







1.5.3.统一集群管理
- 分布式环境中,实时掌握每个节点的状态是必要的。
- 可根据节点实时状态做出一些调整。
- ZooKeeper可以实现实时监控节点状态变化
- 可将节点信息写入ZooKeeper上的一个ZNode。
- 监听这个ZNode可获取它的实时状态变化。

1.5.4.服务器动态上下线
- 客户端能实时洞察到服务器上下线的变化

1.5.5.软负载均衡
- 在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求

1.6.Zookeeper官网
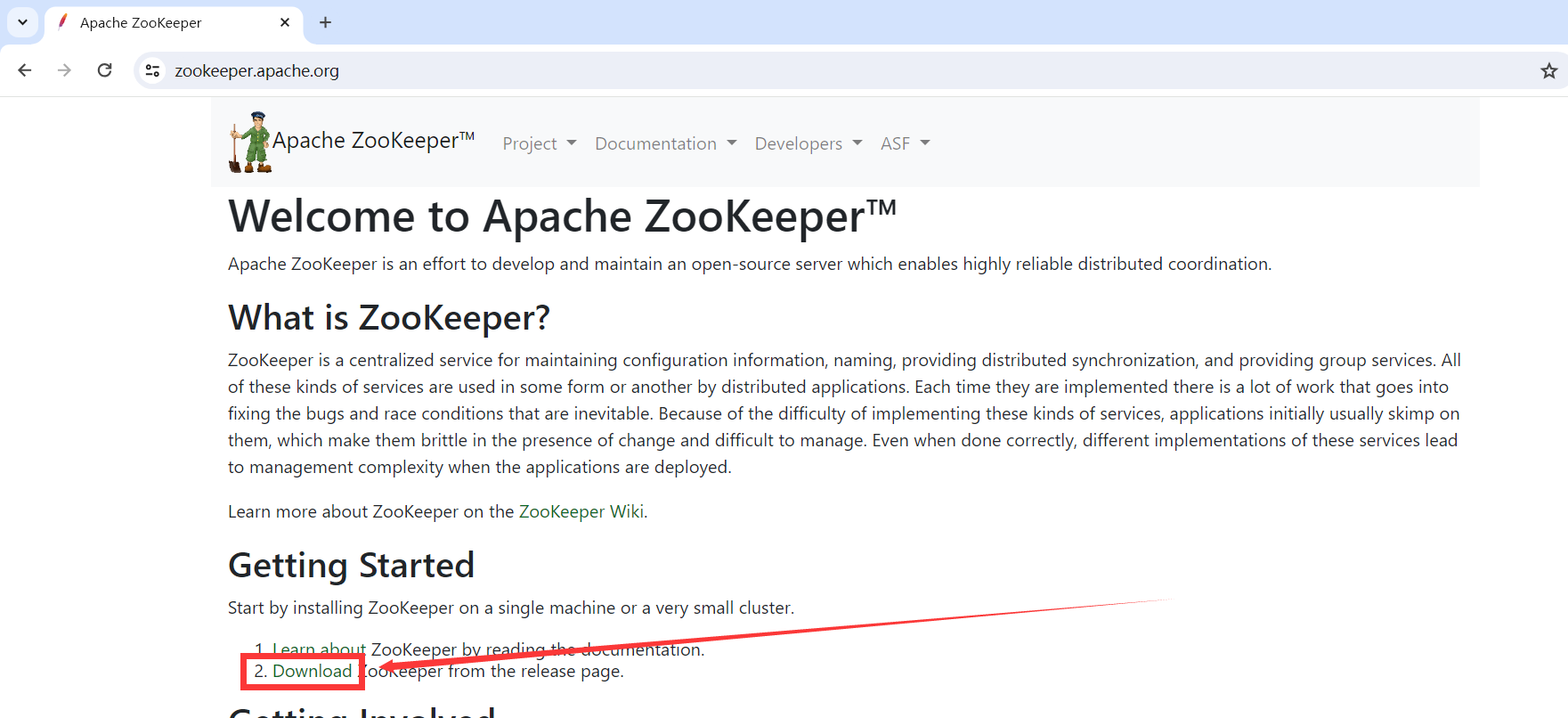
Zookeeper官网:https://zookeeper.apache.org/
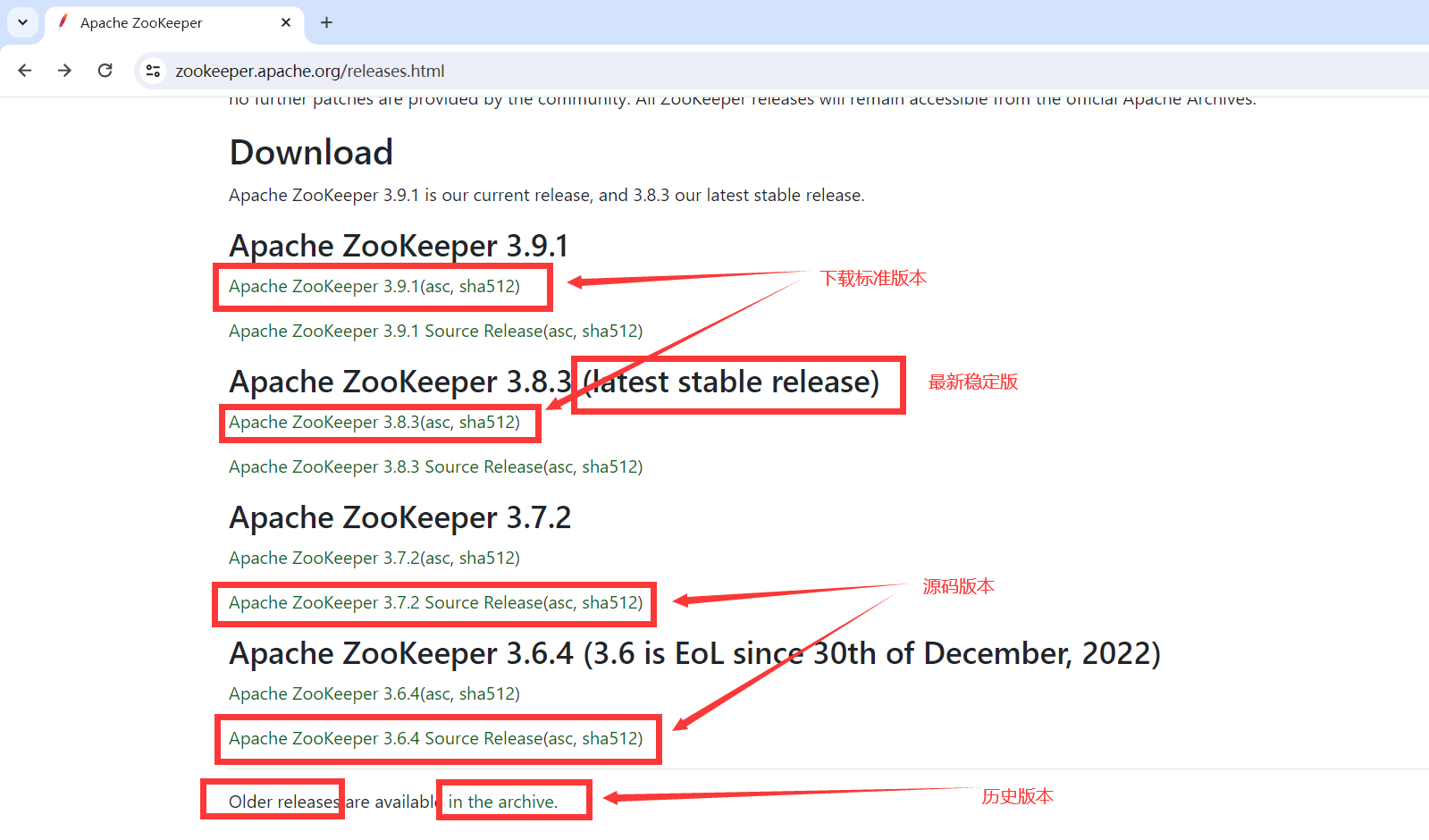
Zookeeper所有版本:https://archive.apache.org/dist/zookeeper/
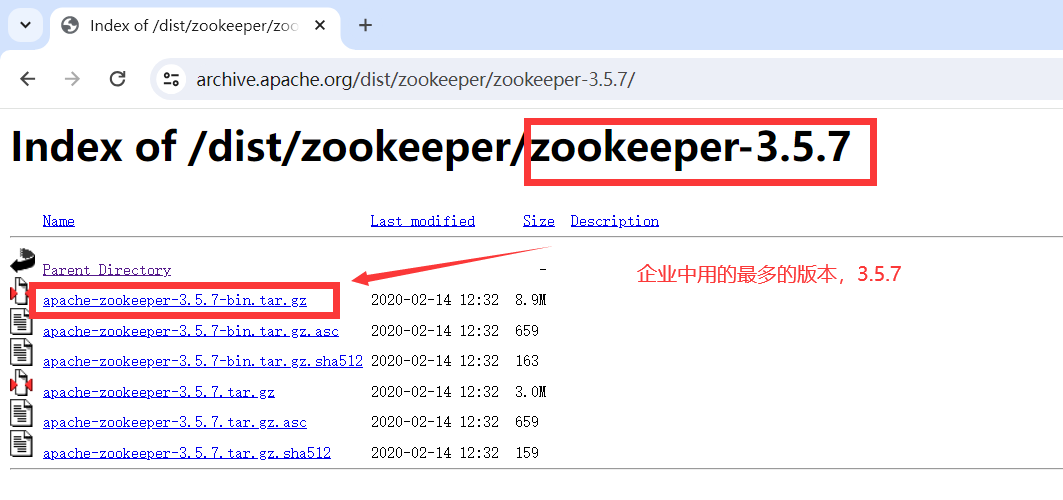
zookeeper-3.5.7:https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/
1.6.1.Zookeeper下载
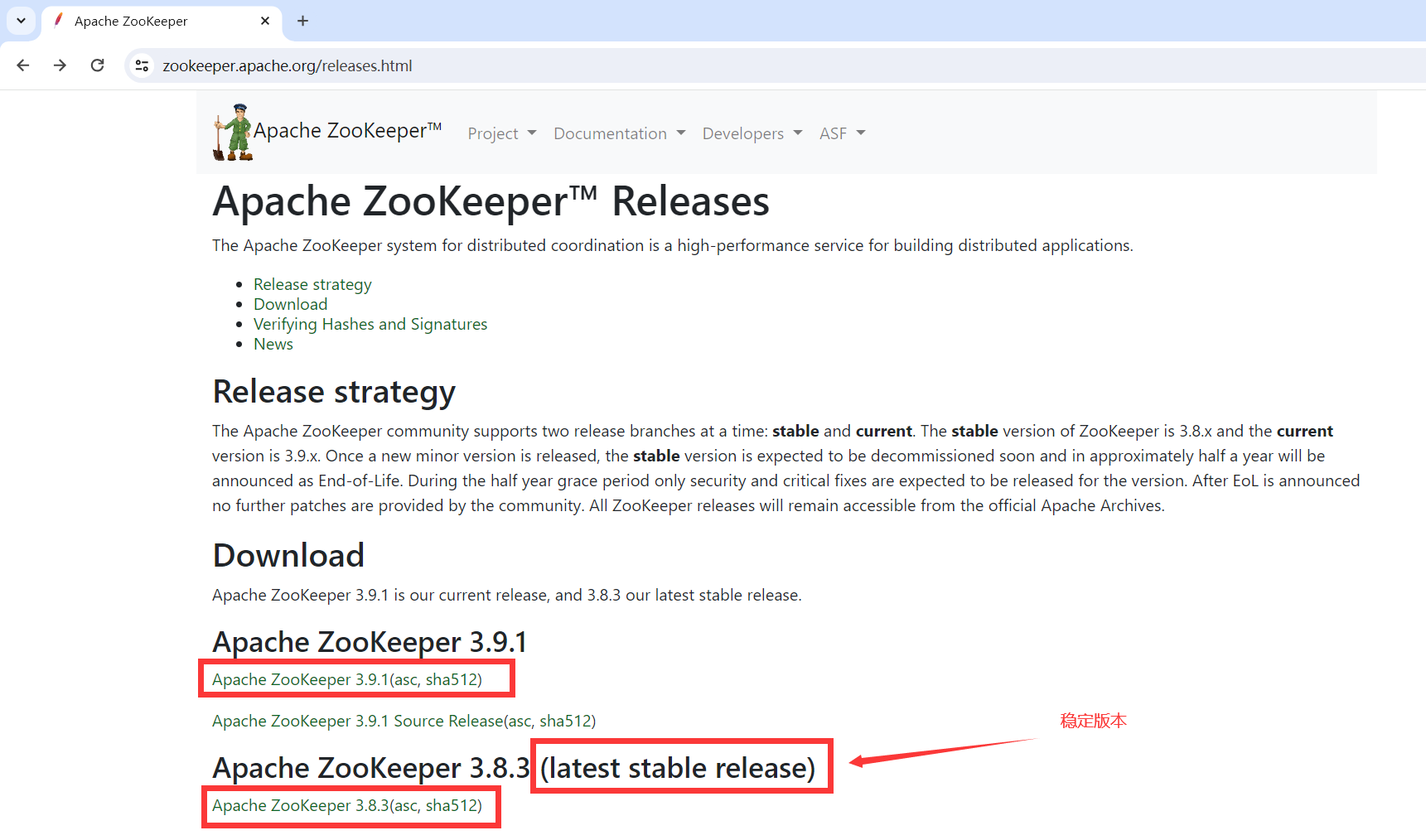
1.6.2.历史版本
1.6.3.下载Linux 环境安装的tar包
二、Zookeeper安装【Centos7】
2.1.环境要求
2.1.1.安装JDK

2.1.2.上传apache-zookeeper-3.5.7-bin.tar.gz 安装包到/opt/module目录下
mkdir -p /opt/module
cd /opt/module
2.1.3.解压到指定目录
tar -xzvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module
2.1.4.修改文件夹名称
cd /opt/module
mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7
2.2.配置修改
2.2.1.将zookeeper-3.5.7/conf 路径下的 zoo_sample.cfg 修改为 zoo.cfg
cd /opt/module/zookeeper-3.5.7/conf
cp zoo_sample.cfg zoo.cfg
2.2.2.修改zookeeper数据文件存放目录
vi /opt/module/zookeeper-3.5.7/conf/zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
2.2.3.创建相关数据文件存放目录
mkdir -p /opt/module/zookeeper-3.5.7/zkData/{logs,data}
2.3.操作Zookeeper
2.3.1.添加到环境变量
vim /etc/profile
zookeeper
export ZK_HOME=/opt/module/zookeeper-3.5.7
export PATH=
P
A
T
H
:
PATH:
PATH:ZK_HOME/bin
输入下面命令让设置的环境变量生效
source /etc/profile
2.3.2.启动Zookeeper
zkServer.sh start
zkServer.sh status
zkServer.sh stop
zkServer.sh restart
#以打印日志方式启动
zkServer.sh start-foreground

2.3.3.查看进程是否启动
jps 是 Java Process Status Tool 的简称,它的作用是为了列出所有正在运行中的 Java 虚拟机进程
每一个 Java 程序在启动的时候都会为之创建一个Jvm 实例,通过jps可以查看这些进程的相关信息
jps是Jdk提供的一个工具,它安装在 JAVA_HOME/bin下
jps
jps -l
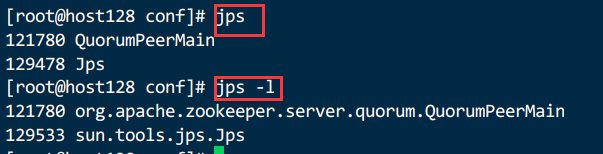
2.3.4.ZooKeeper服务端口为2181,查看服务已经启动
ps -aux | grep zookeeper
netstat -ant | grep 2181

2.3.5.查看状态
zkServer.sh status
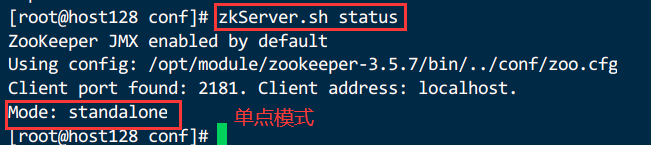
2.3.6.启动客户端
zkCli.sh
2.3.7.退出客户端
quit
2.3.8.停止Zookeeper
zkServer.sh stop
2.3.9.查看数据文件存放目录zkData
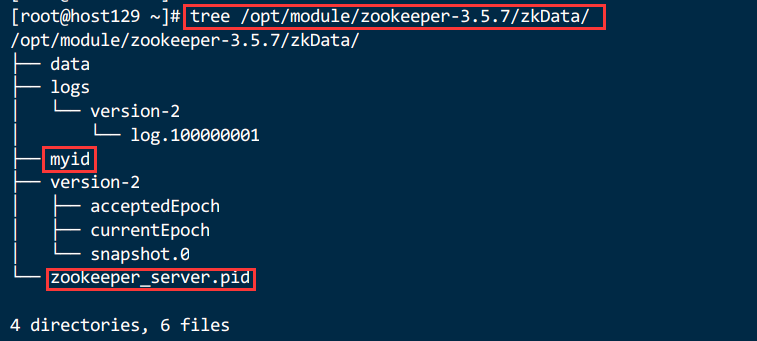
2.4.配置参数解读
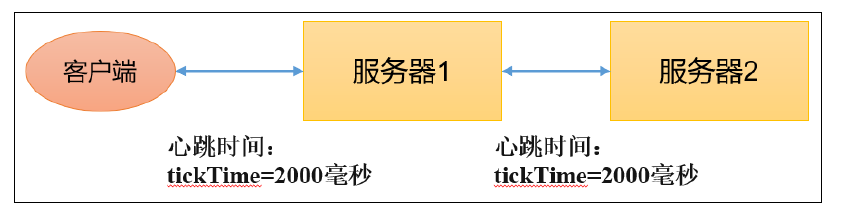
2.4.1.tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
2.4.2.initLimit = 10:LF初始通信时限

Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)
2.4.3.syncLimit = 5:LF同步通信时限

Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死掉,从服务器列表中删除Follwer。
2.4.4.dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
2.4.5.clientPort = 2181:客户端连接端口,通常不做修改
三、Zookeeper 集群操作
3.1.集群操作
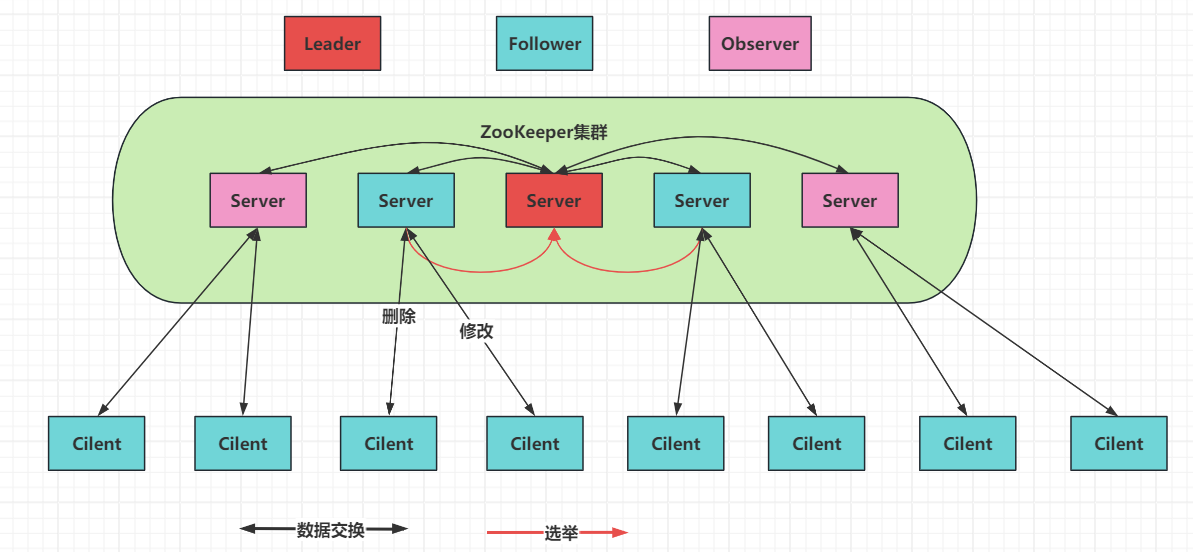
在ZooKeeper集群服中务中有三个角色:
Leader 领导者:
- 处理事务请求
- 集群内部各服务器的调度者
Follower 跟随者:
- 处理客户端非事务请求,转发事务请求给Leader服务器
- 参与Leader选举投票
Observer 观察者:
- 处理客户端非事务请求,转发事务请求给Leader服务器
3.1.1.集群安装
3.1.1.1.集群规划
在host128、host129 和host130 三个节点上都部署Zookeeper
思考:如果是 10 台服务器,需要部署多少台 Zookeeper?
3.1.1.2.解压安装
解压Zookeeper 安装包到/opt/module/目录下
tar -xzvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module
cd /opt/module
修改apache-zookeeper-3.5.7-bin 名称为zookeeper-3.5.7
mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7
3.1.1.3.配置服务器编号
3.1.1.3.1.创建相关数据文件存放目录 zkData
mkdir -p /opt/module/zookeeper-3.5.7/zkData/{logs,data}
3.1.1.3.2.创建一个 myid 的文件【!!!】
在文件中添加与server 对应的编号(注意:上下不要有空行,左右不要有空格)
echo 1 >/opt/module/zookeeper-3.5.7/zkData/myid
cat /opt/module/zookeeper-3.5.7/zkData/myid
3.1.1.3.3.拷贝配置好的 zookeeper 到其他机器上
xsync 集群同步工具,需要编辑集群分发脚本
xsync.sh zookeeper-3.5.7
并分别在host129、host130 上修改myid 文件中内容为 2、3
3.1.1.4.配置zoo.cfg文件
3.1.1.4.1.拷贝配置文件zoo_sample.cfg 为zoo.cfg
cd /opt/module/zookeeper-3.5.7/conf
拷贝配置文件 zoo_sample.cfg 为zoo.cfg
cp zoo_sample.cfg zoo.cfg
3.1.1.4.2.修改zookeeper配置文件zoo.cfg【!!!】
vi /opt/module/zookeeper-3.5.7/conf/zoo.cfg
修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
增加如下配置
#######################cluster##########################
server.1=192.168.147.128:2888:3888
server.2=192.168.147.129:2888:3888
server.3=192.168.147.130:2888:3888
3.1.1.4.3.配置参数解读【!!!】
tickTime这个时间是作为zookeeper服务器之间或客户端与服务器之间维持心跳的时间间隔为2ms,也就是说每隔tickTime时间就会发送一个心跳。
tickTime=2000
initLimit这个配置项是用来配置zookeeper接受客户端
(这里所说的客户端不是用户连接zookeeper服务器的客户端,而是zookeeper服务器集群中连接到leader的follower 服务器)
初始化连接时最长能忍受多少个心跳时间间隔数。当初始化连接时间超过该值,则表示连接失败。
当已经超过10个心跳的时间(也就是tickTime)长度后 zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。
对于从节点最初连接到主节点时的超时时间,单位为tick值的倍数。总的时间长度就是 10*2000。即20ms
initLimit=10
syncLimit这个配置项标识leader与follower之间发送消息,请求和应答时间长度,最长不能超过多少个tickTime的时间长度
如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
对于主节点与从节点进行同步操作时的超时时间,单位为tick值的倍数。总的时间长度就是5*2000。即10ms
syncLimit=5
dataDir就是zookeeper保存数据库数据快照的位置,默认情况下zookeeper将写数据的日志文件也保存在这个目录里
注意:不能使用 /tmp 路径,会被定期清除。使用专用的存储设备能够大大提高系统的性能
dataDir=/tmp/zookeeper
dataLogDir=/opt/module/zookeeper-3.5.7/zkData/logs
数据文件存放目录
dataDir=/opt/module/zookeeper-3.5.7/zkData
clientPort这个端口就是客户端连接Zookeeper服务器的端口,Zookeeper会监听这个端口接受客户端的访问请求
clientPort=2181
客户端最大链接数
maxClientCnxns=60
zookeeper在运行过程中会生成快照数据,默认不会自动清理,会持续占用硬盘空间
保存3个快照,即3个日志文件
autopurge.snapRetainCount=3
间隔1个小时执行一次清理
autopurge.purgeInterval=1
server.A=B:C:D
其中A是一个数字,表示这个是第几号服务器
集群模式下配置一个文件myid,这个文件在dataDir 目录下,这个文件里面有一个数据就是 A 的值
Zookeeper 启动时读取此文件,拿到里面的数据与zoo.cfg 里面的配置信息比较从而判断到底是哪个server。
echo 1 >/opt/module/zookeeper-3.5.7/zkData/myid
B是这个服务器的IP地址
C第一个端口用来集群成员的信息交换,表示这个服务器Follower与集群中的Leader服务器交换信息的端口
D标识假如集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口
服务器=运行主机:心跳端口:选举端口
zk集群
3888后面位置不能有空格,否则Address unresolved: 192.168.147.128:3888
#######################cluster##########################
server.1=192.168.147.128:2888:3888
server.2=192.168.147.129:2888:3888
server.3=192.168.147.130:2888:3888
3.1.1.4.4.同步zoo.cfg 配置文件
cd /opt/module/zookeeper-3.5.7/conf
xsync.sh zoo.cfg
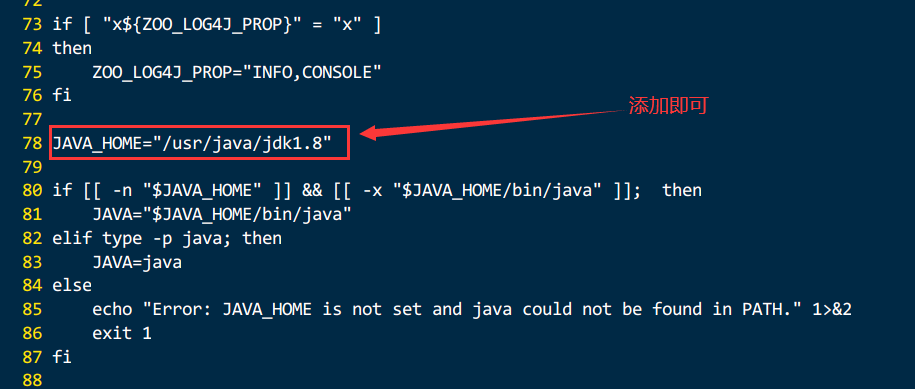
3.1.1.4.5.修改zkEnv.sh文件并同步,配置java环境变量
不修改容易报错:JAVA_HOME is not set and java could not be found in PATH.
vi /opt/module/zookeeper-3.5.7/bin/zkEnv.sh
#添加
JAVA_HOME=“/usr/java/jdk1.8”
xsync.sh zkEnv.sh
3.1.1.5.集群操作
3.1.1.5.1.分别启动Zookeeper
zkServer.sh start
zkServer.sh status
zkServer.sh stop
zkServer.sh restart
#以打印日志方式启动
zkServer.sh start-foreground
3.1.1.5.2.查看状态

3.1.2.选举机制(面试重点)
3.1.2.1.Zookeeper选举机制——第一次启动
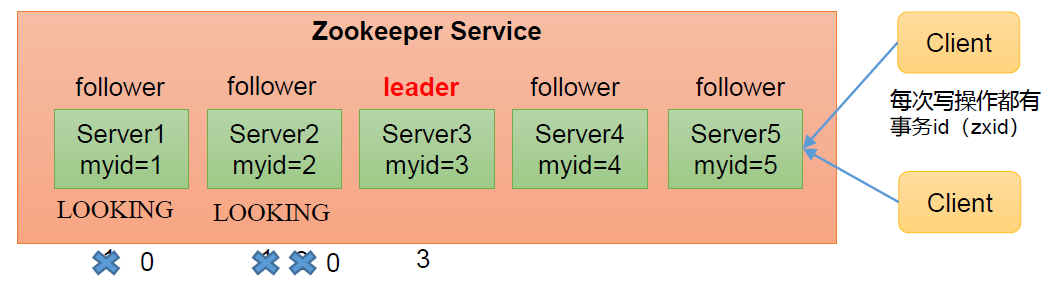
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING;
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
| 名词 | 简介 | 含义 |
|---|---|---|
| SID | 服务器ID | 用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致 |
| ZXID | 事务ID | ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。 |
| Epoch | 每个Leader任期的代号 | 没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加 |
3.1.2.2.Zookeeper选举机制——非第一次启动
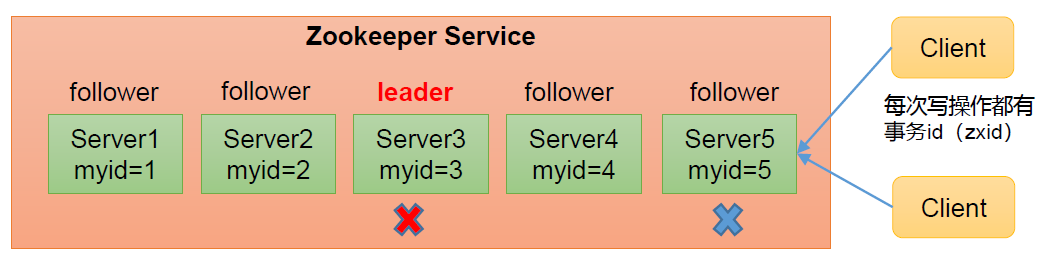
(1)当zookeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
- 服务器初始化启动
- 服务器运行期间无法和leader保持连接
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
- 集群中本来就已经存在一个Leader
对于这种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。 集群中确实不存在Leader(重点)
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。最后选了服务器2。

3.1.3.ZK 集群启动停止脚本
3.1.3.1.在host128 创建脚本
vim /usr/bin/zk.sh
3.1.3.2.脚本内容
#!/bin/bash
定义一个数组
arr=(host128 host129 host130)
case $1 in
“start”){
for i in ${arr[@]}
do
echo ---------- zookeeper $i 启动 ------------
ssh $i “bash /opt/module/zookeeper-3.5.7/bin/zkServer.sh start”
done
};;
“stop”){
for i in ${arr[@]}
do
echo ---------- zookeeper $i 停止 ------------
ssh $i “bash /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop”
done
};;
“status”){
for i in ${arr[@]}
do
echo ---------- zookeeper $i 状态 ------------
ssh $i “bash /opt/module/zookeeper-3.5.7/bin/zkServer.sh status”
done
};;
esac
3.1.3.3.增加脚本执行权限
u代表所有者user;x代表执行权限;+ 表示增加权限
chmod u+x /usr/bin/zk.sh
3.1.3.4.Zookeeper 集群启动
zk.sh start
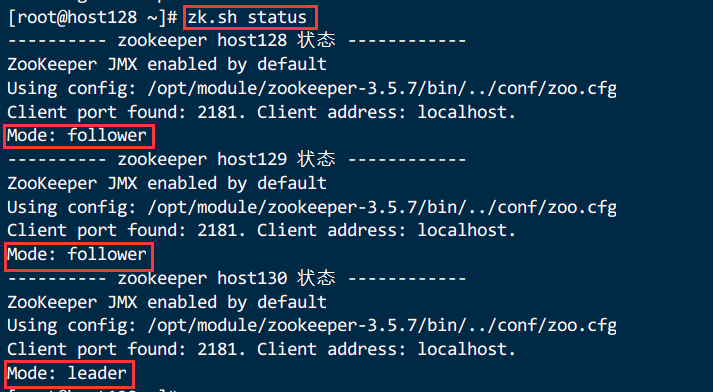
3.1.3.5.Zookeeper 集群状态
zk.sh status
3.1.3.6.Zookeeper 集群停止
zk.sh stop
3.1.4.显示集群的所有java进程状态jpsall 脚本
3.1.4.1.在host128 创建脚本
vim /usr/bin/jpsall
3.1.4.2.脚本内容
#!/bin/bash
该脚本是用来显示集群的所有java进程状态
定义一个数组
list=“host128 host129 host130”
JAVA_HOME=“/usr/java/jdk1.8”
echo “显示集群的所有java进程状态”
for node in $list
do
echo =============== $node ===============
ssh $node $JAVA_HOME’/bin/jps’
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

==========
ssh $node $JAVA_HOME’/bin/jps’
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
[外链图片转存中…(img-xndwSbQX-1712540275381)]
[外链图片转存中…(img-H9rxY8zi-1712540275382)]
[外链图片转存中…(img-rmwIb02b-1712540275382)]
[外链图片转存中…(img-uu7AXk1d-1712540275382)]
[外链图片转存中…(img-7NUPUwWK-1712540275383)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)
[外链图片转存中…(img-B31tHMTt-1712540275383)]















 2918
2918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









