







+ [3.4.汇编语言格式](#34_238)
+ [3.5.好的指令集的特点](#35_282)
处理器是IT、通信、电子产业的基石 处理器的客户是程序员,程序员在处理器上开发程序,对处理器了解得越深,编写出来的代码执行效率就越高
摘要
本篇博客参考万木杨于2011出版的《大话处理器》,对其主要内容进行总结,以便加深理解和记忆
写在前面
作为一名计算机专业的硕士研究生读这本科普类的处理器基础知识读本,属实有些不好意思。不过不得不说,对我个人而言,现在读这本书不是相见恨晚,而是恰逢其时。它将我近年学到的书本知识和实践经验串成了一条线,让我从自身情况出发,对计算机的一些知识、学习方向和行业发展有了直观而深刻的认识。
这本书是一本非常好的书,它没有拘泥于复杂的系统设计,而是生动简洁地介绍了以处理器为核心的计算机的很多原理,作者还很有文学艺术,引用了很多发人深省的名言,可以从中看出他的人生哲学。

1. 计算机简介
计算机不是一个科学发现,而是一个科学和工程结合的系统工程
1.1.计算机发展简史
-
起源
- 法国帕斯卡发明了加法器
- 德国莱布尼茨发明了乘法器
- 全套运算:计算器(计算机相比于计算器,最大的不同在于它的程序思想)
- 法国亚卡尔制造了一台织布机,打孔控制技术,机器可以根据卡片上打孔设计织物的花样
- 英国人巴贝奇 差分机(制表) → 分析机(机械式 存储库 运算室 分支控制) ”不管今天怎样被认为是无用的知识,到后世会变成大众的知识,这就是知识的生命力“
- 爱达(拜伦的女儿 母亲数学家)第一位程序员(女) 创造了子程序、循环的概念 美国防部开发了一种面向对象的高级编程语言,并命名为ADA(爱达)
-
落地与军用
- 美国哈弗博士生 艾肯 机电方式代替机械方式构造分析机 研制出 MarkI机电式计算机
- 图灵:用理论证明计算机可行的第一人 《论可计算数及其在判定问题中的应用》描述了一项计算任务如何用一种计算机完成 图灵测试
- ABC → ENIAC(毛奇莱) → EDVAC(冯诺依曼机 ”如果人们不相信数学很简单,只是因为他们没有认识到生活有多复杂“)
-
民用
- IBM(国际商业机器公司)诞生:前身是制表公司,后在朝鲜战争时研制701大型计算机而站起,擅机械精密制造,20C50-70S在全球计算机行业中处于霸主地位(服务器、处理器、芯片制造领域前列),现转信息服务业
- DEC小型计算机兴起
-
个人计算机兴起
- Intel诞生:“晶体管之父”肖克利 在硅谷建立“肖克利半导体实验室” → 硅谷八叛将成立仙童半导体(发明集成电路 平面处理技术)→ 其中两人创建intel(乔布斯:仙童半导体公司就像个成熟了的蒲公英,你一吹它,这种创业精神的种子就随风四处飘扬了”)
- Gordon Moore:摩尔定律
- Andy Grove:“唯惶恐者才能生存”——任正非
- MITS公司的创始人发明了世界上第一台PC机Altair
- 微软诞生:比尔盖茨主动为Altair开发软件,开发出BASIC编译器,遂退学创业,开创微软
- 苹果诞生:乔布斯兄弟和好友成立苹果公司,发明个人计算机
- IBM采用Intel的8088处理器和微软的MS-DOS操作系统(由购买的QDOS系统改编)开发出自己的个人计算机,IBM-PC,成为个人计算机的代名词。该决策直接导致了微软和Intel后来的成功,这种“开放式”的体系结构,使得大量的克隆产品出现,一批新的公司成长了起来
- 图形用户界面问世
- 苹果借鉴施乐公司的PARC GUI,推出Macintosh(苹果坚决不与IBM-PC兼容)
- 微软在IBM-PC上开发出用户图形界面,win95获得空前成功
- Intel打败摩托罗拉,Macintosh选用的是Motorola的处理器,但由于IBM-PC都采用Intel的处理器,苹果的衰败也开始采用Intel处理器,摩托罗拉彻底退出了通用处理器市场 → Wintel联盟一统江湖(计算机的本质在于可编程)
- Sun公司挑战Wintel:Sun包含整体IT产业链,发明Java可跨平台,提出“网络就是计算机”的概念(云计算)后被Oracle收购
- google挑战Wintel:浏览器成为OS外的又一大用户窗口,Google等公司大力开发基于互联网的服务(软件即服务),为屏蔽OS做铺垫,网络服务对处理器和OS的依赖性越来越弱
- Intel诞生:“晶体管之父”肖克利 在硅谷建立“肖克利半导体实验室” → 硅谷八叛将成立仙童半导体(发明集成电路 平面处理技术)→ 其中两人创建intel(乔布斯:仙童半导体公司就像个成熟了的蒲公英,你一吹它,这种创业精神的种子就随风四处飘扬了”)
-
移动互联网
- 第一代移动通讯系统的终端设备:大哥大(几乎被摩托罗拉公司垄断,模拟时代注重话音质量)
- 第二代移动通信技术(欧洲超美):GSM标准,局端设备供应商:瑞典爱立信,终端设备供应商:芬兰诺基亚(数字时代注重功能便携和外观)
- iPhone与移动互联网:模糊了手机和计算机的界限,APP Store
- 山寨机
1.2.计算机分类
- PC机
- 服务器:和PC机本质上没有多少不同,主要特点有
- 高可靠性,少出故障(7×24小时业务不中断)
- 高可扩展性:硬盘、内存可扩展
- 高吞吐量:单位时间能处理的请求数(并发量)
- 嵌入式计算机:专注于某个特定领域,如通信、工业控制,低功耗、低成本
一般而言:服务器性能 > PC机性能 > 嵌入式性能
1.3.PC机结构

- 处理器CPU:计算机所完成的工作都是由一条一条指令完成的,指令在处理器中执行,计算机的其他部件都是为了配合处理器而存在。所有外部输入的命令都是由处理器处理的
- 存储器
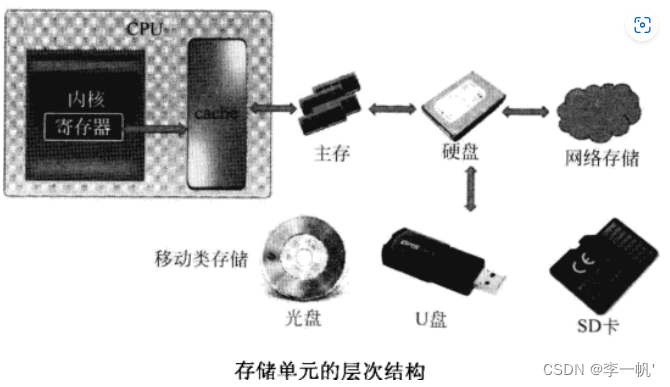
CPU计算时从寄存器中读数据,寄存器容量太小,则需从内存中读数据,为了减少访存速度,在寄存器和内存间增设cache
光盘使用光特性,内存和U盘使用电特性,磁盘使用磁特性
存储器公司:华人王安发明磁芯存储技术 → Intel以存储器起家,发明集成电路存储芯片 → 日本产出高质量的DRAM(内存条使用DRAM颗粒) → 韩国、台湾生产物美价廉的DRAM(三星的手机可以与苹果抗衡,显示器没有公司可以抗衡,存储器没有对手)
-
主板与芯片组
- 主板:承载计算机内部的各部件,提供各种接口
- 芯片组:负责处理器和其他部件间通信
- 北桥:负责处理器与较高通信带宽部件间的通信,主要是内存和显卡(一些处理器Intel Core i7内置内存控制器可与处理器直接通信)
- 南桥:负责处理器与较低速度部件的通信,主要是各种外设
-
外设
- 键盘:QWERTY、DVORAK
- 鼠标:机械鼠标、光电鼠标、无线鼠标、3D鼠标
- 触摸屏、眼睛凝视系统、游戏手柄(虚拟现实、传感器和无线通信设备)、语音输入
- 显示器:2D显示器(CRT、LCD)、3D显示器、数字纸张、多屏、卷轴显示器、投影(越来越大、越来越靓、越来越无形)
-
显卡:连接主机与显示器之间的桥梁(GPU显卡内的处理器)
- 将处理器送来的图像数据处理成显示器认识的格式,再送到显示器成像
- 图像绘制:CPU要画圆时,向GPU发送命令,告诉GPU圆的位置、大小、颜色等信息,GPU负责绘制
- 视频解码
-
通信接口
-
QPI(QuickPath Interconnect):Intel的芯片间点对点互联技术,用于将两个处理器或处理器和南北桥连接起来,它替代了传统的前端总线(Front Side Bus),AMD与之类似的技术叫HyperTransport(HT)
-
PCI/PCI-E
- PCI外部设备互联总线,是一种连接计算机主板和外部设备的总线标准,是一种共享式总线,因此总线上需要有仲裁器
- PCI-E是其升级版,多个设备通信时采用桥的方式,彼此互不干扰
- PC中,显卡、网卡等通过外界板接入到PCI-E插槽中,因此PCI作为板间互联协议。在嵌入式设备中,由于空间大小限制,芯片被直接焊在PCB电路板上,使用PCI连接时,PCI作为芯片间互联协议
- 与PCI-E竞争的高速通信接口还有:嵌入式中的RapidIO等
-
SATA(Serial ATA):串行ATA,硬盘的主要接口,一次只会传输1位数据(传输频率高),从而减少接口引脚和连接电缆数,进而降低系统能耗、减小系统复杂性
-
USB:PC机和外部可拔插设备之间的接口
-
显示器接口
- VGA:较老,传输模拟信号
- DVI(Digital Video Interface):传输数字信号
- HDMI(High Definition Multimedia Interface):高品质同时传输未经压缩的视频和多声道音频数据,线缆可以更长
-

2.初识处理器
2.1.处理器的硬件模型
- 硬连电路(一定终身)
每一种新的运算都需要重新搭建数字电路,如:
out = in1 + in2 * in3 + in4 * in5 * in6;
out = in1 + in2 + in3 + in4 * in5 + in6;

- 通用计算机模型(硬件搭台,软件唱戏)
控制器将存储器中的数据送到算数逻辑单元(ALU,包含加法器、乘法器等实现的基本运算)运算,将结果回存到存储器中。数据放到哪,做什么运算,都由指令告诉控制器
随着集成电路的发展,电路可以在一块很小的芯片上实现,该芯片就叫处理器
2.2.处理器的编程模型
- 计算机发展早期,软件的编写都是直接面向硬件系统的,这个时代软件和硬件紧密耦合,不可分离
- ISA横插一刀:IBM为了增加自己系列计算机的兼容性,引入了指令集体系结构ISA(Instrument Set Architecture)的概念,将编程所需了解的硬件信息从硬件系统中抽象出来,这样编程人员就可以面向ISA进行编程。ISA用来描述编程时用到的抽象机器,这种机器并非具体实现。从编程人员的角度看,ISA包括一套指令集和一些寄存器。程序员知道它们就可以编写程序,可移植到支持ISA的机器上。

Intel和AMD的处理器都是基于X86指令集的,手机多是基于ARM指令集的
2.3.处理器的分层模型
- ISA:架构(Architecture)是处理器的抽象描述
- ISA在处理器的实现:微架构(Microarchitecture),它用于描述处理器是如何实现功能的。同样架构的不同处理器的微架构是不同的(如X86架构的Intel和AMD使用不同的维微架构)
- 物理实现:具体的实现过程,如可以用20nm或40nm的集成电路工艺实现处理器,可以采用电子或量子的方式实现计算机
Architecture就好比需求,Microarchitecture就好比设计,物理实现就好比具体的代码

处理器一般结构:
- 内核:Microarchitecture通常可等同于内核
- 存储器、外设与接口、时钟、电源

2.4.如何选择处理器
-
硬件指标
- 性能
- 时钟基准MIPS/MFLOPS:每秒能执行的M数量级的指令数或浮点数运算数。该数值越高,意味着每秒能执行的指令或运算越多。但由于并行性不强、Cache miss、通信效率、总线冲突等问题,实际执行的指令数或运算数是小于理论值的。该指标是处理器公司最容易给出的指标,也能大致反应处理器的性能,但不能真实反映
- 综合基准:该类基准可以独立于任意类型的计算机进行公平比较(用第三代语言C等编写一个程序在不同系统上运行并记录时间,如Whetstone侧重于浮点运算、Linpack侧重于线性代数程序、Dhrystone侧重于字符串和整数程序(统计某程序1是内能执行的次数,即Dhrystone数))提供了一些依据,但也并不完善
- 专业评估组织基准:SPEC,基准套件程序:CPU套件、嵌入式领域的EEMBC基准
- 功耗:CPU和GPU是功耗大户,散热、制冷(性能和功耗两者最重要,难以同时满足)
- 面积:小
- 接口
- 性能
-
软件指标
- 软件开发环境IDE:方便开发、调试
- 编译器性能:处理器的能力要靠编译器才能体现出来
- 软件兼容性
- 二进制兼容:PC上的应用在每一代的处理器都可以正常运行
- 源代码兼容:PC上的应用的源代码在不同代处理器上重新编译一下可以正常运行
-
商业指标
- 价格(一个东西的价格与其本身的价值关系不大,和市场关系较大。嵌入式芯片市场竞争激烈,价格较低。PC芯片市场竞争缓和,价格较高)
- 芯片成熟度
- 生态环境:OS支持、开发工具支持、应用软件支持、程序员支持
3.指令集体系结构
处理器的外表
重新选择一套指令集,与之配套的编译器、OS、应用软件都需要重新编写
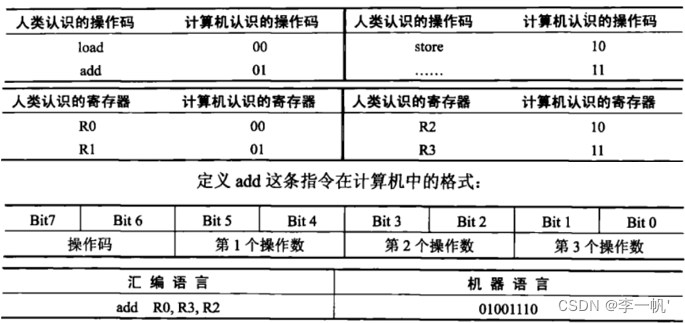
3.1.处理器编程模型

lw R15, 0(R2) # 将内存地址0(R2)处取值存入R15寄存器中
lw R16, 4(R2) # 将内存地址4(R2)处取值存入R16寄存器中
sw R16, 0(R2) # 将R16寄存器取值存入内存0(R2)中
sw R15, 4(R2) # 将R15寄存器取值存入内存4(R2)中
3.2.指令集发展历程
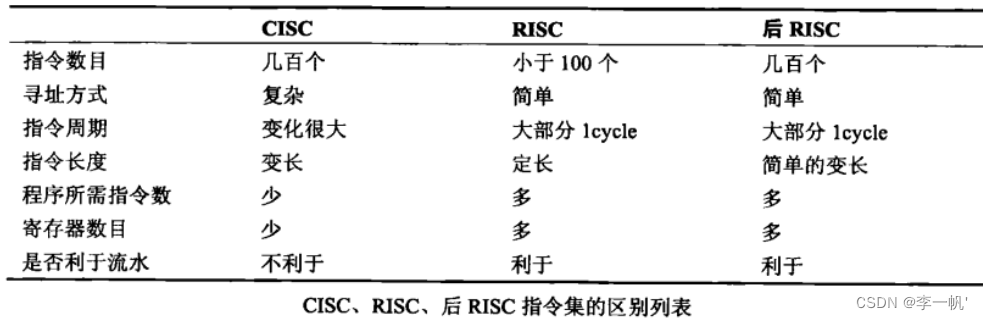
- CISC时代:Complex Instruction Set Computer复杂指令集计算机,指令集强大、灵活、一条指令能完成很多功能,能减少访存次数,变长指令集,其代表是Intel的X86指令集
- RISC时代:仅保留常用简单的指令,大多指令可以在一个时钟周期内完成,处理器频率得到大幅提高,可以更好的实现流水线。采用定长编码,译码过程简单.RISC也有一些缺点,就是指令划分太精细,造成访存次数增多
- 后RISC时代:RISC处理器通过更合理的微架构,在性能上超越CISC。Intel不甘示弱,设计了新的处理器,X86指令会先被解码为类似于RISC的微操作,执行过程采用RISC内核,达到了性能和兼容性的统一
3.3.指令集分类
- X86:属于CISC指令集,Intel出品,开放给AMD。几乎所有的PC机都采用X86指令集,因而PC市场被Intel和AMD垄断,后入侵占领了服务器市场。(硕大的大象)
- ARM:属于RISC指令集,使用ARM指令集的处理器销量最大,来自英国的公司,占据了手机处理器的市场,具有低能耗、低成本的特点。ARM公司不生产指令集,而是向半导体公司提供指令集、内核授权,其他公司使用ARM的处理器内核生产自己的处理器芯片,主要面向嵌入式市场。(稳扎稳打的蚁群)
- MIPS:Microprocessor without Interlocked Piped Stages无内部互锁流水级的微处理器,最经典的RISC指令集,被称为处理器的教科书,学术价值高。和ARM的商业模式类似,在通信领域有一定市场份额(优雅的孔雀)
- Power:IBM推出的高性能指令集(Performance Optimized With Enhanced RISC), IBM的POWER和PowerPC侧重于服务器、游戏机领域,在PC领域缺乏应用软件支持(昔日的贵族)
- C6000:DSP数字信号处理器,专在视频网站、视频通信的无线通信网络建设的背景(无线通信技术、音视频技术)下做数字信号处理,相比于上述的通用处理器,它是一种专用处理器(偏安一隅的独立王国)
3.4.汇编语言格式
-
机器字长:处理器一次处理数据的长度,主要由运算器、寄存器决定,如32位处理器,每个存储器可以存32bit数据,加法器支持两个32bit数相加。32位处理器的地址总线通常也是32位,数据总线一般长于机器字长,因而一次可以读取更多数据
-
操作数个数
- X86处理器的寄存器(操作数)个数一般是2个,源和目的操作数共用一个寄存器,后来又扩充了一些SSE指令,包含3个操作数(1个源操作数,1个目的操作数,1个掩码)
- RISC指令集基本都使用了3个操作数(2个源操作数,1个目的操作数)
-
操作数顺序
- X86:目的操作数在前,源操作数在后
ADD BX AX; # 将BX和AX相加,结果存到BX中
+ C6000 DSP:源操作数在前,目的操作数在后
ADD A1, A2, A3; # A1和A2相加,结果存到A3
+ MIPS:目的操作数在前,源操作数在后
- 大小端:Intel的X86采用小端字节序,很多处理器可以配置成大端或小端

-
指令类型
- 算数逻辑指令(乘法、加法、移位等)
- 控制指令(跳转指令和条件跳转指令):实现循环(跳回去实现循环)和分支
- 数据传送指令:X86指令集中,操作数可以是寄存器也可以是存储器。RSIC指令集中,操作数只能是寄存器
-
寻址方式
-
RISC:立即数、寄存器寻址、存储器寻址

-
X86寻址方式复杂,不过内部可以转换成类RISC的许多微指令
-
3.5.好的指令集的特点
- 兼容性:新一代处理器的指令集要兼容上一代的指令集
- 易实现:指令定义的功能,在处理器上易于实现
- 易编程:编程人员容易使用该指令集进行编程
- 高性能:指令集设计合理,程序指令效率高
4.微架构
4.1.处理器流水线
-
概念
- 节拍:事务可划分的步骤,不同步骤可以并行执行,只是时间维度上有所错位
- 流水线级数:节拍的数量(事务可细分的数)在不可考虑其他因素的情况下,流水线级数越多,工作效率越高
- 流水线的效率:不同节拍间的时间差异会影响流水线的效率,差异越大流水线的效率通常越低

-
处理器的设计也采用多级流水线的设计,指令执行的过程也可以划分为多个节拍
-
3级流水线:取指、译码、执行(ARM7)
-
5级流水线
- 处理器内部有很多通用寄存器,用以存储指令的操作数,该寄存器对程序员可见,如X86有8个通用寄存器,RISC有32或64个,通用寄存器也被称为寄存器堆Register file
- 在流水线设计中,为了确保不同流水线节拍不会相互影响,在每个阶段引入流水线寄存器来分割各个流水线节拍
- 在汇编语言中,算逻单元会直接访问通用寄存器进行运算,在物理实现中,通用寄存器中的数据会被先读到流水线寄存器中,即ALU的输入寄存器,ALU运算结束后,数据会存储到ALU的输出寄存器,最后再送回通用寄存器中

- 因此,指令的执行过程又可以细分为3个子节拍:从寄存器堆中读寄存器值,进行运算,将结果回写到寄存器堆中。由此处理器执行指令的过程可以划分为5个节拍,形成5级流水线(早期的MIPS、ARM9等处理器都使用这种流水线,后续的包括X86的处理器设计都可以看到这种设计的影子)

-
更深的流水线:如C6000 DSP处理器将3个步骤细分成了更多的小节拍
-
-
流水线冒险:导致流水线出现停顿的因素
- 结构冒险:由处理器资源冲突,而无法实现某些指令的组合。如早期的处理器指令和数据都存储在内存中,取指和读写数据都需要访存,这就可能导致一个操作需要等待
- 数据冒险:流水线使原本先后执行的指令同时处理,当出现某些指令的组合时,可能会导致指令使用错误的数据(内存也会有这样的问题)

- 解决方法:延时cycle,在两条指令间增加周期等待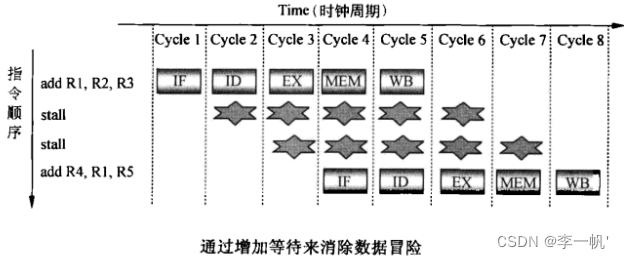
- 解决方法:直通Forwarding。通过硬件检测当前指令的源操作数在EX/MEM流水线寄存器中时,就直接将该寄存器的值传递给ALU的输入寄存器,而不是从寄存器堆中读数据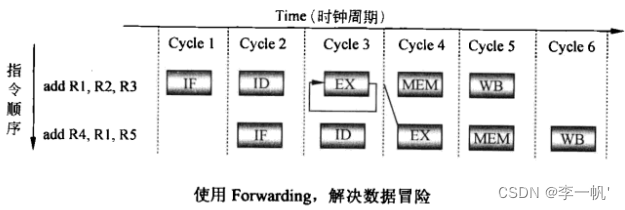
-
控制冒险:由于程序中的跳转,程序的实际执行路径会发生更改,那么流水线中做的取值和译码工作就白做了(跳转对程序性能的损失是很大的,流水线越深,损失越大)
- x86处理器使用硬件冲刷流水线来保证发生跳转时,流水线能正确执行
- DSP硬件不处理这些冒险,由软件处理,通过增加NOP来排空流水线
-
分支预测:提前预测一条跳转指令是否会真的发生跳转,以及它的目标地址,就可以明确程序的执行路径,可以修改程序指针,提前控制流水线从正确的地方开始取指,这样流水线的效率就能有很大的提升
-
分支预测算法
- 1位预测:如果当前的跳转指令上次就发生了一次跳转,就预测此次也会发生跳转(容易翻转)
- 2位预测:跳转1次加1(最大为3),未跳转减1。0、1不跳转,2、3跳转
- 分支预测实现(Intel分支预测模块)
- Branch Target Buffer(BTB):记录跳转语句的跳转情况

- The Static Predictor:静态预测器,在BTB中未记录跳转语句信息时使用,是人为总结出的经验规律:向下跳转预测为不跳转,向上跳转预测为跳转(向上通常是循环)
- Return Stack:函数调用时将函数的返回地址压栈到Return Stack返回栈中,当遇到函数返回指令时就从返回栈中取址
-
条件执行:分支预测会消耗大量的资源,很多低能耗的处理器没有分支预测,如TI DSP(不擅长处理复杂的控制代码),它采用指令的条件执行来减少跳转指令

-
4.2.处理器乱序执行
-
为何乱序执行:指令在执行时常常因为一些限制而等待,乱序执行可以让处理器先执行后面不依赖于该数据的指令
-
指令的相关:指令之间的相关和依赖会导致指令无法乱序执行
- 寄存器相关:两条指令共用寄存器时,可能产生寄存器相关
- 读读:寄存器不相关
- 写读、读写(反相关):数据相关,乱序执行可能会导致读数据错误
- 写写:名字相关,也称伪相关,两个写操作实际没有逻辑依赖,只是由于通用寄存器较少,两条指令的写结果共用了一个寄存器
- 控制相关:某指令需要依赖于控制流的结果
- 寄存器相关:两条指令共用寄存器时,可能产生寄存器相关
-
去除指令的相关性
- 通过编译器或编码者去除一定的数据相关
- 通过寄存器重命名的方法去除伪相关,将ISA寄存器映射到更多的实际执行时使用的物理寄存器,对寄存器进行重命名,以去除一定的伪相关

- 通过预测跳转指令的目标地址(投机执行)去除一定的控制相关,预测跳转指令的目标地址,并提前执行后续的分支指令,如果预测错误则丢弃结果,或多条分支路径都预执行(Eager execution)
-
乱序执行过程:顺序发射,乱序执行,顺序提交
- 指令Buffer
- 指令调度:指令执行的的时机
- 指令顺序提交、重排缓冲区ROB(实现精准中断)

4.3.处理器并行执行
- Flynn分类
- SISD:一次处理一条指令,一条指令处理一份数据(早期处理器)
- SIMD:一次处理一条指令,一条指令处理多份数据(数据并行)
- MISD:一次处理多条指令,多条指令处理一份数据(没实际意义)
- MIMD:一次处理多条指令,多条指令能处理多份数据(指令并行)

-
指令并行:流水线中多条指令已经可以同时执行。若发射单元一次能发射多条指令,更多的指令就能并行处理了,这被称为多发射multi-issue
-
Superscalar:超标量处理器。过去的标量处理器时代,指令都是串行执行的,超标量处理器为了提高程序执行效率并做到兼容,在处理器内部做了指令的并行化处理,即指令的并行化是在运行阶段进行的

-
代表实例:Intel P4 CPU(采用乱序执行的超标量处理器,采用NetBurst微架构)
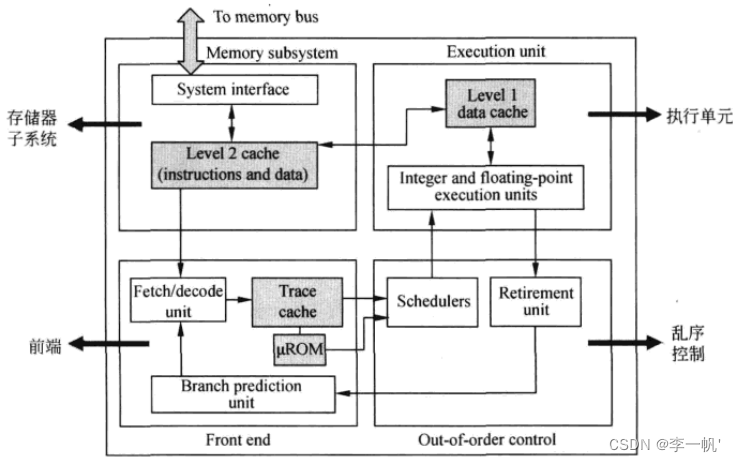
- 存储子系统:包含片内Cache,是处理器内部的存储单元,存储指令和数据 - 前端流水线(负责准备指令)  * 取指:从L2 Cache中读指令,一次读64bit,存储在队列(缓存、隔离节拍)中。读指令时,通过TLB进行指令的虚实地址转换 * 译码 + 译码单元的工作是将x86指令翻译成类似于RISC的微操作uop + 采用预译码的方式解决变长编码多指令的问题,即指令从内存读到Cache中时就开始预解码,得到预译码标识(包括指令的起始位和需要译出的uop数),预译码标识和指令一同存储在指令Cache中 + Intel采用多级译码流水线的方式实现译码,第一级检测指令的起始位,第二级将指令解码为uop + 当一条CISC指令产生的uop数目多于4条时,就将对应的uop存储在micro-ROM(uROM)中,解码时采用查表的方式读码 + 译码后的指令也存储于一个Buffer Queue中 * 按照uop执行的顺序(而非指令顺序)存放在Trace Cache中 * 再从Trace Cache中读uop存储到uop Queue(前后端的桥梁)中 * 注意:运算单元实际指令时,直接从uop Queue中取uop,当uop Queue中没有所需的uop时,才会进行上述的步骤,访存取指 - 后端流水线(负责执行指令) 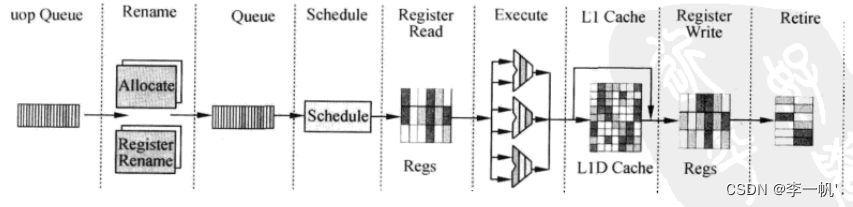 * uop进入后端时,进行资源的分配,为其分配到Buffer(寄存器)中,再被重命名。通用寄存器和物理寄存器的映射关系在RAT中存储 * 指令的调度(Schedule):乱序执行的核心,调度器根据uop操作数的准备情况和执行单元的空闲状态决定uop何时执行。 * 访存指令和ALU运算指令被调度器分配到不同的分牌口Dispatch Ports 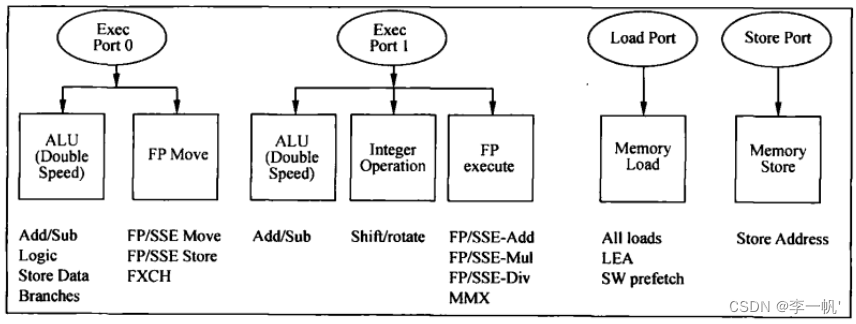 * Register Read、Execute、L1 Cache(MEM)、Register Write(类MIPS5级流水线) * Retire退出:更新ISA寄存器状态,指令按照顺序退出乱序执行内核-
VLIW:指令的并行化由编译器或程序员手工完成,即在编译时完成指令的并行。并行性更好,擅长做密集运算,但不擅处理Cache miss、跳转,顺序执行能耗低
-
DSP的应用:手机中的无线信号处理、语音图像视频信号的处理;多媒体终端;摄像头、基站
-
代表实例:TI C6000 DSP
-
典型的顺序执行单元,指令的执行顺序和并行在指令格式中描述清楚了(成功的关键在于编译器能否将高级语言翻译成并行性好的指令序列)
-
DSP的执行单元由8个单元组成,每个单元可以执行某些类型的运算。拆分成左右两组的设计方式能减少端口数,降低芯片的面积和能耗

-
指令并行性
- 循环展开:将循环按模4进行展开

- 软件流水:将取址、运算、存数以流水方式进行
-
-
-
-
数据并行
-
多媒体应用:语音信号经过8K Hz采样后,1秒钟包含8000个样点,图像在二维上进行采样。多媒体程序的共同特点:同一操作会重复处理多个数据
-
SIMD、MMX、SSE、AVX:高性能处理器基本都包含SIMD指令,Intel逐步推出MMX、SSE、AVX指令集(即具体的SIMD指令集)MMX指令和浮点处理单元FPU指令共用64bit的寄存器,一次可以处理64bit的数据,SSE指令集使用单独的寄存器,一次可以处理128bit的数据(可以是2×64、4×32、8×16数据的组合),AVX指令集可以一次处理256bit的数据
-
SSE指令形式
-
垂直计算形式:X、Y寄存器被看成一个向量,每个标量数据分别运算,这是SIMD指令最常用的计算形式

-
水平计算形式:两个操作数来自于同一个源

-
标量计算形式:垂直形式中,仅有x0和y0进行操作,其他元素不变

-
-
-
线程并行
-
软件多线程(OS):轮询、中断等方式执行不同的线程,上下文切换(ISA寄存器保存线程状态)
-
硬件多线程:在处理器中多开辟几份线程状态,线程切换时,处理器切换到对应的线程状态执行
- 粗粒度:中断切换
- 细粒度:每个cycle轮询不同线程
- 同时多线程STM(Intel 超线程):muti-issue时,多条指令来源于不同线程
-
多核
-
多个核共用处理器的外设与接口(内存控制器、PCI-E等),以及一段Cache
-
多核组织结构:p为核,c为Cache,连线为多核的通信方式

-
Bus:结构简单,两核通信时会发生总线占用,其他核不能通信,通信效率低
-
Switch:通信效率最高,核两两连线,但核心太多时资源消耗大,一般4核时使用
-
Ring:介于Bus和Switch,1、3通信需要经过2,越接近的两个核通信效率越高,连线不复杂成本较低,8核左右时使用
-
Mesh:适合于核数非常多的情况,如众核处理器(64/100),类似于二维的Ring结构,结构简单,易于扩展,通信效率较高
流水线、指令并行、数据并行、线程并行是相互关联的,它们有时只是观察粒度不同
-
-
5.Cache

使用SRAM做Cache
5.1.Cache的时空局部性
- 时间局限性:如果某个数据被访问到,那么在不久的将来它很可能再次被访问(循环)
- 空间局限性:如果某个数据被访问到,那么与它相邻的数据很可能很快被访问(数值、指令)
5.2.Cache的结构
-
Cache的层次和化管理
- 2级结构:L1P L1D是程序和数据分别各自的Cache,L2为两者共享的Cache(L1通常与内存同频,L2通常降频使用,级别越大空间越大)
- 3级结构:L3为多核共享的Cache
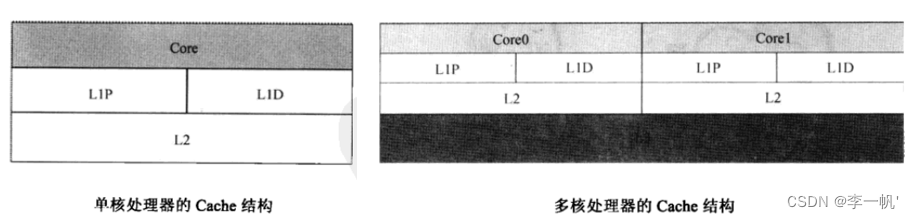
-
Cache hit与Cache miss:整个Cache空间会被分为N个line,每个Cache line通常是32、64byte,是Cache与内存交换数据的最小单位
-
Cache的映射方式:内存的大小要远大于Cache的大小,因此将内存中的数据填充到Cache中是一种多对一的关系
- 全关联Cache(Full-associative Cache):任意内存分块可以映射到任意Cache line中,缺点是判断一个数据是否在Cache中时,需要遍历Cache line,查每一个tag,检索效率低
- 直接映射Cache(Direct-mapped Cache):将内存按Cache大小分为N个Page页,每个Page页和Cache大小相同,每个Page中的line0只能对应于Cache line0。根据地址就能索引到对应的Cache位置,内存地址 % Cache容量 % Cache line num - 0,缺点就是在一些情况下容易造成某一Cache line数据热点,其余Cache line 空闲
- 组关联Cache(Set-asoociative Cache),结合上面两种映射方式,先将Cache划分为多份way,访问时先通过直接映射的方式计算出Cache set,再通过遍历的方式寻找way。way越多检索效率提高,但cache way容量减少,又容易发生cache miss使得检索效率降低,因此way的个数需要平衡
-
Cache的置换策略:Cache已满但Cache miss,如何置换已装入的Cache line,FIFO、Random、LRU…
-
Cache的写方式:CPU改变了Cache的值,如何更新内存对应的数据
- 写通Write through:立即回写
- 写回Write back:不立即回写,在一定时机下(如其他指令要访问内存中的该数据时)再写回(dirty:是否改写、valid:是否有效、tag:内存中的地址标识、block:实际数据)

5.3.Cache一致性问题
多核处理器中,不同核从内存或公共Cache中读取数据保存于各自的Cache中,其中某一核改写了自己Cache中的该数据,另一核不可见
- 解决方法1:Write invalidate:某一核1改变了自己Cache中的数据,设置其他核中的该Cache line为无效,若其他核也使用该数据,则会造成核1回写内存,其他核再从内存中读,保证一致性
- 解决方法2:Write Update:当一内核修改了数据,其他地方若有这份数据的复制,则将其他核都更新到最新值
- Cache一致性协议:MESI协议(监听协议:每个Cache都要监听总线上的所有操作)
5.4.片内可寻址存储器——对程序员可见的Cache
x86处理器中,Cache对程序员透明,一切由物理硬件来管理;DSP等处理器,其内部的处理器一部分可作Cache,另一部分可作为片内寻址存储器,可由程序员通过软件控制DMA(Direct Memory Access)搬运数据,DMA提供了1D、2D、3D的搬运方式(2D是在1D的基础上进行的)

6.编写高效代码
软件性能优化的第一步:调查程序各个模块(函数)的执行时间(可以使用软件性能剖析工具)
6.1.减少指令数
-
使用更快的算法
-
选择合适的指令:在高级语言编程时,编译器通常不会使用一些如乘累加、求绝对值等复杂指令,而是将高级语言编译为多条简单指令,使用相应功能的复杂指令,能够减少指令数量。使用复杂指令最直接的方式是编写汇编语言,但这不符合当前使用高级语言的场景。编译器提供了一种更方便的汇编指令使用方式:Instrument function,如SSE3中的指令
addsubps,其对应的Instrument function用法为:w = _mm_addsub_ps(u,v);,它会被编译器直接翻译成对应的汇编指令 -
降低数据精度
-
减少函数调用
- 小函数直接写成语句
- 将小函数写成宏
#define min(a,b) ((a)<(b)) ? (a):(b)
c = min(a,b);
+ 将函数声明为内联函数:编译器会自动用函数体覆盖函数调用
inline int min(int a,int b){
return a < b ? a: b;
}
- 空间换时间
- 减少过保护(减少可协调的数据校验)
6.2.减少处理器不擅长的操作
单周期指令是处理器最喜欢的,不仅执行时间短,还有利于流水线执行
- 少用乘法
// 适用于乘2的N次方
len = len\*4;
len = len <<2;
- 少用除法、求余
f = f / 5.0
#define cof 1.0/5
f = f \* cof;
- 在精度允许的条件下,将浮点数定点化
e.g. alpha混合,通过两张图像进行半透明混合模拟CS烟雾弹效果
// alpha为透明度,从0-1的小数
pixel_C = (int) (Pixel_A \* alpha + Pixel_B \* (1 - alpha));
// 将alpha定点化为0-32之间的一个整数值
pixel_C = (Pixel_A \* alpha + Pixel_B \* (32-alpha) + 16 ) >>5;
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
[外链图片转存中…(img-MQsro8wP-1713005161823)]
[外链图片转存中…(img-Dpx5JoiC-1713005161824)]
[外链图片转存中…(img-M0Ee1i6M-1713005161825)]
[外链图片转存中…(img-6kLxjJlt-1713005161825)]
[外链图片转存中…(img-8mMynMzy-1713005161825)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-kf5jtTlr-1713005161825)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









