







 梯度提升树算法实际上是提升算法的扩展版,在原始的提升算法中,如果损失函数为平方损失或指数 损失,求解损失函数的最小值问题会非常简单,但如果损失函数为更一般的函数,目标值的求解就会相对 复杂很多。GBDT就是用来解决这个问题,利用损失函数的负梯度值作为该轮基础模型损失值的近似,并利 用这个近似值构建下一轮基础模型。
梯度提升树算法实际上是提升算法的扩展版,在原始的提升算法中,如果损失函数为平方损失或指数 损失,求解损失函数的最小值问题会非常简单,但如果损失函数为更一般的函数,目标值的求解就会相对 复杂很多。GBDT就是用来解决这个问题,利用损失函数的负梯度值作为该轮基础模型损失值的近似,并利 用这个近似值构建下一轮基础模型。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
AdaBoostClassifier(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm='SAMME.R', random_state=None)
1.base_estimator:用于指定提升算法所应用的基础分类器,默认为分类决策树(CART),也可以是其他基础分类器,但是分类器必须支持带样本权重的学习,如神经网络。
2.n_estimators:用于指定基础分类器的数量,默认为50个,当模型在训练集中得到完美的拟合后,可以提前结束算法,不一定非得构建完指定个数的基础分类器。
3.learning_rate:这里指模型迭代的学习率也称为步长,即所对应的提升模型F(x)可以表示为F(x)=Fm-1(x)+vamfm(x),其中v就是该参数的指定值,默认值为1;对于较小的学习率v而言,则需要迭代更多次的基础分类器,通常情况下需要利用交叉验证法确定合理的基础分类器个数和学习率。
4.algorithm:用于指定AdaBoostClassifier分类器的算法,默认为’SAMME.R’,也可以使用 ‘SAMME’;使用’SAMME.R’时,基础模型必须能够计算类别的概率值;一般言,‘SAMME.R’算法 相比于’SAMME’算法,收敛更快、误差更小、迭代数量更少。
5.loss:用于指定AdaBoostRegressor回归提升树的损失函数,可以是’linear’,表示使用线性损失函 数;也可以是’square’,表示使用平方损失函数;还可以是’exponential’,表示使用指数损失函数; 该参数的默认值为’linear’。
6.random_state:用于指定随机数生成器的种子。
🌻Adaboost回归算法
AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, loss='linear', random_state=None)
🐾GBDT模型讲解
🌳GBDT模型介绍
梯度提升树算法实际上是提升算法的扩展版,在原始的提升算法中,如果损失函数为平方损失或指数 损失,求解损失函数的最小值问题会非常简单,但如果损失函数为更一般的函数,目标值的求解就会相对 复杂很多。GBDT就是用来解决这个问题,利用损失函数的负梯度值作为该轮基础模型损失值的近似,并利 用这个近似值构建下一轮基础模型。
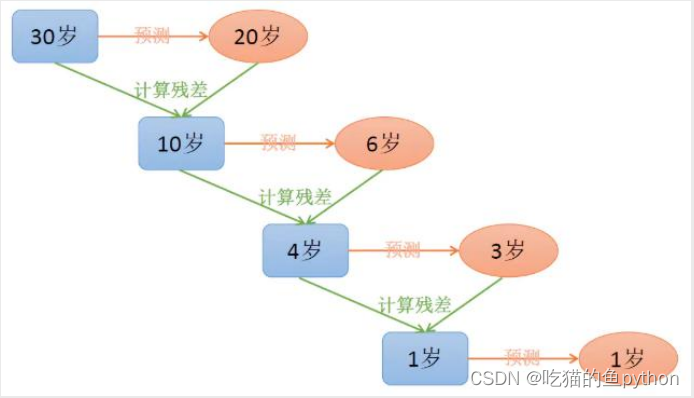
我们这个图就解释了关于GBDT模型的相关概念,首先我们第一个数预测结果是20岁,可是实际结果是30岁,那么我们返回残差值10岁,然后第二棵树预测结果是6岁,那么返回的残差值是4岁,继续预测,直到预测完成。那么这个时候我们将预测的数值反向加和,就得到了最终的预测结果30岁。

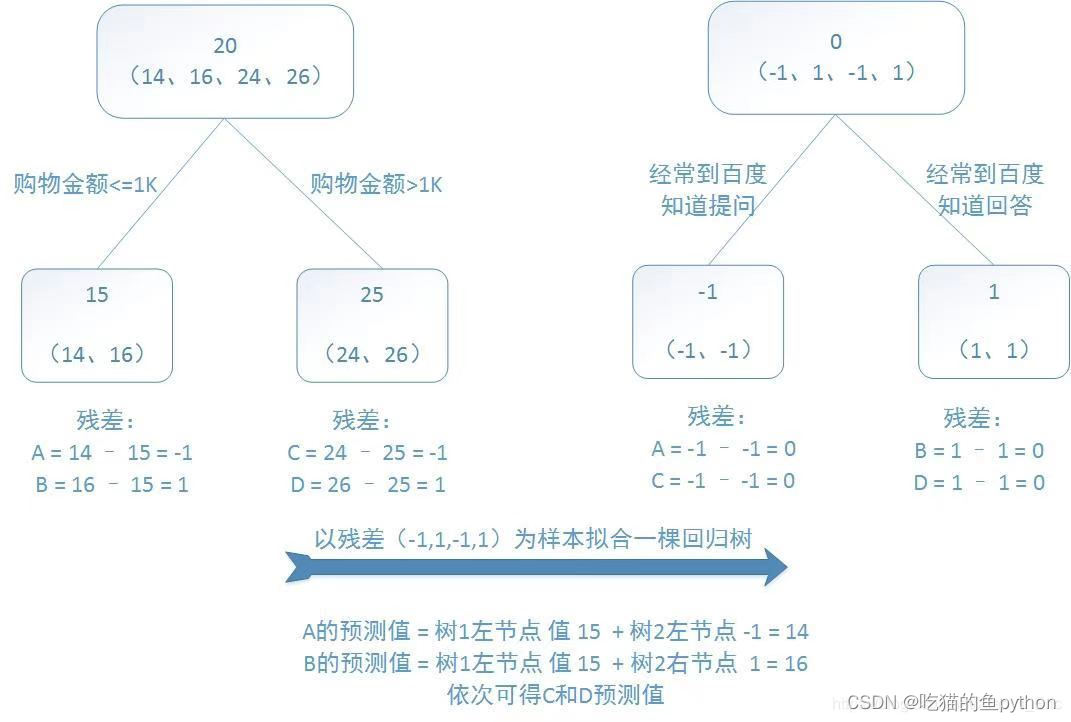
🌳GBDT算法步骤
1.初始化一颗仅仅包含根节点的决策树,并且寻找一个常数Count能够使
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









