








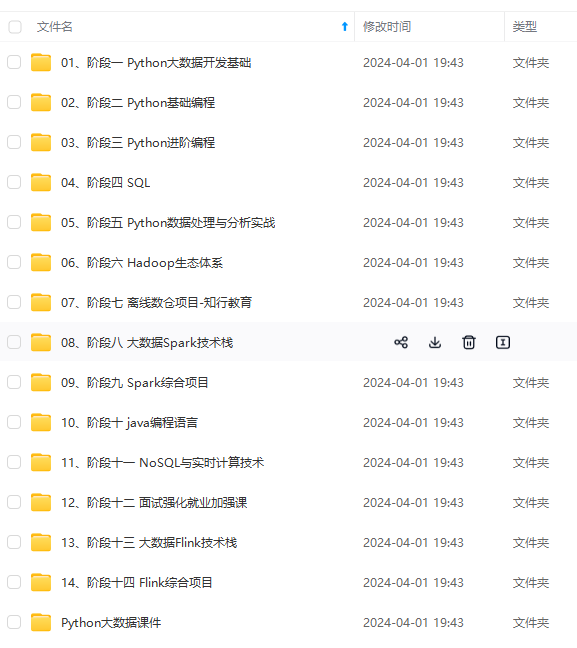
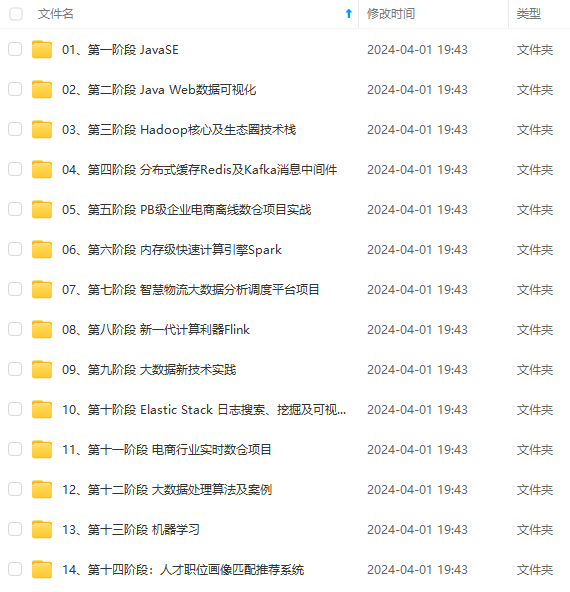
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
接下来我们要做的另一个小调整是删除图片链接,得到提取的
word
links <- "https://t.co/[A-Za-z\\d]+|&"
tweet_words <- campaign_tweets %>%
mutate(text = str_replace_all(text, links, "")) %>%
unnest_tokens(word, text, token = "tweets")
接下来我们来看一下哪些单词出现的次数最多
tweet_words %>%
count(word) %>%
top_n(10, n) %>%
mutate(word = reorder(word, n)) %>%
arrange(desc(n))
A tibble: 10 × 2
| word | n |
|---|---|
| the | 2329 |
| to | 1410 |
| and | 1239 |
| in | 1185 |
| i | 1143 |
| a | 1112 |
| you | 999 |
| of | 982 |
| is | 942 |
| on | 874 |
不难理解这些词出现的次数最多。但是这些词没有提供信息。 tidytext包有这些常用词的数据库,称为停用词,在文本挖掘中:
stop_words可以查看常见的停用词
head(stop_words)
A tibble: 6 × 2
| word | lexicon |
|---|---|
| a | SMArT |
| a’s | SMArT |
| able | SMArT |
| about | SMArT |
| above | SMArT |
| according | SMArT |
接下来我们删选掉属于停用词的文本
tweet_words <- campaign_tweets %>%
mutate(text = str_replace_all(text, links, "")) %>%
unnest_tokens(word, text, token = "tweets") %>%
filter(!word %in% stop_words$word )
tweet_words %>%
count(word) %>%
top_n(10, n) %>%
mutate(word = reorder(word, n)) %>%
arrange(desc(n))
A tibble: 10 × 2
| word | n |
|---|---|
| #trump2016 | 414 |
| hillary | 405 |
| people | 303 |
| #makeamericagreatagain | 294 |
| america | 254 |
| clinton | 237 |
| poll | 217 |
| crooked | 205 |
| trump | 195 |
| cruz | 159 |
可以看出这个时候出现最多的次数的
word能给我们一些信息,但是我们还要进行一个正则删选掉一些特殊的标记
tweet_words <- campaign_tweets %>%
mutate(text = str_replace_all(text, links, "")) %>%
unnest_tokens(word, text, token = "tweets") %>%
filter(!word %in% stop_words$word &
!str_detect(word, "^\\d+$")) %>%
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









