







-
硬件故障:故障的检测和自动快速恢复
-
数据访问:适合批量处理的一次写入,到处读取,而不是用户交互式的随机读写
-
大数据集:典型的HDFS文件大小是GB到TB的级别。所以,HDFS被设计成支持大文件。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件。不适用大量小文件的存储。
=====================================================================
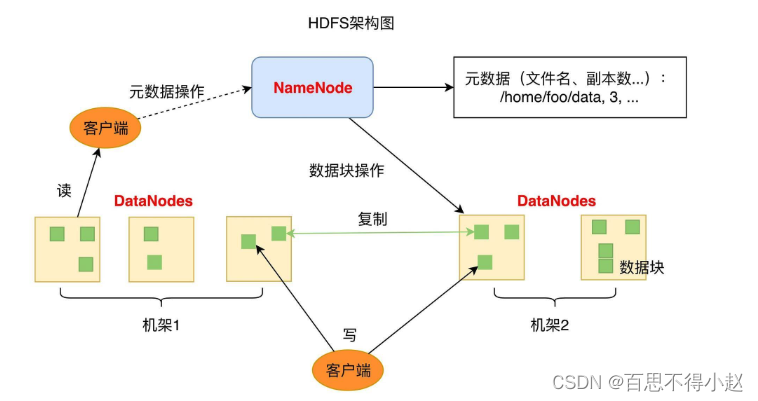
架构 1.0
-
DATANODE:负责文件数据的存储和读写操作,HDFS 将文件数据分割成若干数据块(Block),每个 DataNode存储一部分数据块,这样文件就分布存储在整个 HDFS 服务器集群中。
-
NameNode:负责整个分布式
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1524
1524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









