







爬取并分类好的数据大致如下:

5、界面设计
使用QtDesigner进行界面设计
设计界面如下:
1、采集数据界面
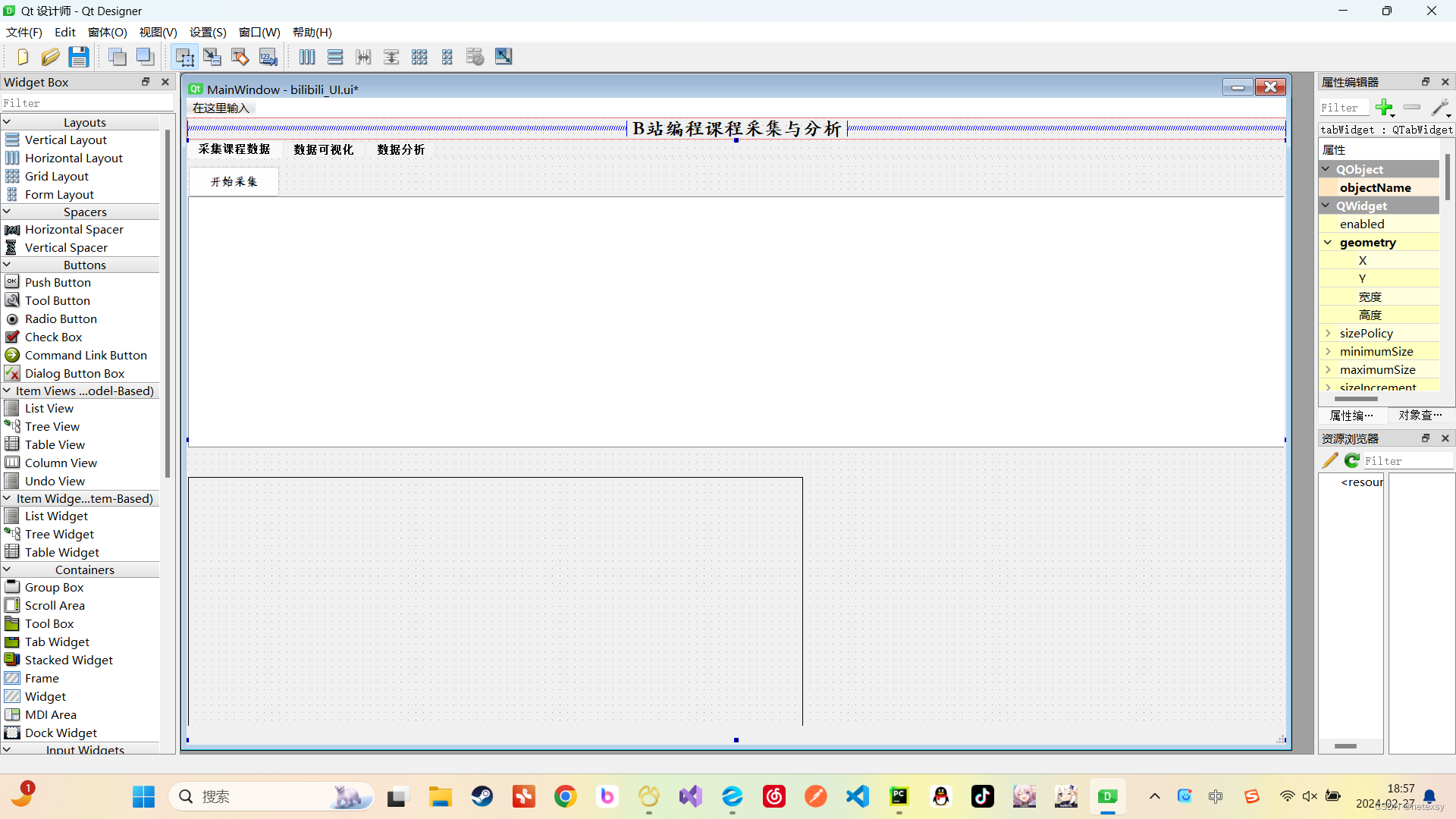
2、数据可视化界面
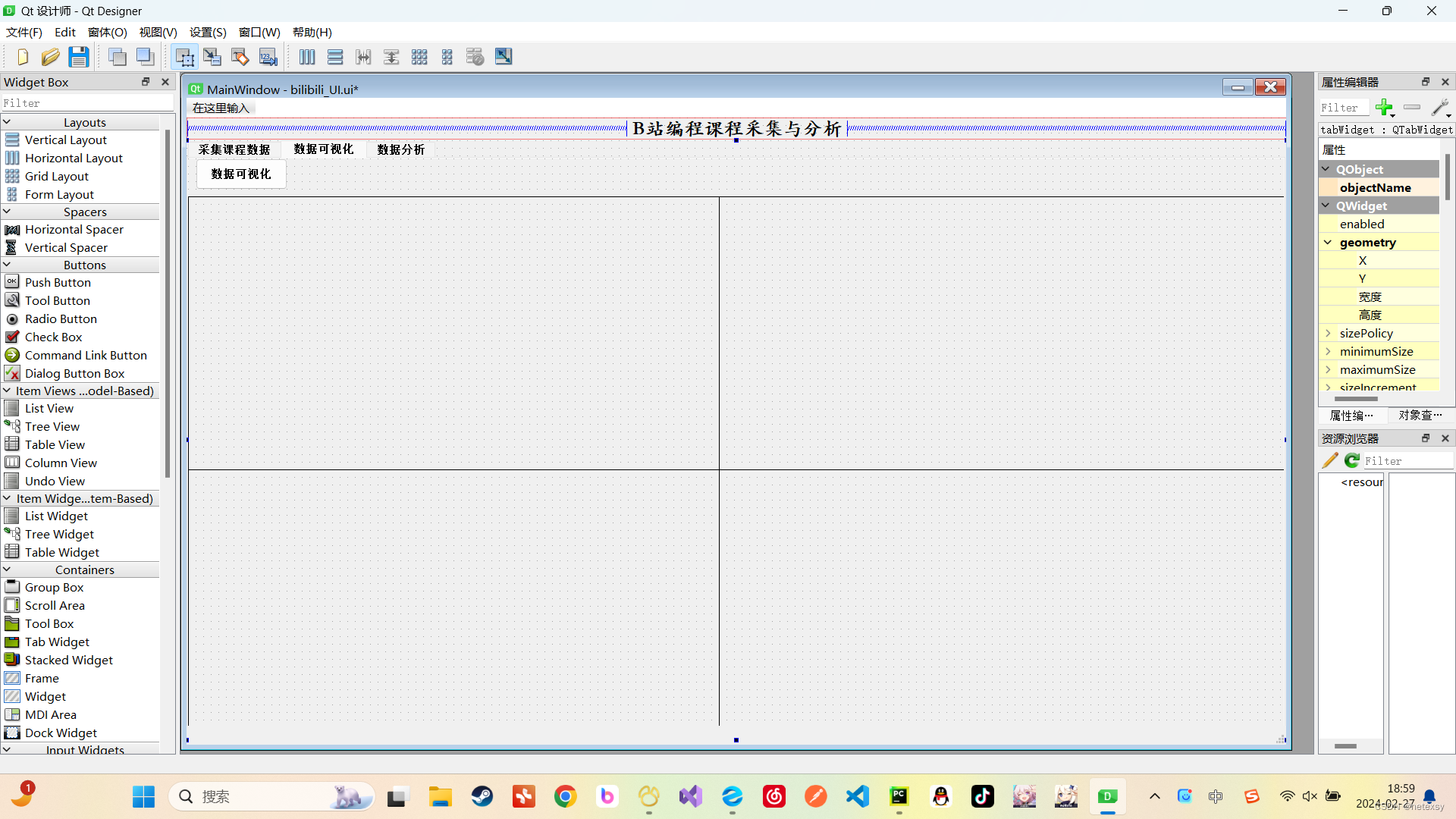
3、数据分析界面
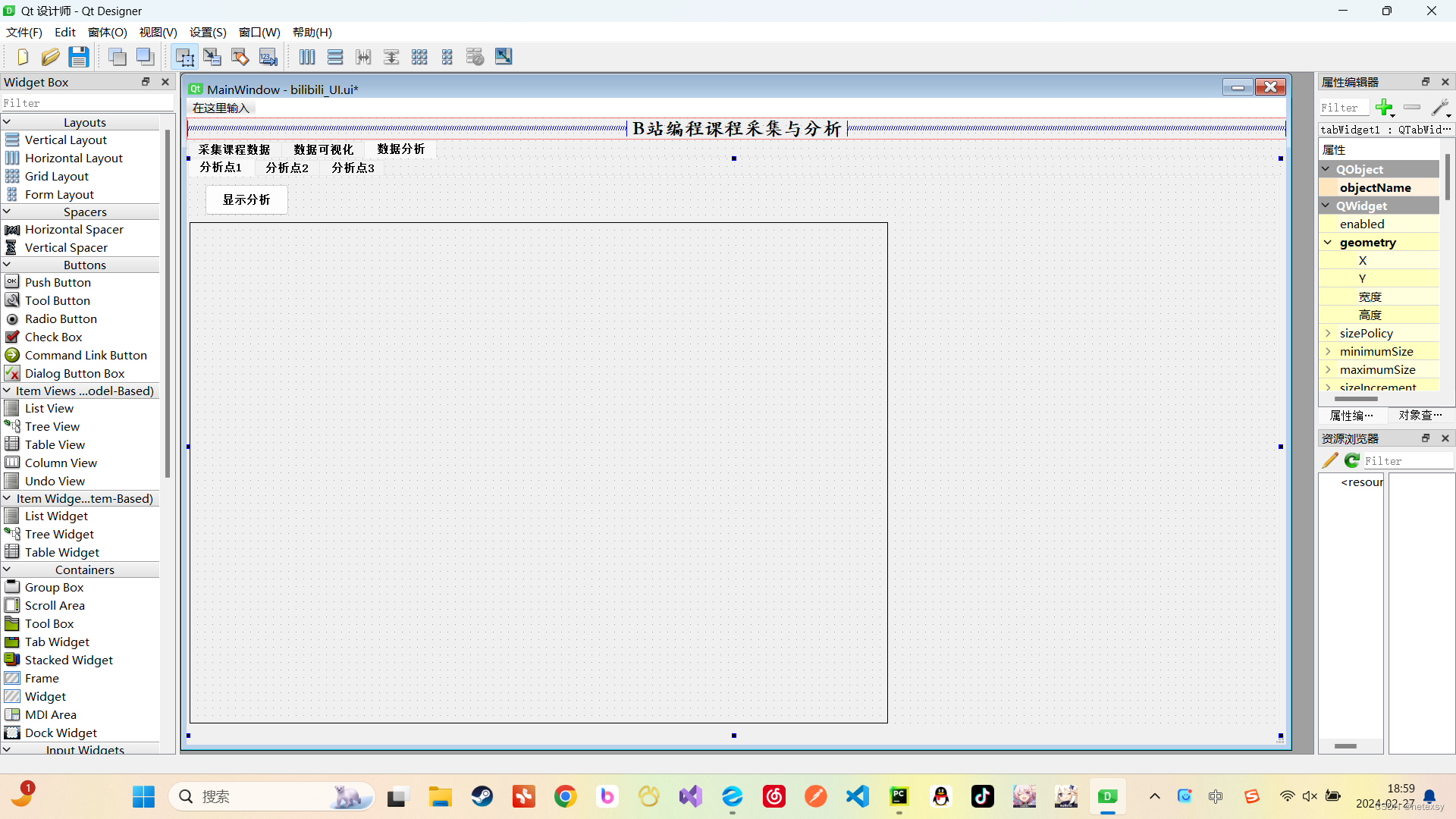
如果对于QtDesigner不熟悉的,可以看看我的这篇文章利用PySide2模块以及Qt设计师(Qt-Designer)设计简易的系统窗体
6、QThread多线程设计
想要实现爬取数据动态显示到界面上,我们需要使用Qt中的QThread类实现对于线程的创建与管理。
我们需要新建一个派生类DataThread(名称任意),该派生类由QThread这个基类派生,可以使用QThread中的相关成员函数,同时我们可以在DataThread这个由我们自己定义的派生类中进行相关修改。
DataThread派生类大致如下:
from PyQt5.QtCore import *
class DataThread(QThread):
signal = pyqtSignal(str, str, str, str, int, int, str)
def __init__(self):
QThread.__init__(self)
self.state = 1
def run(self):
pass
def Stop(self):
self.state = 0
1、其中 signal = pyqtSignal(str, str, str, str, int, int, str) 对应的每一个类型为我们所爬取的数据的类型,比如我使用的数据为:

VideoID(视频编号)、VideoName(视频名称)、VideoAuther(视频作者)、Category(视频类型)、VideoView(观看量)、Comment(评论数)、Duration(视频时长),对应的数据类型为字符串(str),字符串(str),字符串(str),字符串(str),整型(int),整型(int),字符串(str)。
2、其中 def __init__(self): 这个是初始化函数,可以用来设置全局变量,例如 self.state 表示的是当前线程的状态,1为进行中,0为停止,初始化为1。
3、其中 def run(self): 这个函数比较重要,我们需要将爬虫代码写在run函数中,并且每爬取一条数据,进行数据处理、分类后都要将数据传递出去
4、其中 def Stop(self): 这个函数用来控制线程的停止,当我需要停止的时候就调用该函数,那么线程就会停止,爬虫也会随之停止。
加上爬虫代码并根据个人的需求完善代码,完整DataThread类的代码如下:
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
import requests
from lxml import etree
class DataThread(QThread):
signal = pyqtSignal(str, str, str, str, int, int, str)
def __init__(self):
QThread.__init__(self)
self.state = 1
self.page_number = 1
self.o_number = 0
self.key = []
self.value = []
def run(self):
# while(self.state):
# 爬虫准备工作
base_url = 'https://search.bilibili.com/all?vt=77434542&keyword=%E7%BC%96%E7%A8%8B%E8%AF%BE%E7%A8%8B&from_source=webtop_search&spm_id_from=333.1007&search_source=5'
params = {}
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
# page_number = 1
# o_number = 0
unique_links = set()
video_data_by_keyword = ['C语言', 'C++', 'Python', 'PHP', '算法', 'Java', 'go语言','Mysql','C#','Scratch','web','计算机']
while self.page_number <= 34:
params['page'] = str(self.page_number)
params['o'] = str(self.o_number)
response = requests.get(base_url, params=params, headers=headers)
html = response.text
html = response.content.decode('utf-8')
parse = etree.HTMLParser(encoding='utf-8')
contentPath = []
contentname = []
contentauthor = []
contentVV = []
contentCM = []
contentDR = []
doc = etree.HTML(html)
doc.xpath('//div[@class="bili-video-card__info--right"]//a/@href')
contentPath = doc.xpath('//div[@class="bili-video-card__info--right"]/a/@href')
contentname = doc.xpath('//div[@class="bili-video-card__info--right"]//h3[@class="bili-video-card__info--tit"]/@title')
contentauthor = doc.xpath('//div[@class="bili-video-card__info--right"]//span[@class="bili-video-card__info--author"]/text()')
contentVV = doc.xpath('//div[@class="bili-video-card__stats--left"]/span[@class="bili-video-card__stats--item"][1]/span/text()')
contentCM = doc.xpath('//div[@class="bili-video-card__stats--left"]/span[@class="bili-video-card__stats--item"][2]/span/text()')
contentDR = doc.xpath('//div[@class="bili-video-card__stats"]/span[@class="bili-video-card__stats__duration"]/text()')
# print(contentVV)
# print(contentCM)
for link, name,auther,vv,cm,dr in zip(contentPath,contentname,contentauthor,contentVV,contentCM,contentDR):
category_found = False
VideoID = str(self.data)
VideoName = name
VideoAuther = auther
if vv[-1] == '万':
num = float(vv[0:-1])
num *= 10000
VideoView = int(num)
else:
VideoView = int(vv)
if cm[-1] == '万':
num = float(cm[0:-1])
num *= 10000
Comment = int(num)
else:
Comment = int(cm)
Duration = dr
Category = None
for keyword in video_data_by_keyword:
lower_keyword = keyword.lower() # 将关键词转换为小写
if lower_keyword in name.lower():
Category = keyword
if link not in unique_links:
if self.state:
self.signal.emit(VideoID, VideoName, VideoAuther, Category, VideoView, Comment, Duration)
self.data += 1
time.sleep(0.1)
unique_links.add(link)
break
self.page_number += 1
self.o_number += 24
def Stop(self):
self.state = 0
在这个代码中,爬虫代码不断爬取数据,通过 self.signal.emit(VideoID, VideoName, VideoAuther, Category, VideoView, Comment, Duration) 这行代码将数据传递到界面上。
7、通过UI界面实时显示数据
到最为关键的一步了,我们需要对设计好的UI界面进行初始化,并利用爬取好传递过来的数据来生成可视化图表,并实现实时自动刷新图表以及手动刷新图表。
还是和DataThread派生类一样,我们可以创建一个自己的窗口类MyWindow,继承于我们通过
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2016
2016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









