








这里代码爬虫的主要功能是爬取疾病相关的信息,并将数据存储到MongoDB数据库中。代码的主要结构是一个名为MedicalSpider的类,它包含了各种方法来处理不同类型的数据采集任务。在代码的开头,导入了一些必要的库,如requests、urllib、lxml和pymongo。然后定义了一个MedicalSpider类,该类的构造函数初始化了MongoDB的连接,并指定了要使用的数据库和集合。
接下来是一系列方法,用于实现不同类型的数据采集。其中,get_html方法用于发送HTTP请求并获取网页的HTML内容。url_parser方法用于解析HTML内容,提取出需要的URL。basicinfo_spider方法用于解析疾病的基本信息,如名称、描述和所属目录。treat_spider、drug_spider和food_spider方法分别用于解析治疗信息、药物信息和食物信息。symptom_spider方法用于解析疾病的症状信息。inspect_spider方法用于解析疾病的检查信息。common_spider方法用于解析通用模块下的内容,如疾病预防和疾病起因。
在spider_main方法中,通过循环遍历页面,构造不同类型的URL,并调用相应的方法进行数据采集。采集到的数据以字典的形式存储,并插入到MongoDB数据库中。
最后,代码调用了MedicalSpider类的实例,并依次调用了inspect_crawl和spider_main方法,完成了数据的采集和存储。
总的来说,通过爬取寻医问药网站的相关页面,获取疾病的基本信息、治疗信息、药物信息、食物信息、症状信息和检查信息,并将数据存储到MongoDB数据库中。
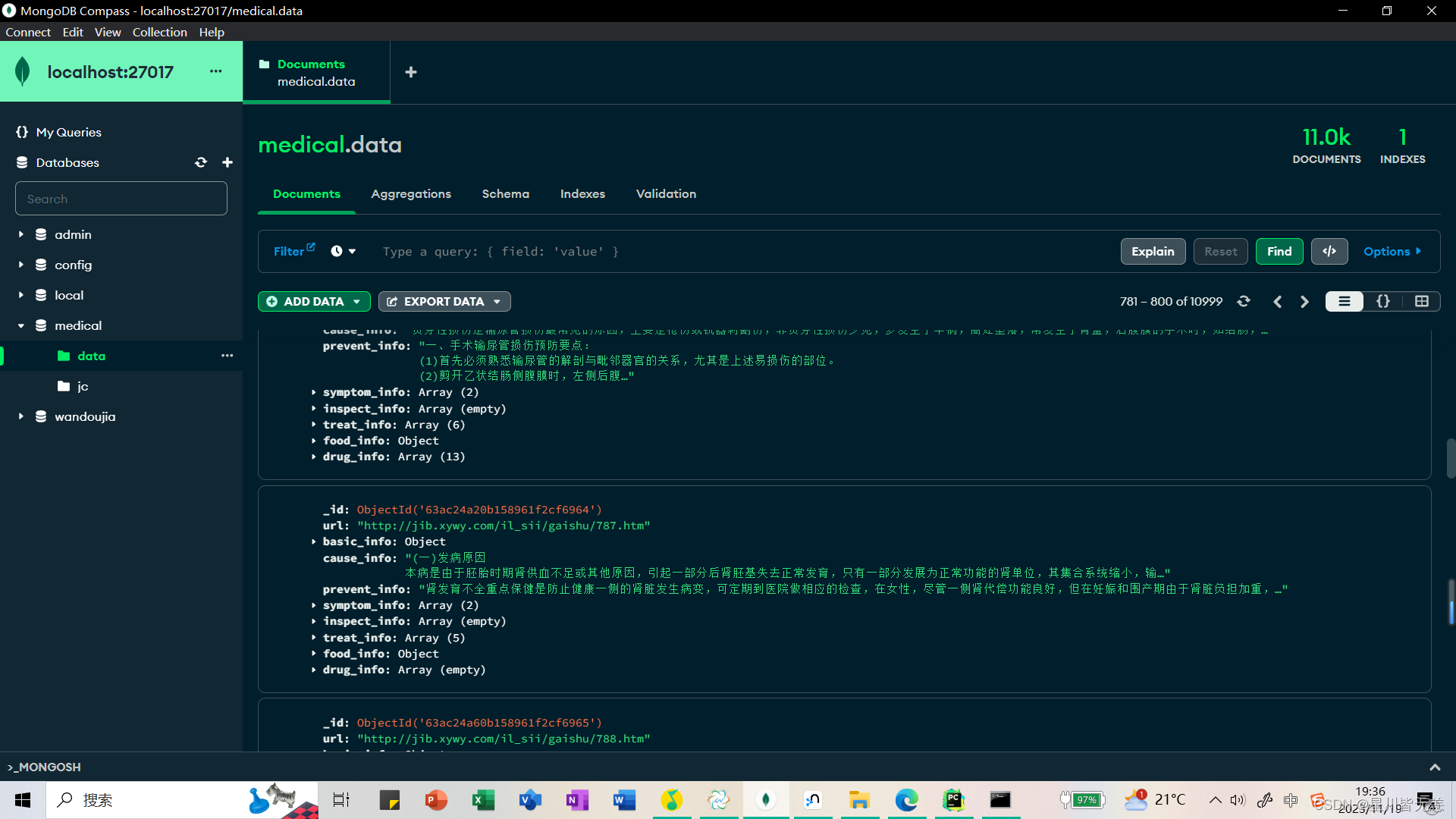
结束之后我们可以在MongoDB数据库中查看我们爬取到的疾病链接和解析出的网页内容:91496d548148a6a102d46a94d8c.png)
 贪心算法策略+Aho-Corasick算法
贪心算法策略+Aho-Corasick算法
本次知识图谱建模使用的最大向前匹配是一种贪心算法,从句首开始匹配,每次选择最长的词语。由于只需一次遍历,因此在速度上相对较快。 算法相对简单,容易实现和理解,不需要复杂的数据结构。 对于中文文本中大部分是左向的情况,最大向前匹配通常能够较好地切分。与最大向前匹配相反,最大向后匹配从句尾开始匹配,每次选择最长的词语。适用于大部分右向的中文文本。双向最大匹配结合了最大向前匹配和最大向后匹配的优势,从两个方向分别匹配,然后选择分词数量较少的一种结果。这种方法综合考虑了左向和右向的特点,提高了切分的准确性。
在多模式匹配方面, Aho-Corasick算法专门用于在一个文本中同时搜索多个模式(关键词)。相比于暴力搜
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









