr/local/src
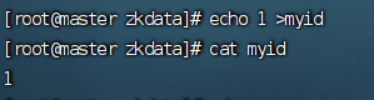
5.修改myid 配置文件
在zkdata目录中创建myid并修改
echo 1>myid (master)
echo 2>myid (slave1)
echo 3>myid (slave2)
—master
—slave1

—slave2

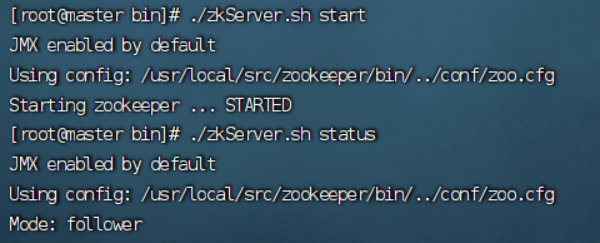
6.启动并查看zookeeper状态
位置:cd /usr/local/src/zookeeper/bin
启动:./zkServer.sh start
状态:./zkServer.sh status
----master
----Slave1
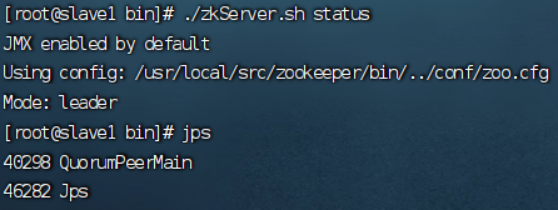
----Slave2
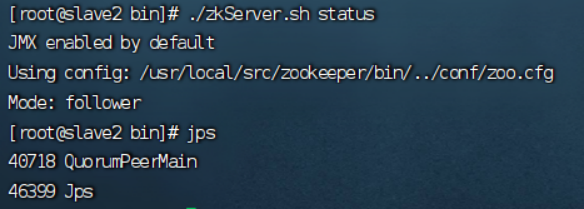
zookeeper配置完成!
四、配置HA高可用
1.解压hadoop安装包
tar -zxvf hadoop-3.2.2.tar.gz -C /usr/local/src
2.添加环境变量
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
3.修改配置文件
位置:/usr/local/src/hadoop/etc/hadoop
(1)core-site.xml
<configuration>
<!-- hdfs分布式文件系统名字/地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--存放namenode、datanode数据的根路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/loal/src/hadoop/data</value>
</property>
<!-- 存放journalnode数据的地址 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/loal/src/hadoop/data/jn</value>
</property>
<!-- 列出运行 ZooKeeper 服务的主机端口对 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value>
</property>
</configuration>
(2)hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 服务的逻辑名称,使用mycluster替换master:9000作为逻辑名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 两个namenode的名称 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2,nn3</value>
</property>
<!-- 两个namenode的rpc通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>slave1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn3</name>
<value>slave2:8020</value>
</property>
<!-- web访问端口 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>slave1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn3</name>
<value>slave2:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value>
</property>
<!-- 切换namenode代理类 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 关闭权限检查 -->
<property>
<name>dfs.permissions.enable</name>
<value>false</value>
</property>
<!-- 通过SSH连接到Active NameNode并终止进程 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 隔离机制 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 启动自动故障转移机制 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
(3) hadoop-env.sh
export JAVA_HOME=/usr/local/jdk
(4) workers
master
slave1
salve2
(5)start-dfs.sh 和 stop-dfs.sh
位置:/usr/local/src/hadoop/sbin
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_SECONDARYNAMENODE_USER=root
4.分发配置文件
scp -r hdfs-site.xml root@slave2:/usr/local/src/hadoop/etc/hadoop
5.1启动JournalNode
hdfs --daemon start journalnode
5.2安装自动转移机制包
yum -y install psmisc
如果不安装这个程序包,自动转移故障机制无法进行 fence。
其他的 Standby 状态的NameNode 不能自动切换为 Active状态。
6.1初始化namenode
在初始化前要先启动三台节点的zookeeper,并关闭防火墙 systemctl stop firewalld
hdfs namenode -format
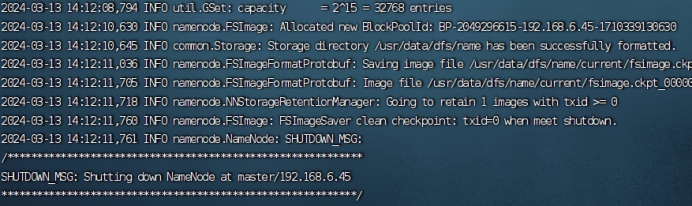
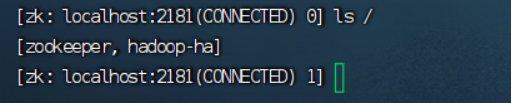
6.2格式化zookeeper
hdfs zkfc -formatZK
判断初始化是否成功:zkCli.sh
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
acdb8caa9.png)
[外链图片转存中…(img-8r651zrv-1715573973331)]
[外链图片转存中…(img-PG2Em8Mp-1715573973331)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









