








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
- [3.4.3 PROPERTIES](#343_PROPERTIES_179)
- [3.4.4 ENGINE](#344_ENGINE_205)
- [3.4.5 其他](#345__209)
+ [后记](#_213)
3.4 数据划分
以 3.3.2 的建表示例来理解。
3.4.1 列定义
以 AGGREGATE KEY 数据模型为例进行说明。更多数据模型参阅 Doris 数据模型。 列的基本类型, 可以通过在 mysql-client 中执行 HELP CREATE TABLE; 查看。
AGGREGATE KEY 数据模型中, 所有没有指定聚合方式(SUM 、REPLACE 、MAX、 MIN) 的列视为 Key 列。而其余则为 Value 列。
定义列时, 可参照如下建议:
➢ Key 列必须在所有 Value 列之前。
➢ 尽量选择整型类型。因为整型类型的计算和查找比较效率远高于字符串。
➢ 对于不同长度的整型类型的选择原则,遵循够用即可。
➢ 对于 VARCHAR 和 STRING 类型的长度,遵循 够用即可。
➢ 所有列的总字节长度(包括 Key 和 Value)不能超过 100KB。
3.4.2 分区与分桶
Doris 支持两层的数据划分。第一层是 Partition,支持 Range 和 List 的划分方式。第二 层是 Bucket (Tablet), 仅支持 Hash 的划分方式。
也可以仅使用一层分区。使用一层分区时,只支持 Bucket 划分。
3.4.2.1 Partition
➢ Partition 列可以指定一列或多列。分区类必须为 KEY 列。多列分区的使用方式在
后面介绍。
➢ 不论分区列是什么类型, 在写分区值时, 都需要加双引号。
➢ 分区数量理论上没有上限。
➢ 当不使用 Partition 建表时,系统会自动生成一个和表名同名的,全值范围的
Partition。该 Partition 对用户不可见, 并且不可删改。
- Range 分区
分区列通常为时间列,以方便的管理新旧数据。不可添加范围重叠的分区。 Partition 指定范围的方式
⚫ VALUES LESS THAN (…) 仅指定上界,系统会将前一个分区的上界作为该分区的
下界,生成一个左闭右开的区间。分区的删除不会改变已存在分区的范围。删除分 区可能出现空洞。
⚫ VALUES […) 指定同时指定上下界, 生成一个左闭右开的区间。
通过 VALUES […) 同时指定上下界比较容易理解。这里举例说明,当使用 VALUES LESS THAN (…) 语句进行分区的增删操作时, 分区范围的变化情况:
(1) 如上 expamle_range_tbl 示例, 当建表完成后,会自动生成如下 3 个分区:

(2) 增加一个分区 p201705 VALUES LESS THAN (“2017-06-01”) ,分区结果如下:

(3) 此时删除分区 p201703 ,则分区结果如下:

注意到 p201702 和 p201705 的分区范围并没有发生变化, 而这两个分区之间, 出现了 一个空洞:[2017-03-01, 2017-04-01)。即如果导入的数据范围在这个空洞范围内,是无法导 入的。
(4) 继续删除分区 p201702 ,分区结果如下:
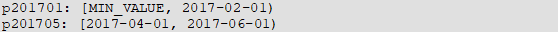
空洞范围变为: [2017-02-01, 2017-04-01)
(5) 现在增加一个分区 p201702new VALUES LESS THAN (“2017-03-01”),分区结果
如下:

可以看到空洞范围缩小为:[2017-03-01, 2017-04-01)
(6)现在删除分区 p201701,并添加分区 p201612 VALUES LESS THAN (“2017-01-01”),
分区结果如下:

即出现了一个新的空洞: [2017-01-01, 2017-02-01)
- List 分区
分 区 列 支 持 BOOLEAN, TINYINT, SMALLINT, INT, BIGINT, LARGEINT, DATE,
DATETIME, CHAR, VARCHAR 数据类型,分区值为枚举值。只有当数据为目标分区枚举值
其中之一时,才可以命中分区。不可添加范围重叠的分区。
Partition 支持通过 VALUES IN (…) 来指定每个分区包含的枚举值。下面通过示例说明, 进行分区的增删操作时, 分区的变化。
(1) 如上 example_list_tbl 示例, 当建表完成后,会自动生成如下 3 个分区:

(2) 增加一个分区 p_uk VALUES IN (“London”),分区结果如下:

(3) 删除分区 p_jp ,分区结果如下:

3.4.2.2 Bucket
(1) 如果使用了 Partition,则 DISTRIBUTED … 语句描述的是数据在各个分区内的划 分规则。如果不使用 Partition ,则描述的是对整个表的数据的划分规则。
(2) 分桶列可以是多列,但必须为 Key 列。分桶列可以和 Partition 列相同或不同。
(3) 分桶列的选择,是在 查询吞吐 和 查询并发 之间的一种权衡:
① 如果选择多个分桶列,则数据分布更均匀。
如果一个查询条件不包含所有分桶列的等值条件,那么该查询会触发所有分桶同时 扫描,这样查询的吞吐会增加,单个查询的延迟随之降低。这个方式适合大吞吐低并发 的查询场景。
② 如果仅选择一个或少数分桶列,则对应的点查询可以仅触发一个分桶扫描。
此时,当多个点查询并发时, 这些查询有较大的概率分别触发不同的分桶扫描, 各 个查询之间的 IO 影响较小(尤其当不同桶分布在不同磁盘上时) ,所以这种方式适合 高并发的点查询场景。
(4) 分桶的数量理论上没有上限。
3.4.2.3 使用复合分区的场景
以下场景推荐使用复合分区

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
-1715724389431)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









