








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
TensorFlow https://github.com/tegg89/SRCNN-Tensorflow
Pytorch https://github.com/fuyongXu/SRCNN_Pytorch_1.0
Keras https://github.com/jiantenggei/SRCNN-Keras

- 创新点:基于深度学习的图像超分辨率重建开山之作。对于一张低分辨率图像,首先采用双三次插值 (bicubic) 的方法将其变换到真实高分辨率图像的大小尺寸。将插值后的图像作为卷积神经网络的输入,最后得到重建的高分辨率图像。
- 主观效果:相比传统方法,SRCNN 重建后的图像质量更高。
- 不足:(1) 依赖于图像区域信息;(2) 训练收敛速度太慢;(3) 网络只适用于单一尺度输入。
- 核心代码:
import torch.nn as nn
class SRCNN(nn.Module):
def \_\_init\_\_(self, inputChannel, outputChannel):
super(SRCNN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(inputChannel, 64, kernel_size=9, padding=9 // 2),
nn.ReLU(inplace=True),
nn.Conv2d(64, 32, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(32, outputChannel, kernel_size=5, padding=5 // 2),
)
def forward(self, x):
out = self.conv(x)
return out
ESPCN
论文:https://arxiv.org/abs/1609.05158
代码:
MatLab https://github.com/wangxuewen99/Super-Resolution/tree/master/ESPCN
TensorFlow https://github.com/drakelevy/ESPCN-TensorFlow
Pytorch https://github.com/leftthomas/ESPCN

- 创新点:在末端直接使用亚像素卷积的方式来进行上采样。
- 好处:(1) 只在模型末端进行上采样,可以使得在低分辨率空间保留更多的纹理区域,在视频超分中也可以做到实时。(2) 模块末端直接使用亚像素卷积的方式来进行上采样,相比于显示的将低分插值到高分,这种上采样方式可以获得更好的重建效果。
- 不足:只考虑上采样的问题,对于如何学习更加丰富的特征信息和利用没有太多研究。
- 其他:亚像素卷积实际上并不涉及到卷积运算,是一种高效、快速、无参 的像素重排列的上采样方式。由于处理速度很快,其直接用在视频超分中也可以做到实时。因此这种上采样的方式很多时候都成为上采样的首选,经常用在低级计算机视觉领域。
- 核心代码:
import math
import torch
from torch import nn
class ESPCN(nn.Module):
def \_\_init\_\_(self, scale_factor, num_channels=1):
super(ESPCN, self).__init__()
self.first_part = nn.Sequential(
nn.Conv2d(num_channels, 64, kernel_size=5, padding=5//2),
nn.Tanh(),
nn.Conv2d(64, 32, kernel_size=3, padding=3//2),
nn.Tanh(),
)
self.last_part = nn.Sequential(
nn.Conv2d(32, num_channels \* (scale_factor \*\* 2), kernel_size=3, padding=3 // 2),
nn.PixelShuffle(scale_factor)
)
self._initialize_weights()
def \_initialize\_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m.in_channels == 32:
nn.init.normal_(m.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(m.bias.data)
else:
nn.init.normal_(m.weight.data, mean=0.0, std=math.sqrt(2/(m.out_channels\*m.weight.data[0][0].numel())))
nn.init.zeros_(m.bias.data)
def forward(self, x):
x = self.first_part(x)
x = self.last_part(x)
return x
VDSR
论文:https://arxiv.org/abs/1511.04587
代码:
MatLab (1) https://cv.snu.ac.kr/research/VDSR/ (2) https://github.com/huangzehao/caffe-vdsr
TensorFlow https://github.com/Jongchan/tensorflow-vdsr
Pytorch https://github.com/twtygqyy/pytorch-vdsr

- 创新点:(1) 使用足够深的神经网络; (2) 引入残差学习; (3) 更高的学习率; (4) 提出多尺度超分模型。
- 好处:(1) VDSR 加深网络深度使得网络感受野更大, 更好地利用了更大区域的上下文信息。(2) 残差学习加速网络收敛,同时进行高低级别特征信息的融合;(3) 更高的学习率可以加速网络的收敛;(4) VDSR 通过让参数在所有预定义的尺度因子中共享,经济地解决了不同放大尺度的问题。
- 不足:过大的学习率可能造成梯度的爆炸,所以提出梯度裁减的方法来避免。
- 核心代码:
import torch
import torch.nn as nn
from math import sqrt
class Conv\_ReLU\_Block(nn.Module):
def \_\_init\_\_(self):
super(Conv_ReLU_Block, self).__init__()
self.conv = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
return self.relu(self.conv(x))
class VDSR(nn.Module):
def \_\_init\_\_(self):
super(VDSR, self).__init__()
self.residual_layer = self.make_layer(Conv_ReLU_Block, 18)
self.input = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.output = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] \* m.kernel_size[1] \* m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
def make\_layer(self, block, num_of_layer):
layers = []
for _ in range(num_of_layer):
layers.append(block())
return nn.Sequential(\*layers)
def forward(self, x):
residual = x
out = self.relu(self.input(x))
out = self.residual_layer(out)
out = self.output(out)
out = torch.add(out, residual)
return out
DRCN
论文:https://arxiv.org/pdf/1511.04491.pdf
代码:
MatLab https://cv.snu.ac.kr/research/DRCN/
TensorFlow (1) https://github.com/nullhty/DRCN_Tensorflow (2) https://github.com/jiny2001/deeply-recursive-cnn-tf
Pytorch https://github.com/fungtion/DRCN
Keras https://github.com/ghif/drcn


- 创新点:(1) 提出了深度递归卷积网络,用相同的循环层来替代不同的卷积层;(2) 提出循环监督和使用跳跃连接。
- 好处:(1) 增大网络的感受野;(2) 避免深度网络的梯度消失 / 爆炸问题。
- 核心代码:
import torch.nn as nn
class DRCN(nn.Module):
def \_\_init\_\_(self, n_class):
super(DRCN, self).__init__()
# convolutional encoder
self.enc_feat = nn.Sequential()
self.enc_feat.add_module('conv1', nn.Conv2d(in_channels=1, out_channels=100, kernel_size=5,
padding=2))
self.enc_feat.add_module('relu1', nn.ReLU(True))
self.enc_feat.add_module('pool1', nn.MaxPool2d(kernel_size=2, stride=2))
self.enc_feat.add_module('conv2', nn.Conv2d(in_channels=100, out_channels=150, kernel_size=5,
padding=2))
self.enc_feat.add_module('relu2', nn.ReLU(True))
self.enc_feat.add_module('pool2', nn.MaxPool2d(kernel_size=2, stride=2))
self.enc_feat.add_module('conv3', nn.Conv2d(in_channels=150, out_channels=200, kernel_size=3,
padding=1))
self.enc_feat.add_module('relu3', nn.ReLU(True))
self.enc_dense = nn.Sequential()
self.enc_dense.add_module('fc4', nn.Linear(in_features=200 \* 8 \* 8, out_features=1024))
self.enc_dense.add_module('relu4', nn.ReLU(True))
self.enc_dense.add_module('drop4', nn.Dropout2d())
self.enc_dense.add_module('fc5', nn.Linear(in_features=1024, out_features=1024))
self.enc_dense.add_module('relu5', nn.ReLU(True))
# label predict layer
self.pred = nn.Sequential()
self.pred.add_module('dropout6', nn.Dropout2d())
self.pred.add_module('predict6', nn.Linear(in_features=1024, out_features=n_class))
# convolutional decoder
self.rec_dense = nn.Sequential()
self.rec_dense.add_module('fc5\_', nn.Linear(in_features=1024, out_features=1024))
self.rec_dense.add_module('relu5\_', nn.ReLU(True))
self.rec_dense.add_module('fc4\_', nn.Linear(in_features=1024, out_features=200 \* 8 \* 8))
self.rec_dense.add_module('relu4\_', nn.ReLU(True))
self.rec_feat = nn.Sequential()
self.rec_feat.add_module('conv3\_', nn.Conv2d(in_channels=200, out_channels=150,
kernel_size=3, padding=1))
self.rec_feat.add_module('relu3\_', nn.ReLU(True))
self.rec_feat.add_module('pool3\_', nn.Upsample(scale_factor=2))
self.rec_feat.add_module('conv2\_', nn.Conv2d(in_channels=150, out_channels=100,
kernel_size=5, padding=2))
self.rec_feat.add_module('relu2\_', nn.ReLU(True))
self.rec_feat.add_module('pool2\_', nn.Upsample(scale_factor=2))
self.rec_feat.add_module('conv1\_', nn.Conv2d(in_channels=100, out_channels=1,
kernel_size=5, padding=2))
def forward(self, input_data):
feat = self.enc_feat(input_data)
feat = feat.view(-1, 200 \* 8 \* 8)
feat_code = self.enc_dense(feat)
pred_label = self.pred(feat_code)
feat_encode = self.rec_dense(feat_code)
feat_encode = feat_encode.view(-1, 200, 8, 8)
img_rec = self.rec_feat(feat_encode)
return pred_label, img_rec
DRRN
论文:https://openaccess.thecvf.com/content_cvpr_2017/html/Tai_Image_Super-Resolution_via_CVPR_2017_paper.html
代码:
MatLab https://github.com/tyshiwo/DRRN_CVPR17
TensorFlow https://github.com/LoSealL/VideoSuperResolution
Pytorch https://github.com/Major357/DRRN-pytorch

- 创新点:(1) 比 VDSR 更深的网络;(2) 递归学习; (3) 残差学习。
- 好处:(1) 越深的网络一般可以得到更好的重建效果;(2) 相当于增加网络深度,权重共享来减少参数量;(3) 避免发生梯度消失 / 爆炸问题。
- 核心代码:
import torch
import torch.nn as nn
from math import sqrt
class DRRN(nn.Module):
def \_\_init\_\_(self):
super(DRRN, self).__init__()
self.input = nn.Conv2d(in_channels=1, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False)
self.conv1 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False)
self.conv2 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1, bias=False)
self.output = nn.Conv2d(in_channels=128, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.ReLU(inplace=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] \* m.kernel_size[1] \* m.out_channels
m.weight.data.normal_(0, sqrt(2. / n))
def forward(self, x):
residual = x
inputs = self.input(self.relu(x))
out = inputs
for _ in range(25):
out = self.conv2(self.relu(self.conv1(self.relu(out))))
out = torch.add(out, inputs)
out = self.output(self.relu(out))
out = torch.add(out, residual)
return out
EDSR
论文:https://arxiv.org/abs/1707.02921
代码:
TensorFlow https://github.com/jmiller656/EDSR-Tensorflow
Pytorch (1) https://github.com/sanghyun-son/EDSR-PyTorch (2) https://github.com/thstkdgus35/EDSR-PyTorch

- 创新点:(1) 移除 BatchNorm 层;(2) 提出带有单一主分支的的多尺度木块,先训练低倍超分模型,再在其基础上训练高倍超分模型。
- 好处:(1) 模型更加轻量,也能更好地表达图像特征;(2) 权值共享,减少高倍超分模型训练时间,同时重建效果更好。
- 移除 BN 层的原因:
BatchNorm 是深度学习中非常重要的技术,不仅可以使训练更深的网络变容易,加速收敛,还有一定正则化的效果,防止网络过拟合,因此 BatchNorm 在 CNN 中被大量使用。但在图像超分辨率和图像生成与恢复方面,BatchNorm 的表现并不好,它反而使得网络训练速度缓慢,不稳定,甚至最后发散。
BatchNorm 会忽略图像像素(或者特征)之间的绝对差异(因为均值归零,方差归一),而只考虑相对差异,所以在不需要绝对差异的任务中(比如分类),有锦上添花的效果。而对于图像超分辨率这种需要利用绝对差异的任务,BatchNorm 并不适用。此外,由于 BatchNorm 消耗与它前面的卷积层相同大小的内存,去掉后在相同的计算资源下,EDSR 可以堆叠更多的网络层或者使每层提取更多的特征,从而获得更好的表现。
参考:https://blog.csdn.net/sinat_36197913/article/details/104845599 - 核心代码:
class EDSR(nn.Module):
def \_\_init\_\_(self, args, conv=common.default_conv):
super(EDSR, self).__init__()
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
scale = args.scale[0]
act = nn.ReLU(True)
self.sub_mean = common.MeanShift(args.rgb_range)
self.add_mean = common.MeanShift(args.rgb_range, sign=1)
# define head module
m_head = [conv(args.n_colors, n_feats, kernel_size)]
# define body module
m_body = [
common.ResBlock(
conv, n_feats, kernel_size, act=act, res_scale=args.res_scale
) for _ in range(n_resblocks)
]
m_body.append(conv(n_feats, n_feats, kernel_size))
# define tail module
m_tail = [
common.Upsampler(conv, scale, n_feats, act=False),
conv(n_feats, args.n_colors, kernel_size)
]
self.head = nn.Sequential(\*m_head)
self.body = nn.Sequential(\*m_body)
self.tail = nn.Sequential(\*m_tail)
def forward(self, x):
x = self.sub_mean(x)
x = self.head(x)
res = self.body(x)
res += x
x = self.tail(res)
x = self.add_mean(x)
return x
SRGAN
论文:http://arxiv.org/abs/1609.04802
代码:
MatLab https://github.com/ShenghaiRong/caffe_srgan
TensorFlow (1) https://github.com/brade31919/SRGAN-tensorflow (2) https://github.com/zsdonghao/SRGAN (3) https://github.com/buriburisuri/SRGAN
Pytorch (1) https://github.com/zzbdr/DL/tree/main/Super-resolution/SRGAN (2) https://github.com/aitorzip/PyTorch-SRGAN
Keras (1) https://github.com/jiantenggei/srgan (2) https://github.com/jiantenggei/Srgan_ (3) https://github.com/titu1994/Super-Resolution-using-Generative-Adversarial-Networks

- 创新点:(1) 使用 GAN 进行超分重建;(2) 根据 VGG 网络提取的特征图间的欧氏距离提出一种新的感知损失替换基于 MSE 内容丢失;(3) 提出一种新的图像质量评价指标 Mean Opinion Score (MOS)。
- 好处:(1) GAN网络可以产生具有高感知质量的图像,从而得到让人肉眼感官更加舒适的高分图像;(2) 更高层的图像特征会产生更多的图像细节,在特征图计算损失使其可以重建出视觉上更好的高分图像;(3) 对于重建图像的评价更加符合人眼视觉效果。
- MSE 损失函数的局限性:虽然直接优化 MSE 可以产生较高的 PSNR / SSIM,但是在放大倍数较大的情况下,MSE 损失引导的学习无法使得重建图像捕获细节信息。
- 为什么不用 PSNR / SSIM 评价图像质量:众所周知,PSNR 值的大小并不能绝对真实地反应图像的质量,SSIM 相比 PSNR 对图像质量的评价更接近人眼的视觉效果。但在本文中,作者认为这两个指标都不够准确,因此提出平均意见得分 MOS。
- 核心代码:
import torch.nn as nn
class Block(nn.Module):
def \_\_init\_\_(self, input_channel=64, output_channel=64, kernel_size=3, stride=1, padding=1):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, bias=False, padding=1),
nn.BatchNorm2d(output_channel),
nn.PReLU(),
nn.Conv2d(output_channel, output_channel, kernel_size, stride, bias=False, padding=1),
nn.BatchNorm2d(output_channel)
)
def forward(self, x0):
x1 = self.layer(x0)
return x0 + x1
class Generator(nn.Module):
def \_\_init\_\_(self, scale=2):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 9, stride=1, padding=4),
nn.PReLU()
)
self.residual_block = nn.Sequential(
Block(),
Block(),
Block(),
Block(),
Block(),
)
self.conv2 = nn.Sequential(
nn.Conv2d(64, 64, 3, stride=1, padding=1),
nn.BatchNorm2d(64),
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 256, 3, stride=1, padding=1),
nn.PixelShuffle(scale),
nn.PReLU(),
nn.Conv2d(64, 256, 3, stride=1, padding=1),
nn.PixelShuffle(scale),
nn.PReLU(),
)
self.conv4 = nn.Conv2d(64, 3, 9, stride=1, padding=4)
def forward(self, x):
x0 = self.conv1(x)
x = self.residual_block(x0)
x = self.conv2(x)
x = self.conv3(x + x0)
x = self.conv4(x)
return x
class DownSalmpe(nn.Module):
def \_\_init\_\_(self, input_channel, output_channel, stride, kernel_size=3, padding=1):
super().__init__()
self.layer = nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, padding),
nn.BatchNorm2d(output_channel),
nn.LeakyReLU(inplace=True)
)
def forward(self, x):
x = self.layer(x)
return x
class Discriminator(nn.Module):
def \_\_init\_\_(self):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, 3, stride=1, padding=1),
nn.LeakyReLU(inplace=True),
)
self.down = nn.Sequential(
DownSalmpe(64, 64, stride=2, padding=1),
DownSalmpe(64, 128, stride=1, padding=1),
DownSalmpe(128, 128, stride=2, padding=1),
DownSalmpe(128, 256, stride=1, padding=1),
DownSalmpe(256, 256, stride=2, padding=1),
DownSalmpe(256, 512, stride=1, padding=1),
DownSalmpe(512, 512, stride=2, padding=1),
)
self.dense = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(512, 1024, 1),
nn.LeakyReLU(inplace=True),
nn.Conv2d(1024, 1, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.conv1(x)
x = self.down(x)
x = self.dense(x)
return x
ESRGAN
论文:https://arxiv.org/abs/1809.00219
代码:
Pytorch https://github.com/xinntao/ESRGAN


- 创新点:(1) 提出 Residual-in-Residual Dense Block (RRDB) 结构,并去掉去掉 BatchNorm 层; (2) 借鉴 Relativistic GAN 的想法,让判别器预测图像的真实性而不是图像“是否是 fake 图像”;(3) 使用激活前的特征计算感知损失。
- 好处:(1) 密集连接可以更好地融合特征和加速训练,更加提升恢复得到的纹理(因为深度模型具有强大的表示能力来捕获语义信息),而且可以去除噪声,同时去掉 BatchNorm 可以获得更好的效果;(2) 让重建的图像更加接近真实图像;(3) 激活前的特征会提供更尖锐的边缘和更符合视觉的结果。
- 核心代码:
import functools
import torch
import torch.nn as nn
import torch.nn.functional as F
def make\_layer(block, n_layers):
layers = []
for _ in range(n_layers):
layers.append(block())
return nn.Sequential(\*layers)
class ResidualDenseBlock\_5C(nn.Module):
def \_\_init\_\_(self, nf=64, gc=32, bias=True):
super(ResidualDenseBlock_5C, self).__init__()
# gc: growth channel, i.e. intermediate channels
self.conv1 = nn.Conv2d(nf, gc, 3, 1, 1, bias=bias)
self.conv2 = nn.Conv2d(nf + gc, gc, 3, 1, 1, bias=bias)
self.conv3 = nn.Conv2d(nf + 2 \* gc, gc, 3, 1, 1, bias=bias)
self.conv4 = nn.Conv2d(nf + 3 \* gc, gc, 3, 1, 1, bias=bias)
self.conv5 = nn.Conv2d(nf + 4 \* gc, nf, 3, 1, 1, bias=bias)
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
# initialization
# mutil.initialize\_weights([self.conv1, self.conv2, self.conv3, self.conv4, self.conv5], 0.1)
def forward(self, x):
x1 = self.lrelu(self.conv1(x))
x2 = self.lrelu(self.conv2(torch.cat((x, x1), 1)))
x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), 1)))
x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), 1)))
x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
return x5 \* 0.2 + x
class RRDB(nn.Module):
'''Residual in Residual Dense Block'''
def \_\_init\_\_(self, nf, gc=32):
super(RRDB, self).__init__()
self.RDB1 = ResidualDenseBlock_5C(nf, gc)
self.RDB2 = ResidualDenseBlock_5C(nf, gc)
self.RDB3 = ResidualDenseBlock_5C(nf, gc)
def forward(self, x):
out = self.RDB1(x)
out = self.RDB2(out)
out = self.RDB3(out)
return out \* 0.2 + x
class RRDBNet(nn.Module):
def \_\_init\_\_(self, in_nc, out_nc, nf, nb, gc=32):
super(RRDBNet, self).__init__()
RRDB_block_f = functools.partial(RRDB, nf=nf, gc=gc)
self.conv_first = nn.Conv2d(in_nc, nf, 3, 1, 1, bias=True)
self.RRDB_trunk = make_layer(RRDB_block_f, nb)
self.trunk_conv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
#### upsampling
self.upconv1 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.upconv2 = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.HRconv = nn.Conv2d(nf, nf, 3, 1, 1, bias=True)
self.conv_last = nn.Conv2d(nf, out_nc, 3, 1, 1, bias=True)
self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
def forward(self, x):
fea = self.conv_first(x)
trunk = self.trunk_conv(self.RRDB_trunk(fea))
fea = fea + trunk
fea = self.lrelu(self.upconv1(F.interpolate(fea, scale_factor=2, mode='nearest')))
fea = self.lrelu(self.upconv2(F.interpolate(fea, scale_factor=2, mode='nearest')))
out = self.conv_last(self.lrelu(self.HRconv(fea)))
return out
RDN
论文:https://arxiv.org/abs/1802.08797
代码:
TensorFlow https://github.com/hengchuan/RDN-TensorFlow
Pytorch https://github.com/lizhengwei1992/ResidualDenseNetwork-Pytorch
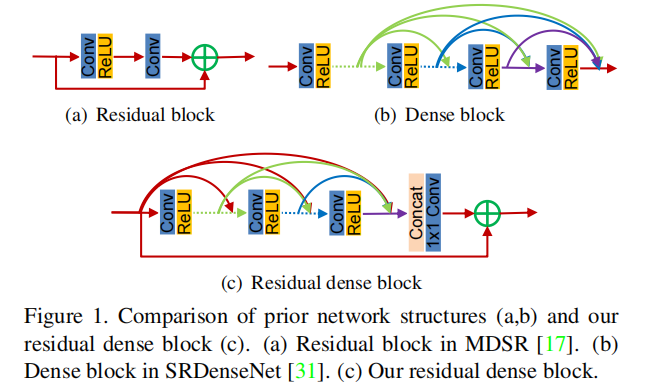
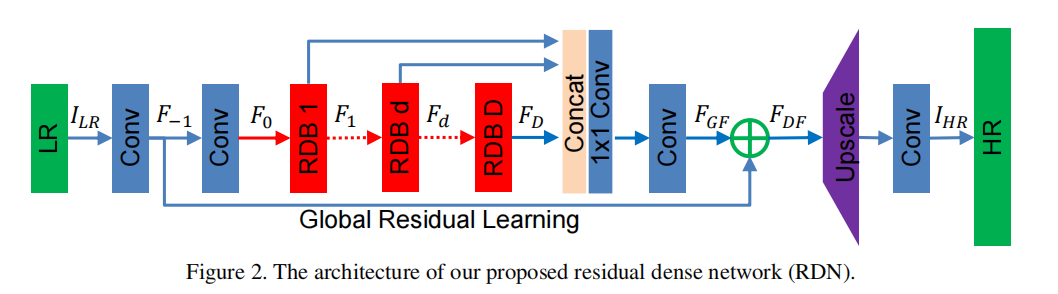
- 创新点:提出Residual Dense Block (RDB) 结构;
- 好处:残差学习和密集连接有效缓解网络深度增加引发的梯度消失的现象,其中密集连接加强特征传播, 鼓励特征复用。
- 核心代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class sub\_pixel(nn.Module):
def \_\_init\_\_(self, scale, act=False):
super(sub_pixel, self).__init__()
modules = []
modules.append(nn.PixelShuffle(scale))
self.body = nn.Sequential(\*modules)
def forward(self, x):
x = self.body(x)
return x
class make\_dense(nn.Module):
def \_\_init\_\_(self, nChannels, growthRate, kernel_size=3):
super(make_dense, self).__init__()
self.conv = nn.Conv2d(nChannels, growthRate, kernel_size=kernel_size, padding=(kernel_size-1)//2, bias=False)
def forward(self, x):
out = F.relu(self.conv(x))
out = torch.cat((x, out), 1)
return out
# Residual dense block (RDB) architecture
class RDB(nn.Module):
def \_\_init\_\_(self, nChannels, nDenselayer, growthRate):
super(RDB, self).__init__()
nChannels_ = nChannels
modules = []
for i in range(nDenselayer):
modules.append(make_dense(nChannels_, growthRate))
nChannels_ += growthRate
self.dense_layers = nn.Sequential(\*modules)
self.conv_1x1 = nn.Conv2d(nChannels_, nChannels, kernel_size=1, padding=0, bias=False)
def forward(self, x):
out = self.dense_layers(x)
out = self.conv_1x1(out)
out = out + x
return out
# Residual Dense Network
class RDN(nn.Module):
def \_\_init\_\_(self, args):
super(RDN, self).__init__()
nChannel = args.nChannel
nDenselayer = args.nDenselayer
nFeat = args.nFeat
scale = args.scale
growthRate = args.growthRate
self.args = args
# F-1
self.conv1 = nn.Conv2d(nChannel, nFeat, kernel_size=3, padding=1, bias=True)
# F0
self.conv2 = nn.Conv2d(nFeat, nFeat, kernel_size=3, padding=1, bias=True)
# RDBs 3
self.RDB1 = RDB(nFeat, nDenselayer, growthRate)
self.RDB2 = RDB(nFeat, nDenselayer, growthRate)
self.RDB3 = RDB(nFeat, nDenselayer, growthRate)
# global feature fusion (GFF)
self.GFF_1x1 = nn.Conv2d(nFeat\*3, nFeat, kernel_size=1, padding=0, bias=True)
self.GFF_3x3 = nn.Conv2d(nFeat, nFeat, kernel_size=3, padding=1, bias=True)
# Upsampler
self.conv_up = nn.Conv2d(nFeat, nFeat\*scale\*scale, kernel_size=3, padding=1, bias=True)
self.upsample = sub_pixel(scale)
# conv
self.conv3 = nn.Conv2d(nFeat, nChannel, kernel_size=3, padding=1, bias=True)
def forward(self, x):
F_ = self.conv1(x)
F_0 = self.conv2(F_)
F_1 = self.RDB1(F_0)
F_2 = self.RDB2(F_1)
F_3 = self.RDB3(F_2)
FF = torch.cat((F_1, F_2, F_3), 1)
FdLF = self.GFF_1x1(FF)
FGF = self.GFF_3x3(FdLF)
FDF = FGF + F_
us = self.conv_up(FDF)
us = self.upsample(us)
output = self.conv3(us)
return output
WDSR
论文:https://arxiv.org/abs/1808.08718
代码:
TensorFlow https://github.com/ychfan/tf_estimator_barebone
Pytorch https://github.com/JiahuiYu/wdsr_ntire2018
Keras https://github.com/krasserm/super-resolution
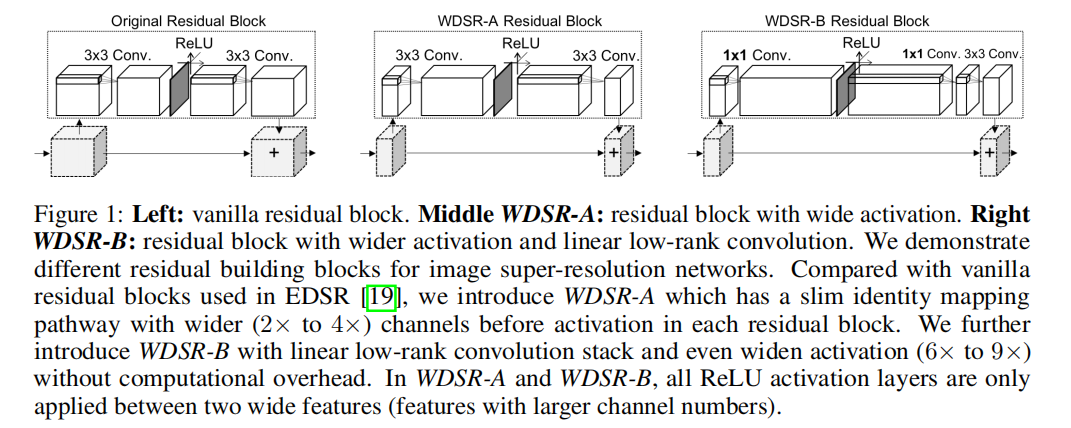

- 创新点:(1) 增多激活函数前的特征图通道数,即宽泛特征图;(2) Weight Normalization;(3) 两个分支进行相同的上采样操作,直接相加得到高分图像。
- 好处:(1) 激活函数会阻止信息流的传递,通过增加特征图通道数可以降低激活函数对信息流的影响;(2) 网络的训练速度和性能都有提升,同时也使得训练可以使用较大的学习率;(3) 大卷积核拆分成两个小卷积核,可以节省参数。
- 核心代码:
import torch
import torch.nn as nn
class Block(nn.Module):
def \_\_init\_\_(
self, n_feats, kernel_size, wn, act=nn.ReLU(True), res_scale=1):
super(Block, self).__init__()
self.res_scale = res_scale
body = []
expand = 6
linear = 0.8
body.append(
wn(nn.Conv2d(n_feats, n_feats\*expand, 1, padding=1//2)))
body.append(act)
body.append(
wn(nn.Conv2d(n_feats\*expand, int(n_feats\*linear), 1, padding=1//2)))
body.append(
wn(nn.Conv2d(int(n_feats\*linear), n_feats, kernel_size, padding=kernel_size//2)))
self.body = nn.Sequential(\*body)
def forward(self, x):
res = self.body(x) \* self.res_scale
res += x
return res
class MODEL(nn.Module):
def \_\_init\_\_(self, args):
super(MODEL, self).__init__()
# hyper-params
self.args = args
scale = args.scale[0]
n_resblocks = args.n_resblocks
n_feats = args.n_feats
kernel_size = 3
act = nn.ReLU(True)
# wn = lambda x: x
wn = lambda x: torch.nn.utils.weight_norm(x)
self.rgb_mean = torch.autograd.Variable(torch.FloatTensor(
[args.r_mean, args.g_mean, args.b_mean])).view([1, 3, 1, 1])
# define head module
head = []
head.append(
wn(nn.Conv2d(args.n_colors, n_feats, 3, padding=3//2)))
# define body module
body = []
for i in range(n_resblocks):
body.append(
Block(n_feats, kernel_size, act=act, res_scale=args.res_scale, wn=wn))
# define tail module
tail = []
out_feats = scale\*scale\*args.n_colors
tail.append(
wn(nn.Conv2d(n_feats, out_feats, 3, padding=3//2)))
tail.append(nn.PixelShuffle(scale))
skip = []
skip.append(
wn(nn.Conv2d(args.n_colors, out_feats, 5, padding=5//2))
)
skip.append(nn.PixelShuffle(scale))
# make object members
self.head = nn.Sequential(\*head)
self.body = nn.Sequential(\*body)
self.tail = nn.Sequential(\*tail)
self.skip = nn.Sequential(\*skip)
def forward(self, x):
x = (x - self.rgb_mean.cuda()\*255)/127.5
s = self.skip(x)
x = self.head(x)
x = self.body(x)
x = self.tail(x)
x += s
x = x\*127.5 + self.rgb_mean.cuda()\*255
return x
LapSRN
论文:https://arxiv.org/abs/1704.03915
代码:
MatLab https://github.com/phoenix104104/LapSRN
TensorFlow https://github.com/zjuela/LapSRN-tensorflow
Pytorch https://github.com/twtygqyy/pytorch-LapSRN

- 创新点:(1) 提出一种级联的金字塔结构;(2) 提出一种新的损失函数。
- 好处:(1) 降低计算复杂度,同时低级特征与高级特征来增加网络的非线性,从而更好地学习和映射细节特征。此外,金字塔结构也使得该算法可以一次就完成多个尺度;(2) MSE 损失会导致重建的高分图像细节模糊和平滑,新的损失函数可以改善这一点。
- 拉普拉斯图像金字塔:https://www.jianshu.com/p/e3570a9216a6
- 核心代码:
import torch
import torch.nn as nn
import numpy as np
import math
def get\_upsample\_filter(size):
"""Make a 2D bilinear kernel suitable for upsampling"""
factor = (size + 1) // 2
if size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:size, :size]
filter = (1 - abs(og[0] - center) / factor) \* \
(1 - abs(og[1] - center) / factor)
return torch.from_numpy(filter).float()
class \_Conv\_Block(nn.Module):
def \_\_init\_\_(self):
super(_Conv_Block, self).__init__()
self.cov_block = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
nn.ConvTranspose2d(in_channels=64, out_channels=64, kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
)
def forward(self, x):
output = self.cov_block(x)
return output
class Net(nn.Module):
def \_\_init\_\_(self):
super(Net, self).__init__()
self.conv_input = nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1, bias=False)
self.relu = nn.LeakyReLU(0.2, inplace=True)
self.convt_I1 = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=4, stride=2, padding=1, bias=False)
self.convt_R1 = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.convt_F1 = self.make_layer(_Conv_Block)
self.convt_I2 = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=4, stride=2, padding=1, bias=False)
self.convt_R2 = nn.Conv2d(in_channels=64, out_channels=1, kernel_size=3, stride=1, padding=1, bias=False)
self.convt_F2 = self.make_layer(_Conv_Block)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] \* m.kernel_size[1] \* m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
if isinstance(m, nn.ConvTranspose2d):
c1, c2, h, w = m.weight.data.size()
weight = get_upsample_filter(h)
m.weight.data = weight.view(1, 1, h, w).repeat(c1, c2, 1, 1)
if m.bias is not None:
m.bias.data.zero_()
def make\_layer(self, block):
layers = []
layers.append(block())
return nn.Sequential(\*layers)
def forward(self, x):
out = self.relu(self.conv_input(x))
convt_F1 = self.convt_F1(out)
convt_I1 = self.convt_I1(x)
convt_R1 = self.convt_R1(convt_F1)
HR_2x = convt_I1 + convt_R1
convt_F2 = self.convt_F2(convt_F1)
convt_I2 = self.convt_I2(HR_2x)
convt_R2 = self.convt_R2(convt_F2)
HR_4x = convt_I2 + convt_R2
return HR_2x, HR_4x
RCAN
论文:https://arxiv.org/abs/1807.02758
代码:
TensorFlow (1) https://github.com/dongheehand/RCAN-tf (2) https://github.com/keerthan2/Residual-Channel-Attention-Network
Pytorch https://github.com/yulunzhang/RCAN
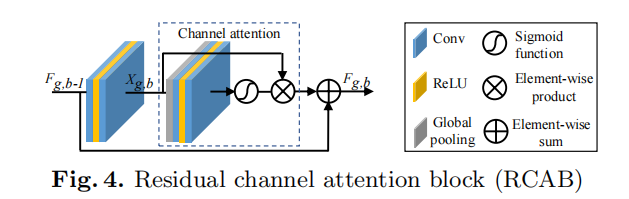
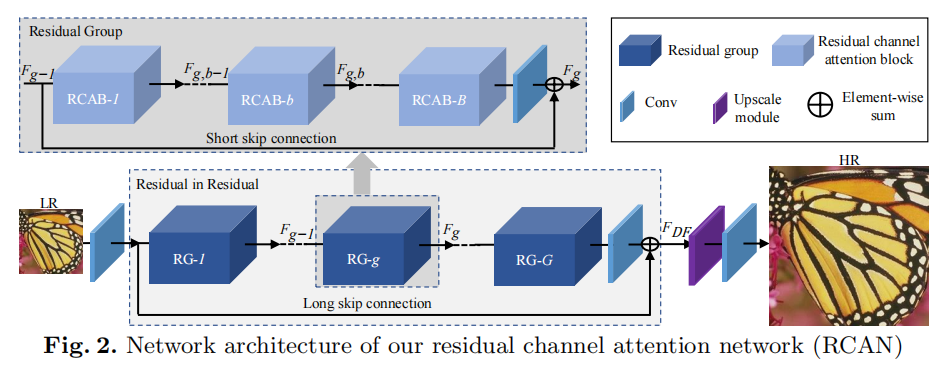
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
F1)
convt_I2 = self.convt_I2(HR_2x)
convt_R2 = self.convt_R2(convt_F2)
HR_4x = convt_I2 + convt_R2
return HR_2x, HR_4x
#### RCAN
论文:<https://arxiv.org/abs/1807.02758>
代码:
TensorFlow (1) <https://github.com/dongheehand/RCAN-tf> (2) <https://github.com/keerthan2/Residual-Channel-Attention-Network>
Pytorch <https://github.com/yulunzhang/RCAN>


[外链图片转存中...(img-JTAPU55F-1715408782793)]
[外链图片转存中...(img-y2ZAMJT0-1715408782794)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 3970
3970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









