







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
实验二、HDFS实验
实验内容:根据课本《分布式文件系统HDFS》这一章末尾实验"熟悉常用的HDFS操作"完成实验内容。
实验三、MAPREDUCE实验
实验内容:根据课本《MapReduce》这一章末尾实验"MAPREDUCE编程初级实践"完成实验内容。
实验四、HBASE安装与运行实验
实验内容:安装配置HBASE,并根据课本《分布式数据库HBASE》这一章末尾实验《熟悉常用的HBASE操作》完成实验内容
实验五、NoSQL数据库实验
根据Redis与MongoDB的官方文档,完成
(1)Redis数据库的安装,以及Redis数据的插入、取回和删除。https://www.redis.net.cn/tutorial/3501.html
(2)MongoDB数据库的安装,以及MongoDB文档的插入、查询、更新与删除。https://docs.mongoing.com/mongodb-crud-operations/delete-documents
实验六、Spark安装实验
完成SPARK的安装与启动
根据计算机安装的Hadoop版本,选择对应的spark版本下载并安装,安装和Hadoop一样,要实现三个节点主从分配。
Spark安装后,需要先启动Hadoop,再启动spark。启动spark后,进入spark的bin文件夹下,执行命令
./run-example SparkPi 2>&1 | grep “Pi
is”,查看spark是否能输出Pi值,即可知安装与启动是否成功
实验七、Spark编程实验
IRIS数据集处理
根据附件提供的IRIS数据集,使用SPARK RDD的API 完成以下功能:
数据集格式为ID 花萼长度 花萼宽度 花瓣长度 花瓣宽度 花名
(1)分别统计Iris-setosa Iris-versicolor Iris-virginica三种花的花萼长度、花萼宽度、花瓣长度、花瓣宽度的值分布。
(2)根据输入的花萼长度、花萼宽度、花瓣长度、花瓣宽度与花名,找到对应的记录。
声明
参考的林子雨老师的博客
https://dblab.xmu.edu.cn/blog/4189/
大赞林子雨老师,3天怒补7个实验(流汗黄豆.jpg),靠的就是他图文并茂的博客。
我试验的拯救者,期末周的救星,学习道路上的守护神,分数的救世主,hadoop的传奇。
另:
当然有些配置跟子雨老师不一样,也是正常的。
因为我是二臂,安装的是最新版的虚拟机(ubuntu-20.04.6-desktop-amd64),为了用在后面几个实验编程的时候不用eclipse,而是用idea(idea好像跟比较旧版本虚拟机有点冲突,弄了很久安装不上,索性放弃。至于为什么不用eclipse,因为eclipse我一生之敌。不惜把前面几个实验的hadoop,各种配置重新安装,也要换了新版虚拟机来配idea。)。
《大数据技术基础》实验报告1
目的
(1)掌握Linux虚拟机的安装方法。Hadoop在Linux操作系统上运行可以发挥最佳性能。鉴于目前很多读者正在使用Windows操作系统,因此,为了完成本书的后续实验,这里有必要通过本实验让读者掌握在Windows操作系统上搭建Linux虚拟机的方法。
(2)掌握 Hadoop
的伪分布式安装方法。很多读者并不具备集群环境,需要在一台机器上模拟一个小的集群,因此,需要通过本实验让读者掌握在单机上进行Hadoop的伪分布式安装方法。
二、实验平台
操作系统:Windows系统或者Ubuntu(推荐)。
虚拟机软件:推荐使用的开源虚拟机软件为VirtualBox。VirtualBox是一款功能强大的免费虚拟机软件,不仅具有丰富的特色、优异的性能,而且简单易用,可虚拟的系统包括Windows、Mac
OS X、Linux、OpenBSD、Solaris、IBM OS2,甚至Android
4.0系统等。读者可以在Windows系统上安装VirtualBox软件,然后在VirtualBox上安装并且运行Linux操作系统。本次实验默认的Linux发行版为Ubuntu14.04。
三、实验内容和要求
1.下载相关软件
如果读者正在使用 Linux
操作系统,可以跳过本步,不需要下载相关软件;如果正在使用Windows操作系统,请下载VirtualBox软件和Ubuntu14.04镜像文件。
VirtualBox软件的下载地址:https://www.virtualbox.org/wiki/Downloads。
Ubuntu14.04的镜像文件下载地址:http://www.ubuntu.org.cn/download/desktop。
2.安装Linux虚拟机
如果读者正在使用Linux操作系统,则不需要了解Windows系统上的Linux虚拟机安装方法;如果正在使用Windows操作系统,则需要在Windows系统上安装Linux虚拟机。首先,在Windows系统上安装虚拟机软件VirtualBox软件;其次,在虚拟机软件VirtualBox上安装Ubuntu14.04操作系统。
3.进行Hadoop伪分布式安装
在Linux环境下完成伪分布式环境的搭建,并运行Hadoop自带的WordCount实例检测是否运行正常。
四、实验内容
使用 Ubuntu 16 32位 作为系统环境
创建hadoop用户
打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash
接着使用如下命令设置密码,可简单设置为 hadoop,按提示输入两次密码:
sudo passwd hadoop
为 hadoop 用户增加管理员权限,方便部署
sudo adduser hadoop sudo
更新apt
# 删除software center
sudo apt-get remove libappstream3
# 重新安装
sudo apt-get update
安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆,Ubuntu 默认已安装了 SSH
client,此外还需要安装 SSH server:
sudo apt-get install openssh-server
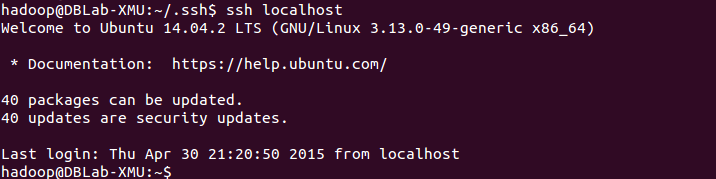
安装后,可以使用如下命令登陆本机:
ssh localhost
此时会有SSH首次登陆提示,输入 yes 。然后按提示输入密码
hadoop,这样就登陆到本机了。
但这样登陆是需要每次输入密码的,需要配置成SSH无密码登陆比较方便。
首先退出刚才的 ssh,就回到了我们原先的终端窗口,然后利用 ssh-keygen
生成密钥,并将密钥加入到授权中:
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh
localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
此时再用 ssh localhost 命令,无需输入密码就可以直接登陆了,如下图所示。
安装Java环境
下载jdk-8u162-linux-x64.tar.gz并复制到"/home/Downloads/"目录下。
执行下面命令:
cd /usr/lib
sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件
cd ~ #进入hadoop用户的主目录
cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下
sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下
JDK文件解压缩以后,可以执行如下命令到/usr/lib/jvm目录查看一下:
cd /usr/lib/jvm
ls
可以看到,在/usr/lib/jvm目录下有个jdk1.8.0_162目录。
下面继续执行如下命令,设置环境变量:
cd ~
vim ~/.bashrc
上面命令使用vim编辑器(查看vim编辑器使用方法)打开了hadoop这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容:
export JAVA\_HOME=/usr/lib/jvm/jdk1.8.0\_162
export JRE\_HOME=${JAVA\_HOME}/jre
export CLASSPATH=.:${JAVA\_HOME}/lib:${JRE\_HOME}/lib
export PATH=${JAVA\_HOME}/bin:$PATH
保存.bashrc文件并退出vim编辑器。然后,继续执行如下命令让.bashrc文件的配置立即生效:
source ~/.bashrc
这时,可以使用如下命令查看是否安装成功:
java -version
报错:
cannot execute binary file: 可执行文件格式错误
于是改成
export JAVA\_HOME="/usr/lib/jvm/jdk1.8.0\_162"
export JRE\_HOME=${JAVA\_HOME}/jre
export CLASSPATH=.:${JAVA\_HOME}/lib:${JRE\_HOME}/lib
export PATH=${JAVA\_HOME}/bin:$PATH
报错:
bash: /usr/lib/jvm/jdk1.8.0_162/bin/java: cannot execute binary file:
Exec format error
判断是jdk安装错误,查看linux版本
uname -a
Linux ubuntu 4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:34:49 UTC
2016 i686 athlon i686 GNU/Linux
需要安装32位的版本,于是重新下载jdk-8u162-linux-i586.tar.gz并进行上述操作。
如果能够在屏幕上返回如下信息,则说明安装成功:
hadoop@ubuntu:~$ java -version
java version "1.8.0\_162"
Java(TM) SE Runtime Environment (build 1.8.0_162-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
至此,就成功安装了Java环境。下面就可以进入Hadoop的安装。
安装 Hadoop3.1.3
Hadoop安装文件,可以到Hadoop官网下载hadoop-3.1.3.tar.gz。
我们选择将 Hadoop 安装至 /usr/local/ 中:
sudo tar -zxf ~/下载/hadoop-3.1.3.tar.gz -C /usr/local #解压到/usr/local中
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop # 将文件夹名改为hadoop
sudo chown -R hadoop ./hadoop # 修改文件权限
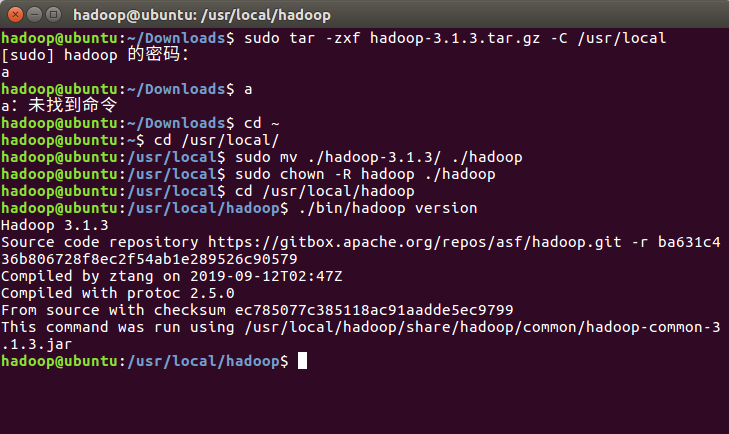
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示
Hadoop 版本信息:
cd /usr/local/hadoop
./bin/hadoop version
Hadoop单机配置(非分布式)
运行 grep 例子,我们将 input文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
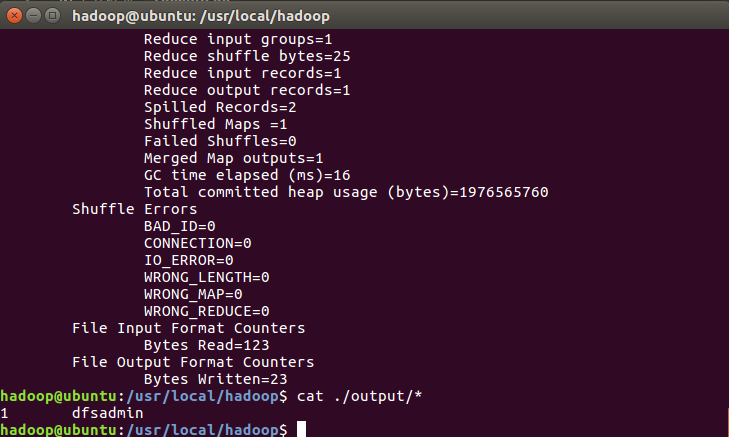
cat ./output/* # 查看运行结果
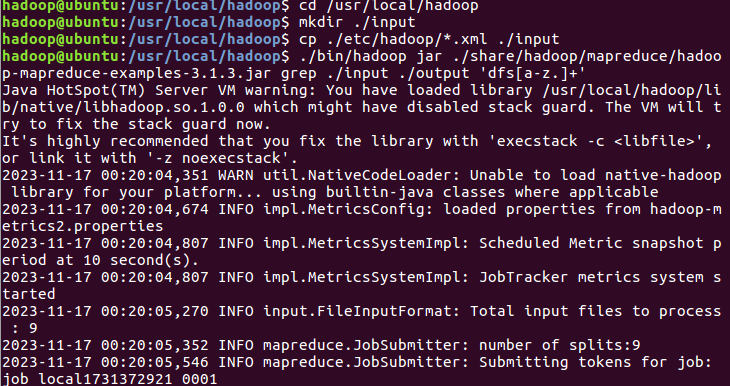
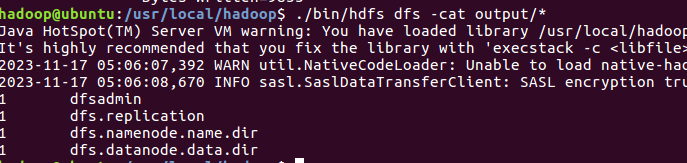
执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词
dfsadmin 出现了1次
Hadoop伪分布式配置
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value的方式来实现。
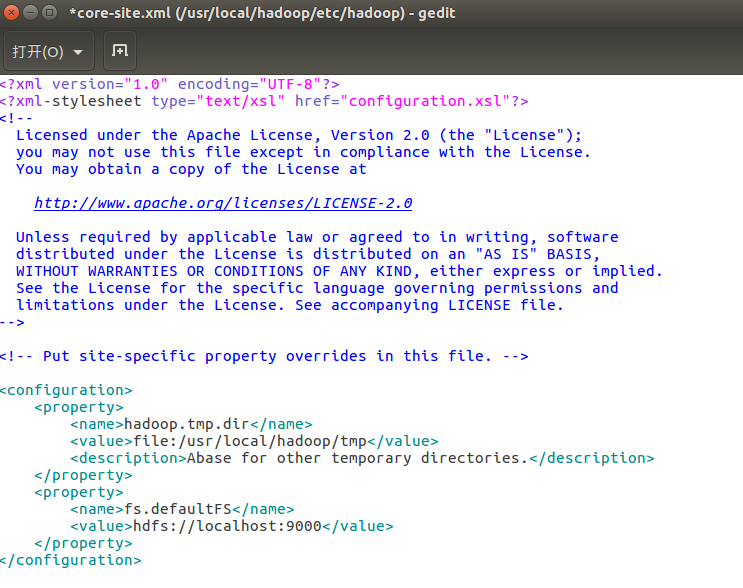
修改配置文件 core-site.xml (通过 gedit 编辑会比较方便: gedit ./etc/hadoop/core-site.xml),将当中的
<configuration>
</configuration>
修改为下面配置:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改完如下图:
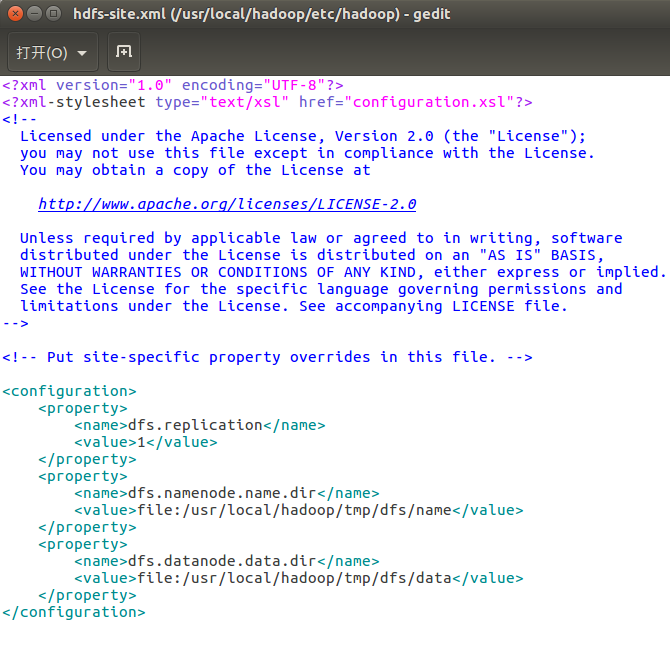
同样的,修改配置文件 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
修改完如下图:
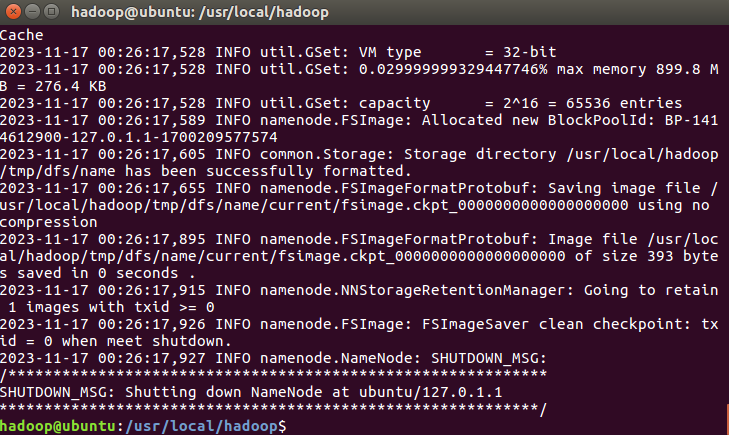
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
成功的话,会看到 “successfully formatted”
的提示,具体返回信息类似如下:
接着开启 NameNode 和 DataNode 守护进程。
cd /usr/local/hadoop
./sbin/start-dfs.sh
结果如下:
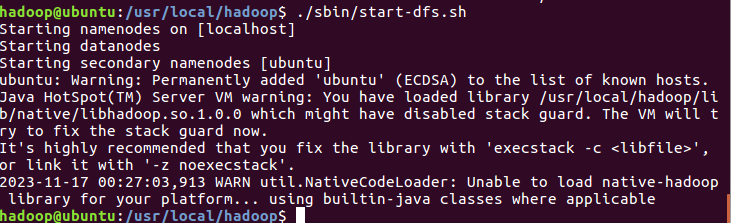
显示namenode启动,datanode启动,第二namenode启动。
可以检查namenode和datanode节点是否按需启动,使用下面的shell命令查看进程号:
jps | grep NameNode | awk '{print $1}'
jps | grep DataNode | awk '{print $1}'
如果发现打印结果是空的,就是出问题了,于是到hadoop/ logs
/hadoop-hadoop-namenode-ubuntu.log中进行查看,错误信息如下:
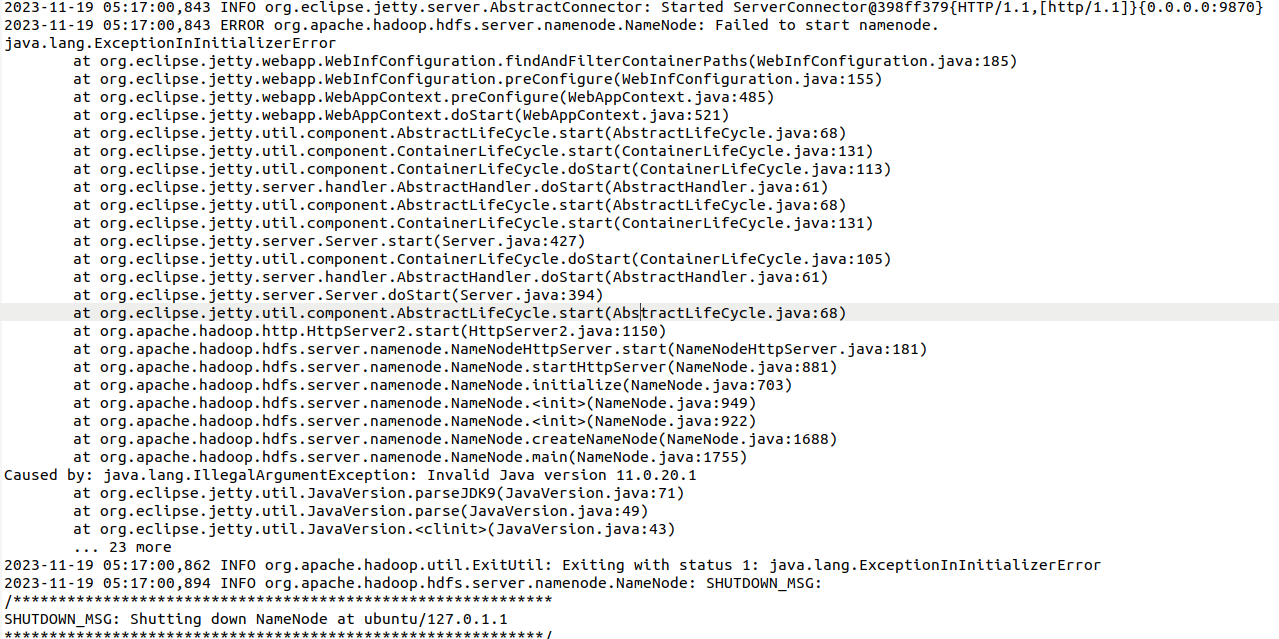
(NameNode)的启动失败,原因是一个 ExceptionInInitializerError 异常
已经确认修改了两个配置文件,也确认了已经赋予hadoop文件夹应有的权限(即hadoop用户权限),仍然失败。
于是删除hadoop文件夹,重新解压和后续操作。
结果如下:

很好,已经完美启动了
运行Hadoop伪分布式实例
上面的单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS
上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录:
./bin/hdfs dfs -mkdir -p /user/hadoop
接着将 ./etc/hadoop 中的 xml
文件作为输入文件复制到分布式文件系统中,即将
/usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input
中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop
,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是
/user/hadoop/input:
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/\*.xml input
如果创建input文件夹出现如下错误:
kdir: `hdfs://localhost:9000/user/用户名’: No such file or directory
则把所有input改成/input即可。
复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls input
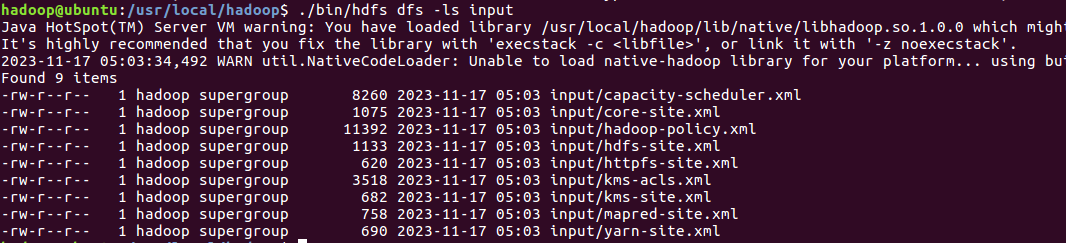
伪分布式运行 MapReduce
作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地
input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
使用grep和wordcount进行测试:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-\*.jar grep input output 'dfs[a-z.]+'
查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
./bin/hdfs dfs -cat output/\*
结果如下,注意到刚才我们已经更改了配置文件,所以运行结果不同。

使用wordcount进行测试:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount input output 'dfs[a-z.]+'
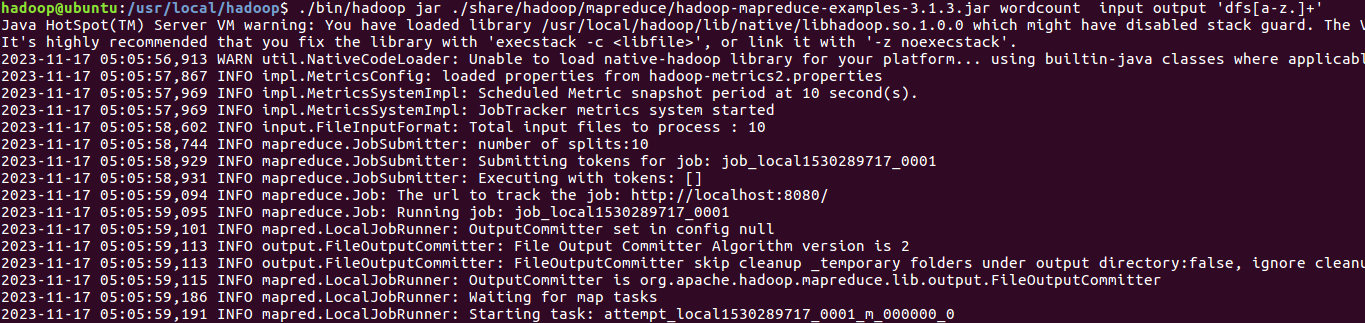
结果当然也是和grep一样的:
《大数据技术基础》实验报告2
目的
(1)理解HDFS在Hadoop体系结构中的角色。
(2)熟练使用HDFS操作常用的Shell命令。
(3)熟悉HDFS操作常用的Java API。
二、实验平台
操作系统:Linux。
Hadoop版本:2.7.3或以上版本。
JDK版本:1.7或以上版本。
Java IDE:Eclipse/IDEA。
三、实验要求
(1)编程实现以下指定功能,并利用Hadoop提供的Shell命令完成相同的任务。
- 向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。
- 从 HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名。
- 将HDFS中指定文件的内容输出到终端。
- 显示HDFS中指定的文件读写权限、大小、创建时间、路径等信息。
- 给定 HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息。
- 提供一个 HDFS内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录。
- 提供一个 HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录。
- 向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾。
- 删除HDFS中指定的文件。
- 在HDFS中将文件从源路径移动到目的路径。
(2)编程实现一个类"MyFSDataInputStream",该类继承"org.apache.hadoop.fs.FSDataInput
Stream",要求如下。
- 实现按行读取HDFS中指定文件的方法"readLine()",如果读到文件末尾,则返回空,否则返回文件一行的文本。
- 实现缓存功能,即利用"MyFSDataInputStream"读取若干字节数据时,首先查找缓存,如果缓存中有所需数据,则直接由缓存提供,否则向HDFS读取数据。
(3)查看Java帮助手册或其他资料,用"java.net.URL"和"org.apache.hadoop.fs.FsURLStream.HandlerFactory"编程来输出HDFS中指定文件的文本到终端中。
实验内容
编程实现以下指定功能,并利用Hadoop提供的Shell命令完成相同的任务。
- 向HDFS中上传任意文本文件,如果指定的文件在HDFS中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。
在Documents/jht.txt下新建一个jht.txt,里面内容是"this is a test
file."
shell如下:
local_file_path="/home/jht/Documents/jht.txt"
hdfs_file_path="/user/hadoop/jht.txt"
/usr/local/hadoop/bin/hdfs dfs -test -e ${hdfs_file_path}
file_exists=$?
if [ $file\_exists -eq 0 ]; then
echo "文件已存在于HDFS中。"
echo "请选择操作方式:"
echo "1. 追加到原有文件末尾"
echo "2. 覆盖原有文件"
read -p "请选择操作方式(输入数字1或2,1追加,2覆盖): " choice
case $choice in
1)
# 追加到原有文件末尾
sudo /usr/local/hadoop/bin/hdfs dfs -appendToFile ${local_file_path} ${hdfs_file_path}
echo "文件已追加到原有文件末尾。"
;;
2)
# 覆盖原有文件
sudo /usr/local/hadoop/bin/hdfs dfs -put -f ${local_file_path} ${hdfs_file_path}
echo "文件已成功覆盖原有文件。"
;;
\*)
echo "无效的选择。"
exit 1
;;
esac
else
# 目标文件不存在,直接上传文件
sudo /usr/local/hadoop/bin/hdfs dfs -put ${local_file_path} ${hdfs_file_path}
echo "文件已成功上传到HDFS。"
fi
问题1:
运行./1.sh后出现"JAVA_HOME is not set and could not be found."报错
执行
echo $JAVA\_HOME
可以查看自己的JAVA目录。
进入到hadoop安装目录下的$HADOOP_HOME/etc/hadoop
目录下,进入到hadoop-env.sh中,在文件中添加如下内容
export JAVA\_HOME=你的JAVA目录
就解决了。
问题2:
put: `~/Documents/jht.txt’: No such file or directory
但是这个路径是正确的。将"~“替换为”/home/用户名"
问题3:
./1.sh: 4: hdfs: not found
环境路径不管用。虽然检查了环境路径里面已经写了HADOOP_HOME和PATH,但是仍然报找不到HDFS的错。于是把shell里面的hdfs命令都改为绝对路径,即"/usr/local/hadoop/bin/hdfs"。
问题4:
put: Permission denied: user=root, access=WRITE,
inode=“/user/hadoop”:jht:supergroup:drwxr-xr-x
权限问题,执行如下命令:
hadoop fs -chmod -R 777 /
777权限即为UGO都为可读可写可执行,赋予读写权限即可。
测试结果:

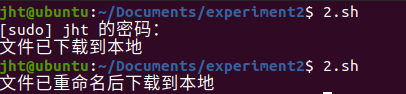
- 从 HDFS中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名。
local_file_path="/home/jht/Documents/jht.txt"
local_file2_path="/home/jht/Documents/jht\_from\_hdfs.txt"
hdfs_file_path="/user/hadoop/jht.txt"
if [ -f "${local\_file\_path}" ]; then
sudo /usr/local/hadoop/bin/hdfs dfs -get ${hdfs_file_path}
${local_file2_path}
echo "文件已重命名后下载到本地"
else
sudo /usr/local/hadoop/bin/hdfs dfs -get ${hdfs_file_path}
${local_file_path}
echo "文件已下载到本地"
fi
问题1:
运行2.sh,报错"bash: ./2.sh: 权限不够"
文件没有执行权限:如果文件没有执行权限,你可以先赋予执行权限,然后再执行它。可以使用
chmod 命令来设置执行权限,如:chmod +x 2.sh。
结果如下:
- 将HDFS中指定文件的内容输出到终端。
dfs dfs -cat /user/hadoop/jht.txt
结果如下:

- 显示HDFS中指定的文件读写权限、大小、创建时间、路径等信息。
hdfs dfs -stat '%a %b %y %n' /user/hadoop/jht.txt
结果如下:

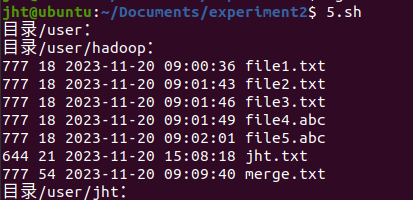
- 给定 HDFS
中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息。
printFile(){
local hdfs_path=$1
echo "目录${hdfs\_path}:"
for i in `hdfs dfs -ls ${hdfs_path} | awk 'NR>1 {print
$NF}'`; do
if [ $(hdfs dfs -test -f "${i}"; echo $?) -eq 0 ];then
hdfs dfs -stat '%a %b %y %n' ${i}
else
printFile ${i}
fi
done
}
printFile /user
结果如下:
- 提供一个 HDFS
内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录。
报错1:mkdir: Cannot create directory /user/hadoop/jht2. Name node
is in safe mode.
关闭安全模式,hdfs dfsadmin -safemode leave
#!/bin/bash
createFile(){
local filename=$1
local dirname=$(dirname "$filename")
hdfs dfs -mkdir -p ${dirname}
hdfs dfs -touch ${filename}
}
createFile /user/hadoop/jht/newFile1.txt
createFile /user/hadoop/jht2/newFile2.txt
createFile /user/hadoop/jht3/newFile3.txt
结果如下:
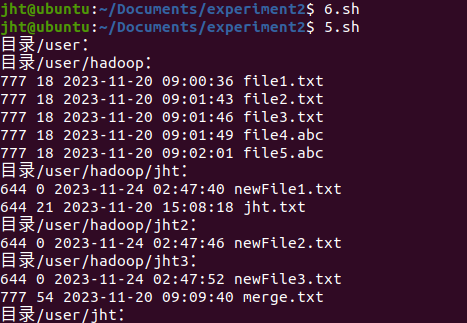
可以看到三个文件已经创建完毕了。
7. 提供一个 HDFS
的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录。
#!/bin/bash
createDir(){
local dirname=$1
hdfs dfs -mkdir -p ${dirname}
}
deleteDir(){
local dirname=$1
if hdfs dfs -test -d "${dirname}"; then
num_files=$(hdfs dfs -count -h "${dirname}" | awk '{print
$2}')
if [ ${num_files} -eq 0 ]; then
hdfs dfs -rm -r "${dirname}"
echo "Directory ${dirname} deleted."
else
echo "Directory ${dirname} is not empty and contains
${num\_files} files."
read -p "Do you want to delete ${dirname}? [y/n] "
choice
case "$choice" in
y|Y ) hdfs dfs -rm -r "${dirname}" && echo "Directory
${dirname} deleted.";;
n|N ) echo "Directory deletion cancelled.";;
\* ) echo "Invalid option. Directory deletion
cancelled.";;
esac
fi
else
echo "Directory ${dirname} does not exist in HDFS."
fi
}
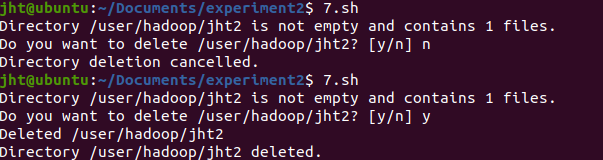
createDir /user/hadoop/jht3
deleteDir /user/hadoop/jht2
结果如下:
- 向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾。
#!/bin/bash
# 获取用户输入的操作类型和要追加的内容
read -p "请选择要进行的操作类型(1-开头,2-结尾): " operation
read -p "请输入要追加的内容: " content
hdfs_path="/user/hadoop/jht/newFile1.txt"
temp_file_path="/home/jht/Documents/temp.txt"
# 下载HDFS文件到本地临时文件
hdfs dfs -get -f "$hdfs\_path" "$temp\_file\_path"
# 根据操作类型,将内容追加到临时文件的开头或结尾
if [ "$operation" = "1" ]; then
echo "$content" > "$temp\_file\_path.tmp"
cat "$temp\_file\_path" >> "$temp\_file\_path.tmp"
cp -f "$temp\_file\_path.tmp" "$temp\_file\_path"
elif [ "$operation" = "2" ]; then
echo "$content" >> "$temp\_file\_path"
fi
# 将修改后的临时文件上传回HDFS,并删除本地临时文件
hdfs dfs -put -f "$temp\_file\_path" "$hdfs\_path"
# rm "$temp\_file\_path" "$temp\_file\_path.tmp"
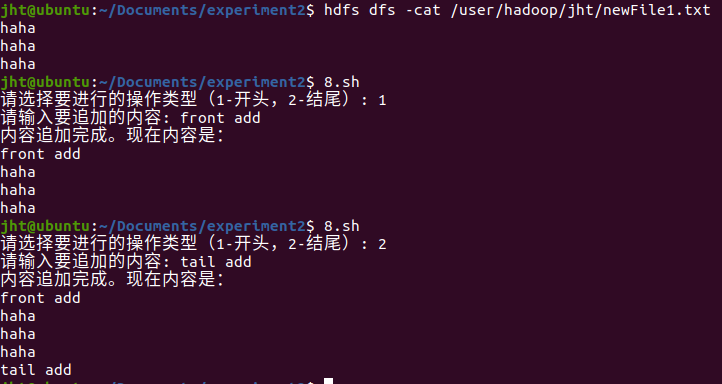
echo "内容追加完成。现在内容是:"
hdfs dfs -cat "$hdfs\_path"
结果如下:
- 删除HDFS中指定的文件。
#!/bin/bash
hdfs_path="/user/hadoop/jht2/newFile2.txt"
hdfs dfs -rm $hdfs\_path
结果如下:

- 在HDFS中将文件从源路径移动到目的路径。
#!/bin/bash
source_path="/user/hadoop/jht/newFile1.txt"
target_path="/user/hadoop/jht2/newFile2.txt"
hdfs dfs -mv $source\_path $target\_path
结果如下:

(2)编程实现一个类"MyFSDataInputStream",该类继承"org.apache.hadoop.fs.FSDataInput
Stream",要求如下。
①
实现按行读取HDFS中指定文件的方法"readLine()",如果读到文件末尾,则返回空,否则返回文件一行的文本。
②
实现缓存功能,即利用"MyFSDataInputStream"读取若干字节数据时,首先查找缓存,如果缓存中有所需数据,则直接由缓存提供,否则向HDFS读取数据。
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class MyFSDataInputStream extends FSDataInputStream {
public MyFSDataInputStream(FSDataInputStream in) {
super(in);
}
public static void readFile(String filepath) throws IOException {
BufferedReader reader = null;
StringBuilder sb = new StringBuilder();
try {
// 创建Hadoop配置对象
Configuration conf = new Configuration();
// 设置Hadoop集群的URI
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem fileSystem = FileSystem.get(conf);
Path path = new Path(filepath);
reader = new BufferedReader(new
InputStreamReader(fileSystem.open(path)));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} finally {
if (reader != null) {
reader.close();
}
}
}
public static void isConnected(String filePath) {
try {
// 创建Hadoop配置对象
Configuration conf = new Configuration();
// 设置Hadoop集群的URI
conf.set("fs.defaultFS", "hdfs://localhost:9000");
// 创建Hadoop文件系统对象
FileSystem fs = FileSystem.get(conf);
// 执行具体的Hadoop文件操作
Path path = new Path(filePath);
boolean exists = fs.exists(path);
if (exists) {
System.out.println(filePath+":File exists");
} else {
System.out.println(filePath+":File does not exist");
}
// 关闭文件系统连接
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException {
String filePath = "/user/hadoop/jht2/newFile2.txt";
// isConnected(filePath);
readFile(filePath);
}
}
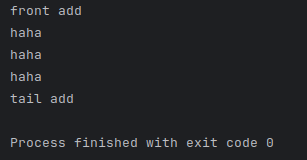
结果如下:
先用isConnected测试一下,可以链接到Hadoop,并且可以正确检测到文件。
然后调用readFile,可以正确读取到文件内容。

3. 查看Java帮助手册或其他资料,用"java.net.URL"和"org.apache.hadoop.fs.FsURLStream
HandlerFactory"编程来输出HDFS中指定文件的文本到终端中。
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
public class ReadHDFSFile {
public static void main(String[] args) throws Exception {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
URL hdfsUrl = new
URL("hdfs://localhost:9000/user/hadoop/jht2/newFile2.txt");
BufferedReader reader = new BufferedReader(new
InputStreamReader(hdfsUrl.openStream()));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
reader.close();
}
}
结果如下:
《大数据技术基础》实验报告3
目的
(1)通过实验掌握基本的MapReduce编程方法。
(2)掌握用MapReduce解决一些常见数据处理问题的方法,包括数据去重、数据排序和数据挖掘等。
二、实验平台
操作系统:Linux。
Hadoop版本:2.7.3或以上版本。
JDK版本:1.7或以上版本。
Java IDE:Eclipse/IDEA。
三、实验要求
- 编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。 - 编程实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个整数为第二个整数的排序位次,第二个整数为原待排列的整数。 - 对给定的表格进行信息挖掘
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
实验内容
1.编程实现文件合并和去重操作
对于两个输入文件,即文件A和文件B,请编写MapReduce程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新的输出文件C。下面是输入文件和输出文件的一个样例供参考。
输入文件A的样例如下。
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
输入文件B的样例如下。
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
根据输入文件A和B合并得到的输出文件C的样例如下。
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
代码:
package EXP3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.\*;
import org.apache.hadoop.mapreduce.\*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import java.io.File;
import java.io.IOException;
public class DuplicateRemoval {
public static class DuplicateRemovalMapper extends Mapper<Object,
Text, Text, NullWritable> {
private Text word = new Text();
public void map(Object key, Text value, Context context) throws
IOException, InterruptedException {
System.out.println("value:"+value);
word.set(value.toString());
context.write(word, NullWritable.get());
}
}
public static class DuplicateRemovalReducer extends Reducer<Text,
NullWritable, Text, NullWritable> {
public void reduce(Text key, Iterable<NullWritable> values,
Context context) throws IOException, InterruptedException {
System.out.println("key:"+key);
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
String path1="/home/jht/Documents/experiment3/1a.txt";
String path2="/home/jht/Documents/experiment3/1b.txt";
String path3="/home/jht/Documents/experiment3/1c";
File folder = new File(path3);
if (folder.exists())
folder.delete();
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Duplicate Removal");
job.setJarByClass(DuplicateRemoval.class);
job.setMapperClass(DuplicateRemovalMapper.class);
job.setReducerClass(DuplicateRemovalReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.addInputPath(job, new Path(path1));
FileInputFormat.addInputPath(job, new Path(path2));
FileOutputFormat.setOutputPath(job, new Path(path3));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
结果:

2.编程实现对输入文件的排序
现在有多个输入文件,每个文件中的每行内容均为一个整数。要求读取所有文件中的整数,进行升序排序后,输出到一个新的文件中,输出的数据格式为每行两个整数,第一个整数为第二个整数的排序位次,第二个整数为原待排列的整数。下面是输入文件和输出文件的一个样例,供参考。
输入文件1的样例如下。
33
37
12
40
输入文件2的样例如下。
4
16
39
5
输入文件3的样例如下。
1
45
25
根据输入文件1、2和3得到的输出文件如下。
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
代码:
package EXP3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.File;
import java.io.IOException;
import static java.lang.System.exit;
public class IntegerSorting {
public static class SortMapper extends Mapper<Object, Text,
IntWritable, IntWritable> {
@Override
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
int keyNum = Integer.parseInt(value.toString());
System.out.println("key:"+keyNum);
IntWritable theKey = new IntWritable(keyNum);
context.write(theKey,new IntWritable(1));
}
}
private static int count=0;
public static class SortReducer extends Reducer<IntWritable,
IntWritable, IntWritable, IntWritable> {
@Override
protected void reduce(IntWritable key, Iterable<IntWritable>
values, Context context) throws IOException, InterruptedException {
count++;
IntWritable theKey = new IntWritable(count);
context.write(theKey, key);
}
}
public static void main(String[] args) throws Exception {
String path1="/home/jht/Documents/experiment3/2a.txt";
String path2="/home/jht/Documents/experiment3/2b.txt";
String path3="/home/jht/Documents/experiment3/2c.txt";
String path4="/home/jht/Documents/experiment3/2d";
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Integer Sorting");
job.setJarByClass(IntegerSorting.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(path1));
FileInputFormat.addInputPath(job, new Path(path2));
FileInputFormat.addInputPath(job, new Path(path3));
FileOutputFormat.setOutputPath(job, new Path(path4));
exit(job.waitForCompletion(true) ? 0 : 1);
}
}
结果如下:

3.对给定的表格进行信息挖掘
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
输入文件内容如下。
child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
Mark Alma
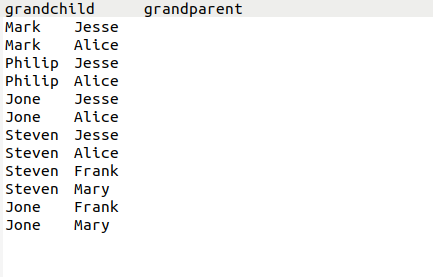
输出文件内容如下。
grandchild grandparent
Steven Alice
Steven Jesse
Jone Alice
Jone Jesse
Steven Mary
Steven Frank
Jone Mary
Jone Frank
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
代码:
package EXP3;
import java.io.IOException;
import java.util.\*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import static java.lang.System.exit;
public class ChildParent {
//Map将输入文件按照空格分割成child和parent,然后正序输出一次作为右表,反序输出一次作为左表,需要注意的是在输出的value中必须加上左右表区别标志
public static class Map extends Mapper<Object, Text, Text, Text>{
public void map(Object key, Text value, Context context) throws
IOException,InterruptedException{
String line = value.toString();
int i = 0;
while(line.charAt(i) != ' ')
i++;
String child_name = line.substring(0,i);
String parent_name = line.substring(i+1);
if(child_name.compareTo("child") != 0 &&
!child_name.isEmpty() && !parent_name.isEmpty()){
context.write(new Text(parent_name), new
Text("1+"+child_name));
context.write(new Text(child_name), new
Text("2+"+parent_name));
}
}
}
public static boolean header = true;
public static class Reduce extends Reducer<Text, Text, Text,
Text>{
public void reduce(Text key, Iterable<Text> values,Context
context) throws IOException,InterruptedException{
if(header){
context.write(new Text("grandchild"), new
Text("grandparent"));
header = false;
}
System.out.println("==="+key);
List<String> grand_child = new
ArrayList<>(),grand_parent = new ArrayList<>();
for(Text value:values)
{
String record = value.toString();
char relation_type = record.charAt(0);
String name = record.substring(2);
if (relation_type == '1')
grand_child.add(name);
else
grand_parent.add(name);
}
for(String child:grand_child)
{
for(String parent:grand_parent)
{
context.write(new Text(child),new Text(parent));
}
}
}
}
public static void main(String[] args) throws Exception{
String path1="/home/jht/Documents/experiment3/3a.txt";
String path2="/home/jht/Documents/experiment3/3b";
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "ChildParent");
job.setJarByClass(ChildParent.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(path1));
FileOutputFormat.setOutputPath(job, new Path(path2));
exit(job.waitForCompletion(true) ? 0 : 1);
}
}
结果如下:
《大数据技术基础》实验报告4
目的
(1)理解HBase在Hadoop体系结构中的角色。
(2)熟练使用HBase操作常用的Shell命令。
(3)熟悉HBase操作常用的Java API。
二、实验平台
操作系统:Linux。
Hadoop版本:2.7.3或以上版本。
JDK版本:1.7或以上版本。
Java IDE:Eclipse/IDEA。
三、实验要求
(1)编程实现以下指定功能,并用Hadoop提供的HBase
Shell命令完成相同的任务。
① 列出HBase所有表的相关信息,如表名、创建时间等。
② 在终端打印出指定表的所有记录数据。
③ 向已经创建好的表添加和删除指定的列族或列。
④ 清空指定表的所有记录数据。
⑤ 统计表的行数。
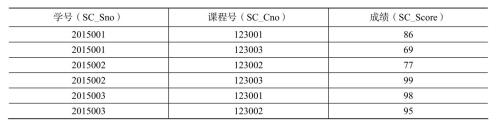
(2)现有以下关系型数据库中的表(见表4-20、表4-21和表4-22),要求将其转换为适合HBase存储的表并插入数据。


同时,请编程完成以下指定功能。
① createTable(String tableName, String[]fields)。
创建表,参数 tableName 为表的名称,字符串数组 fields
为存储记录各个域名称的数组。要求当HBase已经存在名为tableName的表的时候,先删除原有的表,再创建新的表。
② addRecord(String tableName, String row, String[]fields,
String[]values)。
向表tableName、行row(用S_Name表示)和字符串数组fields指定的单元格中添加对应的数据
values。其中 fields
中每个元素如果对应的列族下还有相应的列限定符的话,用"columnFamily:column"表示。例如,同时向"Math"“Computer
Science”“English"3列添加成绩时,字符串数组fields为{“Score:Math”,“Score:Computer
Science”,“Score:English”},数组values存储这3门课的成绩。
③ scanColumn(String tableName, String column)。
浏览表 tableName 某一列的数据,如果某一行记录中该列数据不存在,则返回
null。要求当参数column为某一列族名称时,如果底下有若干个列限定符,则要列出每个列限定符代表的列的数据;当参数column为某一列具体名称(如"Score:Math”)时,只需要列出该列的数据。
④ modifyData(String tableName, String row, String column)。
修改表tableName,行row(可以用学生姓名S_Name表示),列column指定的单元格的数据。
⑤ deleteRow(String tableName, String row)。
删除表tableName中row指定的行的记录。
实验内容
4.1 安装hbase
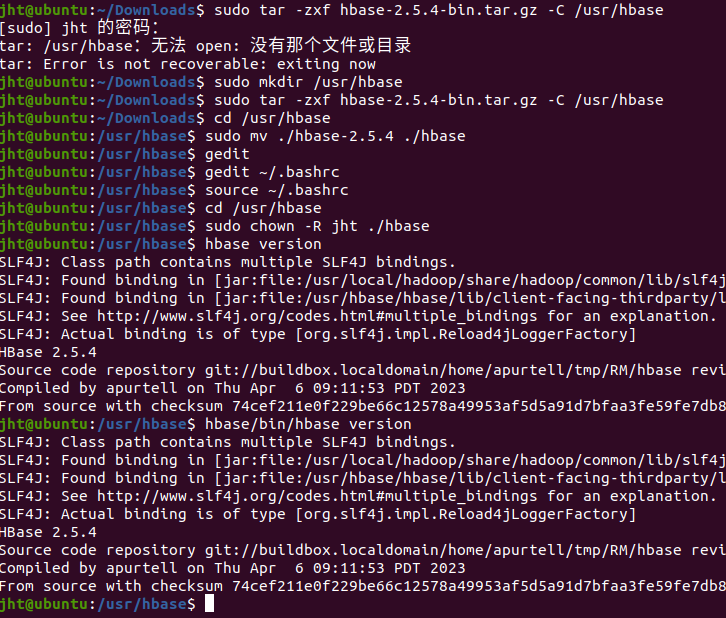
下载安装包后,放置在documents文件夹下。解压到/usr/hbase文件夹。
sudo tar hbase-2.5.4-bin.tar.gz -C /usr/hbase
cd /usr/hbase
sudo mv ./hbase-2.5.4 ./hbase
下面把hbase目录权限赋予给jht用户
cd /usr/hbase
sudo chown -R jht./hbase
配置环境变量
gedit ~/.bashrc
export PATH=$PATH:/usr/hbase/hbase/bin
source ~/.bashrc
(后面为了方便,把hbase位置移动到了/usr/local文件夹下)
配置/usr/local/hbase/conf/hbase-env.sh
。配置JAVA环境变量,并添加配置HBASE_MANAGES_ZK为true,用vi命令打开并编辑hbase-env.sh,命令如下:
vim /usr/local/hbase/conf/hbase-env.sh
在里面添加:
export JAVA\_HOME=/usr/lib/jvm/jdk1.8.0\_371
export HBASE\_MANAGES\_ZK=true
配置/usr/local/hbase/conf/hbase-site.xml
打开并编辑hbase-site.xml,命令如下:
vim /usr/local/hbase/conf/hbase-site.xml
在启动HBase前需要设置属性hbase.rootdir,用于指定HBase数据的存储位置,因为如果不设置的话,hbase.rootdir默认为/tmp/hbase-${user.name},这意味着每次重启系统都会丢失数据。此处设置为HBase安装目录下的hbase-tmp文件夹即(/usr/local/hbase/hbase-tmp),添加配置如下:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
定符代表的列的数据;当参数column为某一列具体名称(如"Score:Math”)时,只需要列出该列的数据。
④ modifyData(String tableName, String row, String column)。
修改表tableName,行row(可以用学生姓名S_Name表示),列column指定的单元格的数据。
⑤ deleteRow(String tableName, String row)。
删除表tableName中row指定的行的记录。
实验内容
4.1 安装hbase
下载安装包后,放置在documents文件夹下。解压到/usr/hbase文件夹。
sudo tar hbase-2.5.4-bin.tar.gz -C /usr/hbase
cd /usr/hbase
sudo mv ./hbase-2.5.4 ./hbase
下面把hbase目录权限赋予给jht用户
cd /usr/hbase
sudo chown -R jht./hbase
配置环境变量
gedit ~/.bashrc
export PATH=$PATH:/usr/hbase/hbase/bin
source ~/.bashrc
(后面为了方便,把hbase位置移动到了/usr/local文件夹下)
配置/usr/local/hbase/conf/hbase-env.sh
。配置JAVA环境变量,并添加配置HBASE_MANAGES_ZK为true,用vi命令打开并编辑hbase-env.sh,命令如下:
vim /usr/local/hbase/conf/hbase-env.sh
在里面添加:
export JAVA\_HOME=/usr/lib/jvm/jdk1.8.0\_371
export HBASE\_MANAGES\_ZK=true
配置/usr/local/hbase/conf/hbase-site.xml
打开并编辑hbase-site.xml,命令如下:
vim /usr/local/hbase/conf/hbase-site.xml
在启动HBase前需要设置属性hbase.rootdir,用于指定HBase数据的存储位置,因为如果不设置的话,hbase.rootdir默认为/tmp/hbase-${user.name},这意味着每次重启系统都会丢失数据。此处设置为HBase安装目录下的hbase-tmp文件夹即(/usr/local/hbase/hbase-tmp),添加配置如下:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-ebdleCpP-1713335973843)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 5993
5993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









