







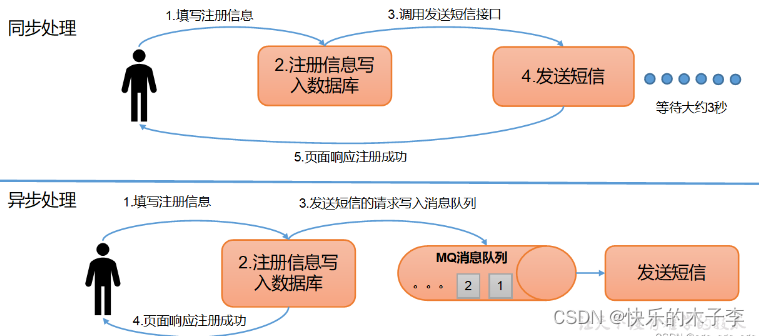
- 解耦:耦合性就是两个模块之间的依赖性,越高呢,维护成本越高,比如说就Producer和Consumer直接连接时,一个发生变化,另一个要做出比较大的调整,有了消息对接在中间,就能降低之间耦合性,也就是解耦
- 异步通讯:允许用户将消息写入消息队列,并不立即去处理
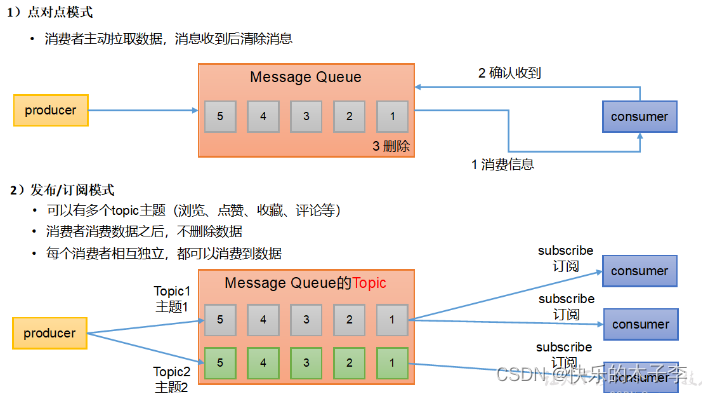
消息队列两种模式
kafka的基础架构
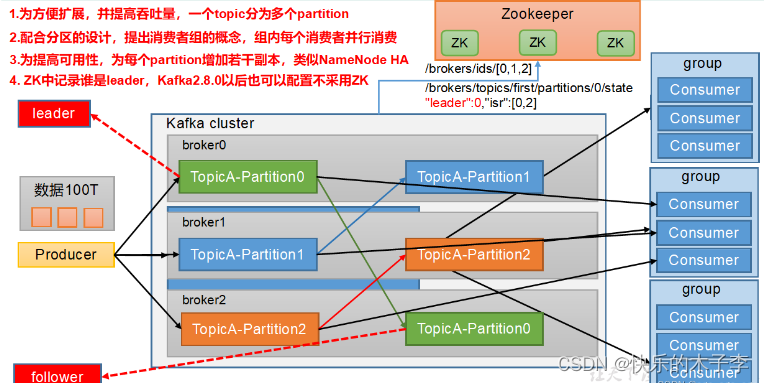
(1)Producer:生产者(可能是flume、MySQL等),其实就是向kafka发送数据的
(2)Consumer:消费者(可能是MySQL、Hadoop、spark、flink),就是向kafka取数据的
(3)Consumer Group:就是消费者组,由一个或者多个consumer组成,在kafka中,消费者都是有组的,即使是在consumer创建时没有没有设置组,但是kafka会默认一个有一个组,是组直接从kafka中的leader中拉取数据,消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者
(4)Broker:kafka代理,即kafka代理服务器,一个集群由多个broker组成,一个broker可以容纳多个topic
(5)topic:主题,可以理解成队列,但是和点对点队列不同的是,不同的消费者组都可以从topic拉去相同的消息
分区
因为不同的分区分布在不同的节点上,所以便于合理使用资源,实现负载均衡,
并且在不同节点上可以提高并行度。
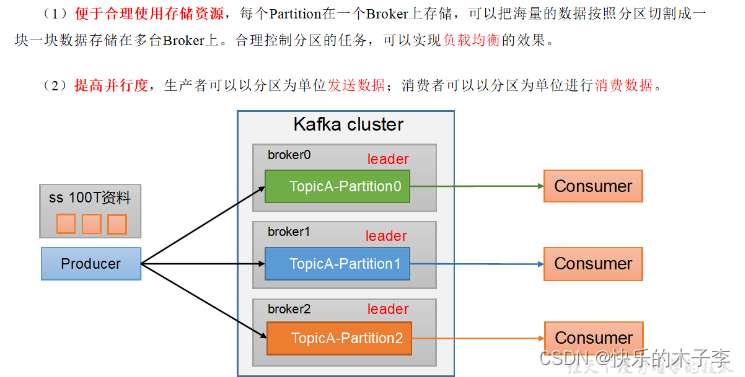
Kafka将消息以topic的方式进行组织和管理,一个topic包含多个分区(partition),每个分区可以理解为一个独立的日志文件。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2551
2551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









