







文章目录
学习目标
本文学习目标
● 了解什么是clickhouse
● 熟悉clickhouse的使用场景
● 学会clickhouse安装与使用
● 了解clickhouse引擎
● 学会Clickhouse SQL的操作
1. Clickhouse简介
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
友情提示ClickHouse 并不是数据仓库,它也不是数据导入和调度工具,它需要结合很多的组件来合作使用,包括:数仓、关联查询(eg:Presto、Drois、SPL、数据导入(eg:sea Tunnel)、调度…)
CK主要解决的是数据分析的最后一公里场景
1.1 历史背景
ClickHouse最初是为 YandexMetrica 世界第二大Web分析平台 而开发的。多年来一直作为该系统的核心组件被该系统持续使用着。目前为止,该系统在ClickHouse中有超过13万亿条记录,并且每天超过200多亿个事件被处理。它允许直接从原始数据中动态查询并生成报告。
Yandex.Metrica基于用户定义的字段,对实时访问、连接会话,生成实时的统计报表。这种需求往往需要复杂聚合方式,比如对访问用户进行去重。构建报表的数据,是实时接收存储的新数据。
截至2014年4月,Yandex.Metrica每天跟踪大约120亿个事件(用户的点击和浏览)。为了可以创建自定义的报表,我们必须存储全部这些事件。同时,这些查询可能需要在几百毫秒内扫描数百万行的数据,或在几秒内扫描数亿行的数据。
PS: 2021的9月ClickHouse 成立了独立的公司,开始集中人力放在云环境的部署中。目前国内的很多云厂商都推出自己的云部署方案。
1.1.1 版本号历史
● 2016年开源
● 第一阶段 2017-2018 版本1.1.X (命名规则为:Major.Minor.patch)
● 第二阶段 2018-2019 版本18.1.x—19.17.x (命名规则为:Year.Major.Minor.patch)
● 第三阶段 2020-至今 版本V20.1.2.4, 2020-01-22 – 至今
命名规则:Year.Major.Minor.patch , Minor 1 一般为测试版,大于1表示稳定版本(补丁版)。有重大的更新和新特性主要在Minor为2的版本。
官方作者解读:
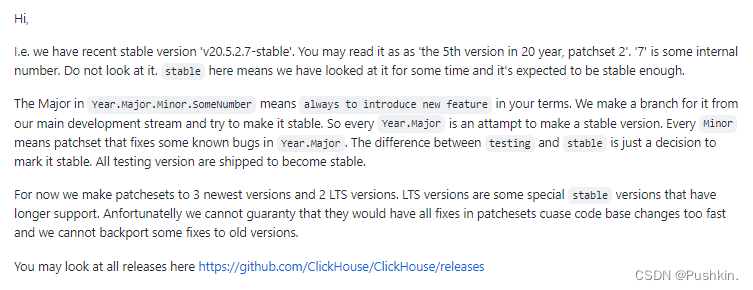
我们有最近的稳定版本'v20.5.2.7-stable'。
您可以将其理解为“20 年的第 5 个版本,补丁集 2”。 “7”是一些内部号码(不用太关注)。
这里的稳定意味着我们已经研究了一段时间,并且预计它足够稳定。
Year.Major.Minor.SomeNumber 中的 Major 意味着始终以您的方式引入新功能。
我们从我们的主要开发流中为其创建一个分支,并尝试使其稳定。
因此,每年 Year.Major 都会尝试制作一个稳定的版本。
Every Minor 表示修复 Year.Major 中一些已知错误的补丁集。
测试和稳定之间的区别只是将其标记为稳定的决定。所有测试版本均已发货以使其稳定。
目前我们为 3 个最新版本和 2 个 LTS 版本制作补丁集。
LTS 版本是一些特殊的稳定版本,支持时间更长。
不幸的是,我们无法保证他们会在补丁集中进行所有修复,因为代码库更改太快,
我们无法将某些修复向后移植到旧版本。
1.2 特性
1.2.1 真正的列式数据库管理系统
在一个真正的列式数据库管理系统中,除了数据本身外不应该存在其他额外的数据。这意味着为了避免在值旁边存储它们的长度«number»,你必须支持固定长度数值类型。例如,10亿个UInt8类型的数据在未压缩的情况下大约消耗1GB左右的空间,如果不是这样的话,这将对CPU的使用产生强烈影响。即使是在未压缩的情况下,紧凑的存储数据也是非常重要的,因为解压缩的速度主要取决于未压缩数据的大小。
这是非常值得注意的,因为在一些其他系统中也可以将不同的列分别进行存储,但由于对其他场景进行的优化,使其无法有效的处理分析查询。例如: HBase,BigTable,Cassandra,HyperTable。在这些系统中,你可以得到每秒数十万的吞吐能力,但是无法得到每秒几亿行的吞吐能力。
需要说明的是,ClickHouse不单单是一个数据库, 它是一个数据库管理系统。因为它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置或重启服务。
1.2.2 数据压缩
在一些列式数据库管理系统中(例如:InfiniDB CE 和 MonetDB) 并没有使用数据压缩。但是, 若想达到比较优异的性能,数据压缩确实起到了至关重要的作用。
除了在磁盘空间和CPU消耗之间进行不同权衡的高效通用压缩编解码器之外,ClickHouse还提供针对特定类型数据的专用编解码器,这使得ClickHouse能够与更小的数据库(如时间序列数据库)竞争并超越它们。
1.2.3 数据的磁盘存储
许多的列式数据库(如 SAP HANA, Google PowerDrill)只能在内存中工作,这种方式会造成比实际更多的设备预算。
ClickHouse被设计用于工作在传统磁盘上的系统,它提供每GB更低的存储成本,但如果可以使用SSD和内存,它也会合理的利用这些资源。
1.2.4 多核心并行处理
ClickHouse会使用服务器上一切可用的资源,从而以最自然的方式并行处理大型查询。
1.2.5 多服务器分布式处理
上面提到的列式数据库管理系统中,几乎没有一个支持分布式的查询处理。 在ClickHouse中,数据可以保存在不同的shard上,每一个shard都由一组用于容错的replica组成,查询可以并行地在所有shard上进行处理。这些对用户来说是透明的
1.2.6 支持SQL
ClickHouse支持一种基于SQL的声明式查询语言,它在许多情况下与ANSI SQL标准相同。
支持的查询GROUP BY, ORDER BY, FROM, JOIN, IN以及非相关子查询。
相关(依赖性)子查询和窗口函数暂不受支持,但将来会被实现。
1.2.7 向量引擎
为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。
1.2.8 实时的数据更新
ClickHouse支持在表中定义主键。为了使查询能够快速在主键中进行范围查找,数据总是以增量的方式有序的存储在MergeTree中。因此,数据可以持续不断地高效的写入到表中,并且写入的过程中不会存在任何加锁的行为。
1.2.9 索引
按照主键对数据进行排序,这将帮助ClickHouse在几十毫秒以内完成对数据特定值或范围的查找。
1.2.10 适合在线查询
在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。
1.2.11 支持近似计算
ClickHouse提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
● 用于近似计算的各类聚合函数,如:distinct values, medians, quantiles
● 基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据。
● 不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。这在数据聚合条件满足某些分布条件下,在提供相当准确的聚合结果的同时降低了计算资源的使用。
1.2.12 Adaptive Join Algorithm
ClickHouse支持自定义JOIN多个表,它更倾向于散列连接算法,如果有多个大表,则使用合并-连接算法
1.2.13 支持数据复制和数据完整性
ClickHouse使用异步的多主复制技术。当数据被写入任何一个可用副本后,系统会在后台将数据分发给其他副本,以保证系统在不同副本上保持相同的数据。在大多数情况下ClickHouse能在故障后自动恢复,在一些少数的复杂情况下需要手动恢复。
1.2.14 角色的访问控制
ClickHouse使用SQL查询实现用户帐户管理,并允许角色的访问控制,类似于ANSI SQL标准和流行的关系数据库管理系统。
1.2.15 限制
没有完整的事务支持。
缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR。
稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
1.3 使用场景
1.3.1 关键特征
- 绝大多数是读请求
- 数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
- 已添加到数据库的数据不能修改。
- 对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
- 宽表,即每个表包含着大量的列
- 查询相对较少(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许延迟大约50毫秒
- 列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
- 处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
- 事务不是必须的
- 对数据一致性要求低
- 每个查询有一个大表。除了他以外,其他的都很小。
- 查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
1.3.2 业务场景
ClickHouse 过去最常见的场景有三个:
用户行为分析:在采集用户行为日志之后,进行 PV、UV、留存、转化漏斗等操作,例如头条、快手、喜马拉雅等。
用户画像圈选:每个公司都拥有大量的用户和用户画像标签,如何快速从用户画像标签里圈选出某几类标签的人群,例如阿里、喜马拉雅等。
机器日志监控 & 查询:每台机器都产生大量日志,如何快速监控、查询机器日志,以确保整体服务没有问题。基本上所有的互联网公司都在这样使用 ClickHouse 的。
PS: 国内这两年大热的数字化转型,我们也看到很多的传统方向企业加入到 ClickHouse 社区使用者阵营,因为我们也能看到一些很有意思的场景,如:
- IOT 场景:一些钢铁厂用 ClickHouse 采集、监控、分析自己内部 IOT 数据。我知道的最大的集群超过 100 台了。
- 政府大数据:ClickHouse 赋能政府合作伙伴,针对政府大量结构化和非结构化数据,进行大量数据质量整理和搜索。
- 网管监控:针对一些特殊 APP、特殊网站的日志,快速分析和快速报警。
关于数字化转型,我多啰嗦两句。事实上,ClickHouse 解决的是“数据分析的最后一公里”,解决了很多数字化转型企业数据分析的效率问题,包括:
● 大数据建设完成后最终产出了大量的 BI 报表、OLAP 分析,数据驱动距离业务远。
● 有经验的业务分析人员无法快速获得需要的数据,或者需要复杂 NoSQL 技术。
● 数据驱动还是“人”驱动,还有大量的提数、出报表的需求,而很多报表往往只用一次。
● 业务快速变化要求更新速度高,数据流无法让业务人员上手。
我举例的这些都是企业在数据化升级当中遇到的问题,因为越来越多的运营、产品、决策都需要用到灵活查询的一手明细数据,过去传统的层层数据仓库,OLAP 已经不能满足这些需求了,这正是 ClickHouse 的拿手好戏。
3. 性能测评
TODO 待补充
4. 安装
系统要求:
ClickHouse可以在任何具有x86_64,AArch64或PowerPC64LE CPU架构的Linux,FreeBSD或Mac OS X上运行。
官方预构建的二进制文件通常针对x86_64进行编译,并利用SSE 4.2指令集,因此,除非另有说明,支持它的CPU使用将成为额外的系统需求。下面是检查当前CPU是否支持SSE 4.2的命令:
$ grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"

要在不支持SSE 4.2或AArch64,PowerPC64LE架构的处理器上运行ClickHouse,您应该通过适当的配置调整从源代码构建ClickHouse。
4.1 单机安装
推荐使用RPM方式安装
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
sudo yum install -y clickhouse-server clickhouse-client
sudo /etc/init.d/clickhouse-server start
clickhouse-client # or "clickhouse-client --password" if you set up a password.
然后运行命令安装:
sudo yum install clickhouse-server clickhouse-client
启动
如果没有service,可以运行如下命令在后台启动服务:
$ sudo /etc/init.d/clickhouse-server start
日志文件将输出在/var/log/clickhouse-server/文件夹。
如果服务器没有启动,检查/etc/clickhouse-server/config.xml中的配置。
您也可以手动从控制台启动服务器:
$ clickhouse-server --config-file=/etc/clickhouse-server/config.xml
在这种情况下,日志将被打印到控制台,这在开发过程中很方便。
如果配置文件在当前目录中,则不需要指定——config-file参数。默认情况下,它的路径为./config.xml。
ClickHouse支持访问限制设置。它们位于users.xml文件(与config.xml同级目录)。 默认情况下,允许default用户从任何地方访问,不需要密码。可查看user/default/networks。 更多信息,请参见Configuration Files。
启动服务后,您可以使用命令行客户端连接到它:
$ clickhouse-client
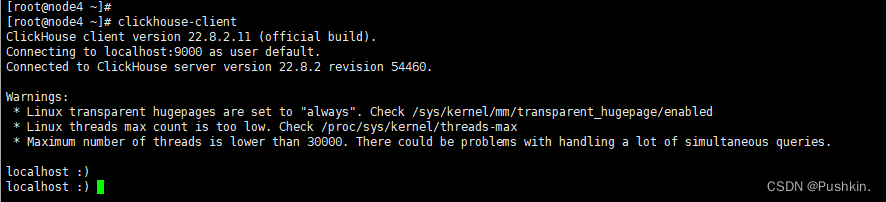
注意: clickhouse-client 默认是单行模式,即以 “换行符” 作为语句结束的标志。所以,即使不加分号也是可以的。如果在该模式下,需要输入多行语句,可以使用 “反斜杠” 来标识该行未结束,鉴于单行模式执行多行命令太麻烦,要在每行行末都加上反斜杠,因此就有了多行模式。
命令为 clickhouse-client -m,多行命令以分号作为命令结束的标识,而非换行符。
4.2 集群安装
● 安装java
● 安装Zookeeper(依赖Java)
● 安装单机ClickHouse
● 修改ClickHouse配置为集群版
安装java; zk 自行百度
4.2.1 修改clickhouse配置为集群版
备份默认配置文件:cp /etc/clickhouse-server/config.xml /etc/clickhouse-server/config.xml.bak
然后编辑默认配置文件 /etc/clickhouse-server/config.xml 并删除集群相关的配置
- 文件中<remote_servers></remote_servers>标签里的全部内容
- 文件中标签里的全部内容
- 文件中标签里的全部内容
添加自定义配置文件:vi /etc/clickhouse-server/config.d/config.xml 内容如下
<yandex>
<zookeeper>
<node index="1">
<host>zookeeper的服务器地址</host>
<port>2181</port>
</node>
<identity>zk_username:zk_password</identity>
<session_timeout_ms>600000</session_timeout_ms>
</zookeeper>
<remote_servers>
<test>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>本机IP</host>
<port>9000</port>
<user>default</user>
<password>password</password>
</replica>
</shard>
</test>
</remote_servers>
<networks>
<ip>::/0</ip>
</networks>
<macros>
<shard>01</shard>
<replica>node1</replica>
</macros>
</yandex>
然后重启CK即可:service clickhouse-server restart
4.2.1.1 配置解读
remote_servers 配置
- a. remote_servers下级节点为集群,可配置多个集群
- b. 集群下级节点为分片(shard),可配置多个shard,不同shard不能用同一个ClickHouse实例
- c. 分片下级为副本(replica),可对分片配置多个副本,默认最少0个,不同副本不能用同一个ClickHouse实例
- d. internal_replication 用来控制当数据写入时(必须是Replicated*的表),由分片自己负责副本间的数据复制,否则分布式表的副本数据写入需要由Distributed引擎来负责
macros 配置
- a. 本质上就是针对当前实例的全局变量的定义,可以被某些地方来引用
- b. 此配置需要在集群中全局唯一
- c. 此处的参数会在创建Replicated*的表时被引用
- d. shard的值为当前节点在在集群中的分片编号,需要在集群中唯一
- e. replica是副本的唯一标识,需要在单个分片的多个副本中唯一
5. 数据类型
截至目前20220918, ck支持的数据类型如下:

数据类型的说明与案例官方文章写的非常清楚,大家以官方文章为准
https://clickhouse.com/docs/zh/sql-reference/data-types/
5.1 类型分类
ClickHouse是一款分析型数据库,有多种数据库类型,分为:
● 基础类型
● 复合类型
● 特殊类型。
其中基础类型使用ClickHouse具备了描述数据的基本能力,而另外两种类型则是ClickHouse的数据表达能力更加丰富。
5.1.1 基础类型(三种):
- 数值:正型;浮点型;定点数Decimal
- 字符串 : String; FixedString; UUID
- 时间:DateTime、DateTime64、Date
注意1:
没有Boolean类型,但可以使用整型的0或1代替。
注意2:
建议您尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,例如货币数量或页面加载时间用毫秒为单位表示
注意: 使用浮点数计算可能会引起四舍五入的误差。
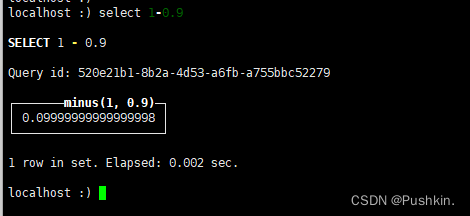
● 计算的结果取决于计算方法(计算机系统的处理器类型和体系结构)
● 浮点计算结果可能是诸如无穷大(INF)和«非数字»(NaN)。对浮点数计算的时候应该考虑到这点。
● 当一行行阅读浮点数的时候,浮点数的结果可能不是机器最近显示的数值。
注意3:
时间类型分为DateTime、DateTime64、Date。ClickHouse目前没有时间戳类型。时间类型最高的精度是秒,也就是说,如果需要毫秒、微妙等大于秒分辩率的时间,则只能借助UInt类型实现。
5.2.2 复合类型
ClickHouse还提供了数组、元祖、枚举和嵌套四类复合类型。这些类型通常是其他数据库原生不具备的特性。拥有了复合类型之后,ClickHouse的数据模型表达能力更强。
eg: Array、Tuple、Enum、Nested
5.3.3 特殊类型
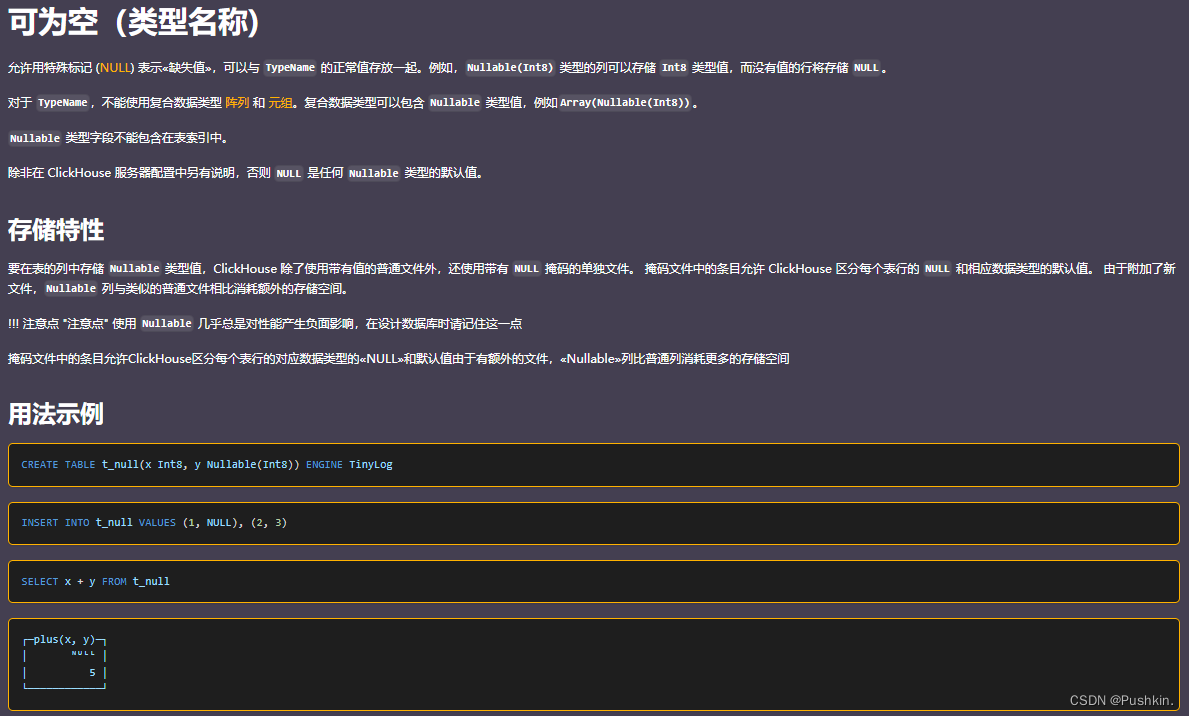
- Nullable 可为空类型:
- Domain 域类型
Domain类型是特定实现的类型,它总是与某个现存的基础类型保持二进制兼容的同时添加一些额外的特性,以能够在维持磁盘数据不变的情况下使用这些额外的特性。目前ClickHouse暂不支持自定义domain类型。
IPv4是与UInt32类型保持二进制兼容的Domain类型,其用于存储IPv4地址的值。它提供了更为紧凑的二进制存储的同时支持识别可读性更加友好的输入输出格式。
IPv6是与FixedString(16)类型保持二进制兼容的Domain类型,其用于存储IPv6地址的值。它提供了更为紧凑的二进制存储的同时支持识别可读性更加友好的输入输出格式。
6. 表引擎
表引擎算是Clickhouse核心特色了,非常的灵活,ck的争议很大的来源就是引擎的设计与使用,通常我们使用数据库的习惯是拿来就用,如何存储?如何查询?如何并发?如何备份等等都是底层封装好的,但CK的表引擎设计,就像我们从自动挡时代回到了手动挡时代,是缺点但更是其优点制胜点!!!
所以想要玩好clickhouse,就必须精通表引擎这个"手动挡",才能让我们在后续的工作中一路飙车~~~
表引擎(即表的类型)决定了:
● 数据的存储方式和位置,写到哪里以及从哪里读取数据
● 支持哪些查询以及如何支持。
● 并发数据访问。
● 索引的使用(如果存在)。
● 是否可以执行多线程请求。
● 数据复制参数。
表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关 参数。
6.1 引擎类型分类
● MergeTree
● 日志
● 集成引擎
● 用于其他特定功能的引擎
● 虚拟列
6.2 MergeTree
ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(MergeTree) 中的其他引擎,支持索引和分区,地位可以相当于 innodb 之于 Mysql。而且基于 MergeTree, 还衍生除了很多小弟,也是非常有特色的引擎。
案例练习
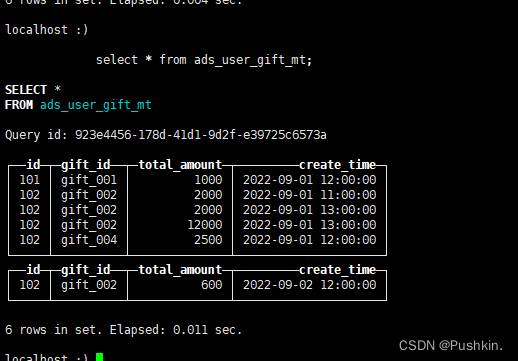
-- DDL
create table ads_user_gift_mt(
id UInt32,
gift_id String,
total_amount Decimal(16,2),
create_time Datetime
) engine =MergeTree
partition by toYYYYMMDD(create_time)
primary key (id)
order by (id,gift_id);
-- 数据
insert into ads_user_gift_mt values
(101,'gift\_001',1000.00,'2022-09-01 12:00:00') ,
(102,'gift\_002',2000.00,'2022-09-01 11:00:00'),
(102,'gift\_004',2500.00,'2022-09-01 12:00:00'),
(102,'gift\_002',2000.00,'2022-09-01 13:00:00'),
(102,'gift\_002',12000.00,'2022-09-01 13:00:00'),
(102,'gift\_002',600.00,'2022-09-02 12:00:00');

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
_002’,2000.00,‘2022-09-01 11:00:00’),
(102,‘gift_004’,2500.00,‘2022-09-01 12:00:00’),
(102,‘gift_002’,2000.00,‘2022-09-01 13:00:00’),
(102,‘gift_002’,12000.00,‘2022-09-01 13:00:00’),
(102,‘gift_002’,600.00,‘2022-09-02 12:00:00’);

[外链图片转存中...(img-XP1oPqfa-1714671839903)]
[外链图片转存中...(img-ptOSTami-1714671839904)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









