







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
二,更新apt和安装vim编辑器
登录到Hadoop用户之后,我们需要更新一下apt,确保可以安装一些软件。
sudo apt-get update
完成之后直接安装vim文本编辑器
sudo apt-get install vim -y
三,安装配置ssh
输入命令直接下载ssh
sudo apt-get install openssh-server -y
完成之后登录本机
ssh localhost
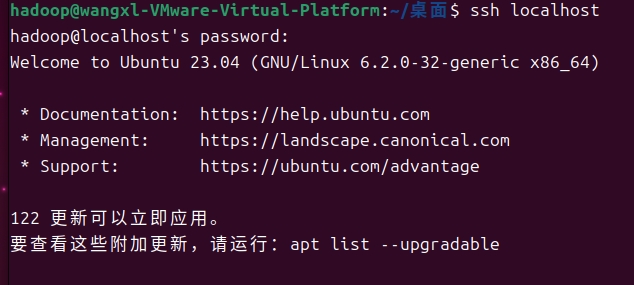
出现提示后输入‘yes’,然后输入密码就可以登录到本机了。我们需要将ssh设置成无密码的,输入命令exit退出,然后利用ssh-keygen生成密钥( 遇到提示一直按回车),并将密钥加入授权。具体命令如下。
cd ~/.ssh/
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys
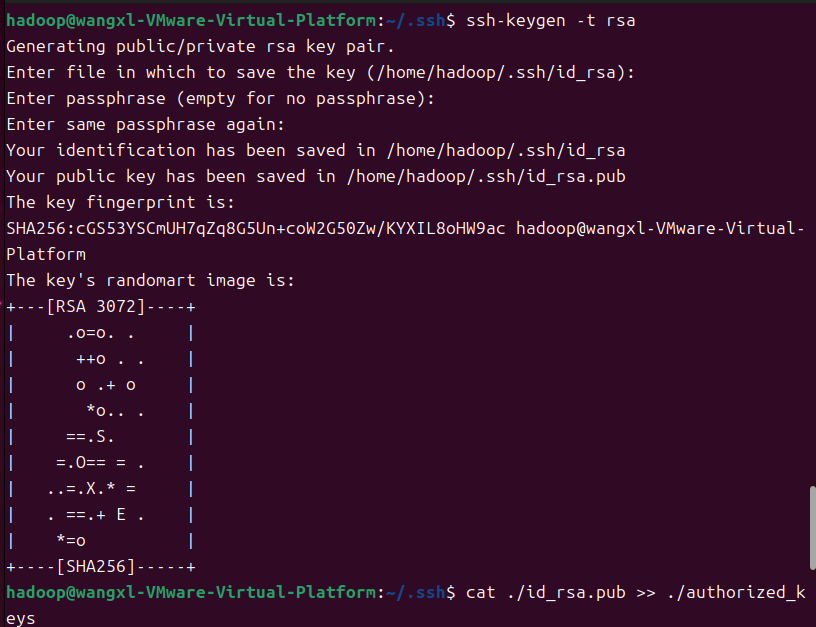
之后输入ssh localhost 就可以直接登录了。
四,安装java环境
使用命令直接下载java
sudo apt-get install openjdk-8-jdk -y
查看是否安装成功
java -version

有这个界面就说明安装成功。
然后进行配置java环境变量,使用vim打开配置文件
vim ~/.bashrc
进去之后输入i,进入输入模式,在第一行添加如下内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64

然后按esc,再输入shift+:进入到末行模式,输入wq保存退出。
继续执行如下命令让.bashrc文件生效
source ~/.bashrc
五,安装hadoop
打开Ubuntu的火狐浏览,输入hadoop下载链接,下载hadoopApache Hadoop https://hadoop.apache.org/release/3.3.6.html
https://hadoop.apache.org/release/3.3.6.html
点击这个链接直接下载
下载完成之后一般会在/home/hadoop/下载 目录下,直接解压出来到/usr/local目录下。
sudo tar -zxf /home/hadoop/下载/hadoop-3.3.6.tar.gz -C /usr/local
将目录名改为hadoop
sudo mv /usr/local/hadoop-3.3.6/ /usr/local/hadoop
修改目录权限
sudo chown -R hadoop /usr/local/hadoop
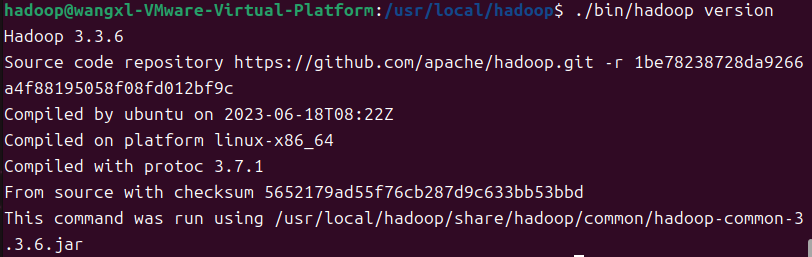
查看hadoop版本信息
cd /usr/local/hadoop
./bin/hadoop version
现在可以运行Grep实例来检测一下hadoop是否安装成功。
首先新建input目录
mkdir input
将配置文件复制到input目录下
cp ./etc/hadoop/*.xml ./input
接下来运行代码grep实例
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
最后执行以下命令查看输出数据
cat ./output/*

六,hadoop伪分布式安装
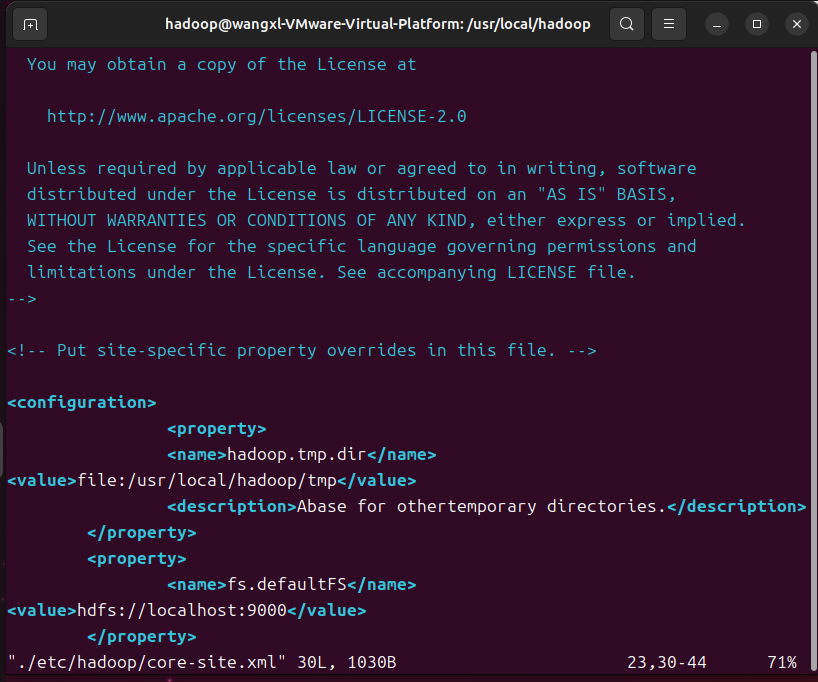
这里需要修改两个文件,先修改core-site.xml 文件
vim ./etc/hadoop/core-site.xml
将下面这些代码添加到中间,然后保存退出
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for othertemporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
修改配置hdfs-site.xml文件
vim ./etc/hadoop/hdfs-site.xml
同样将下面这些代码添加到中间,然后保存退出
<property>
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
<property>
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-g2cOJReZ-1713156344978)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 819
819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









