







 打开C:\Windows\System32\drivers\etc下的hosts文件,添加以下内容(注:如果没有notepad++这类软件,可以通过记事本保存在其他位置,然后拖动到该文件夹下)同样通过mobaxterm的上的SFTP功能(或其他工具)上传到/export/software目录下,然后解压到/export/servers目录下。传完之后要在hadoop02和hadoop03上分别执行 source /etc/profile 命令,来刷新配置文件。在hadoop01上执行。
打开C:\Windows\System32\drivers\etc下的hosts文件,添加以下内容(注:如果没有notepad++这类软件,可以通过记事本保存在其他位置,然后拖动到该文件夹下)同样通过mobaxterm的上的SFTP功能(或其他工具)上传到/export/software目录下,然后解压到/export/servers目录下。传完之后要在hadoop02和hadoop03上分别执行 source /etc/profile 命令,来刷新配置文件。在hadoop01上执行。
3. 配置ip映射
vi /etc/hosts
在文件末尾添加以下3行
192.168.121.134 hadoop01
192.168.121.135 hadoop02
192.168.121.136 hadoop03
 同时修改hadoop02和hadoop03
同时修改hadoop02和hadoop03
4. 修改静态ip
在hadoop01上(如果文件中的参数都没有引号“”,则需要去掉)
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=“static”
ONBOOT=“yes”
新增以下ip设置
IPADDR=“192.168.121.134”
NETMASK=“255.255.255.0”
GATEWAY=“192.168.121.2”
DNS1=“114.114.114.114”

然后在hadoop02和hadoop03上分别设置成121.135和121.136
5. 重启虚拟机
reboot
完成重启后测试下网络是否OK,命令ping www.baidu.com
第四步:ssh服务配置
- 确认ssh服务已开启(默认已开启)
ps -e | grep sshd

- 三台机器生成公钥和私钥
ssh-keygen -t rsa
执行该命令,按3下回车

- 拷贝公钥到另外两台机器
在hadoop01,hadoop02和hadoop03上分别执行以下三行
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
 都执行完毕后,三台机器就可以使用ssh连接而无需输入密码了
都执行完毕后,三台机器就可以使用ssh连接而无需输入密码了
测试一下:
在hadoop02上输入ssh hadoop03,能够免密登录
然后exit退出回来hadoop02
========================== 快照 ==================================


第五步:安装JDK
1. 下载JDK
在jave网站上下载
Java Archive Downloads - Java SE 8
jdk-8u161-linux-x64.tar.gz(网站上下载需要注册,可以从群共享里获取)
2. 安装JDK
上传JDK到linux(SecureCRT工具里使用SecureFXPortable,MobaxTerm里使用自带的tftp功能,注意上传位置,是 /export/software/)
使用MobaxTerm里使用自带的tftp功能
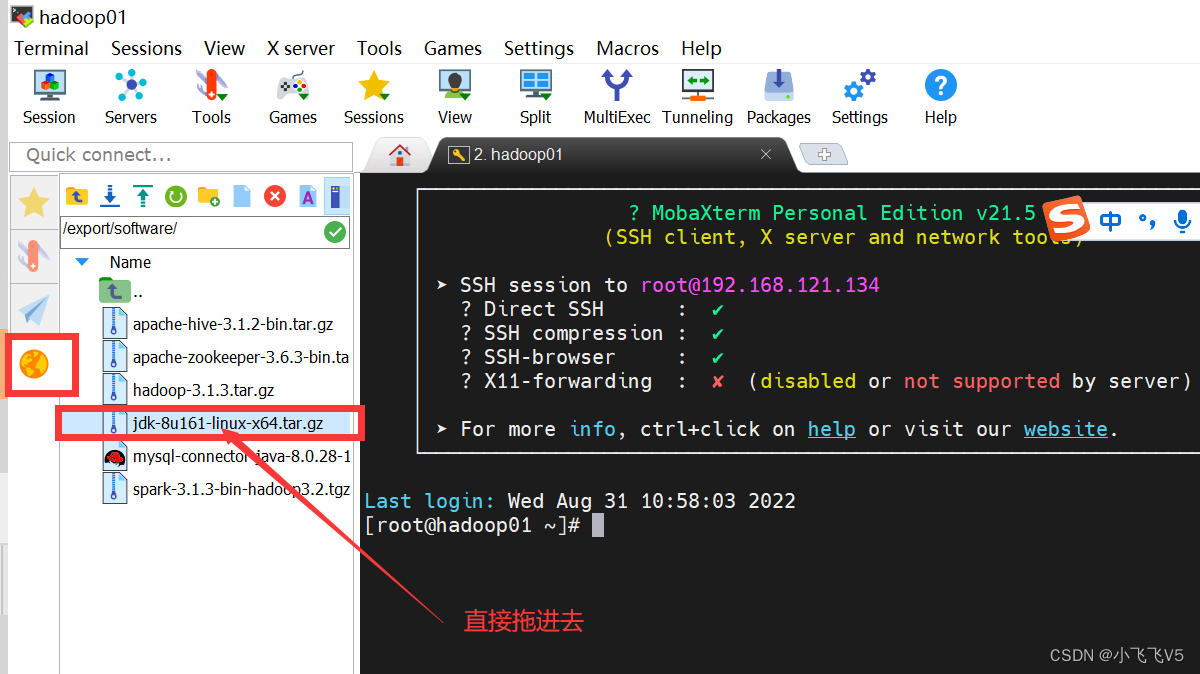 执行解压缩操作:解压到 /export/servers
执行解压缩操作:解压到 /export/servers
cd /export/software/
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
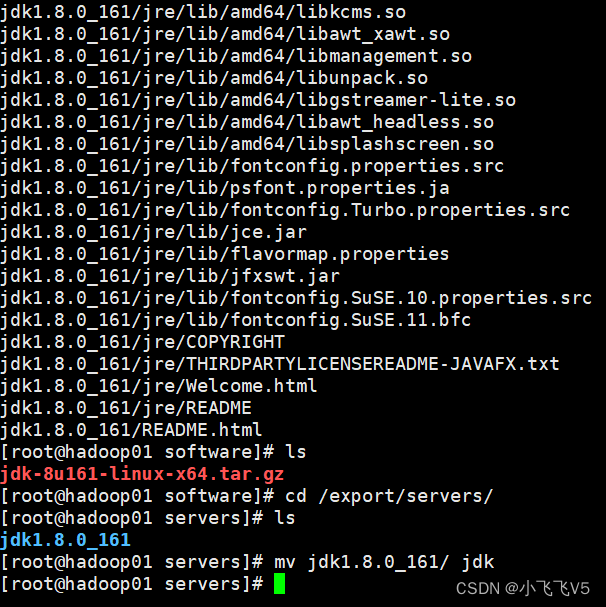
cd /export/servers/
重命名为jdk
mv jdk1.8.0_161/ jdk
3. 配置JDK环境变量
vim /etc/profile
添加如下内容
export JAVA_HOME=/export/servers/jdk
export PATH
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3836
3836











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









