







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

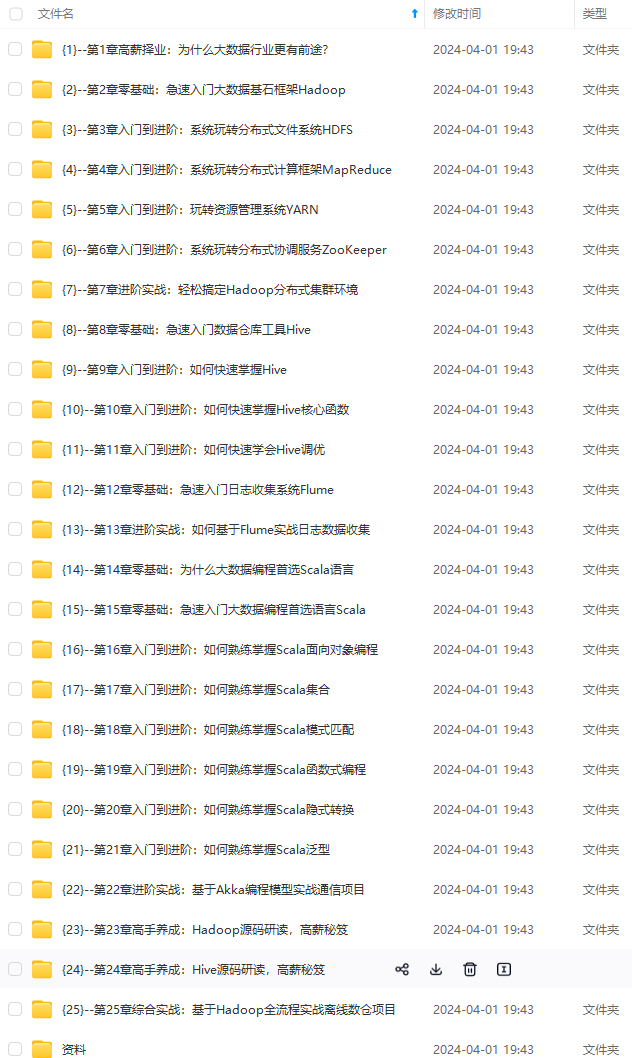
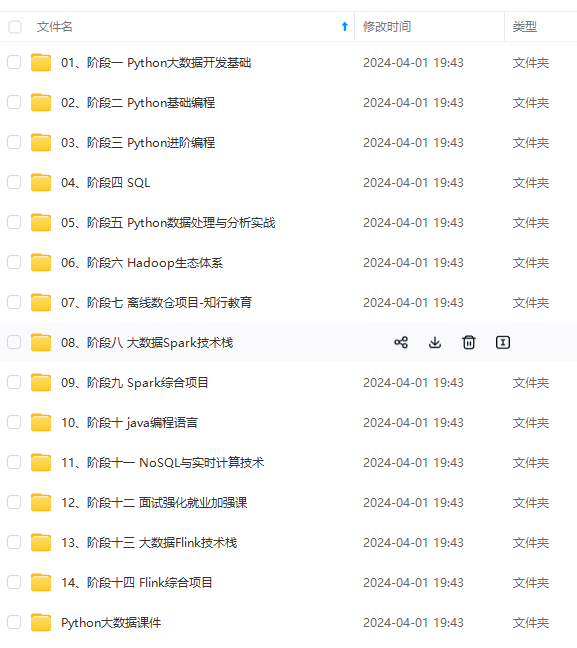
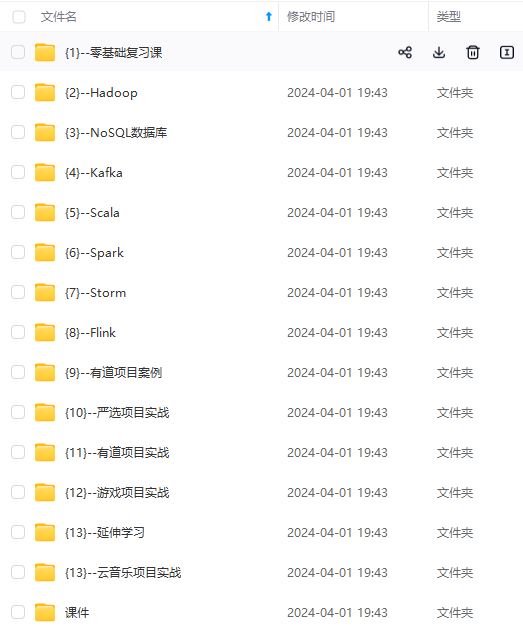
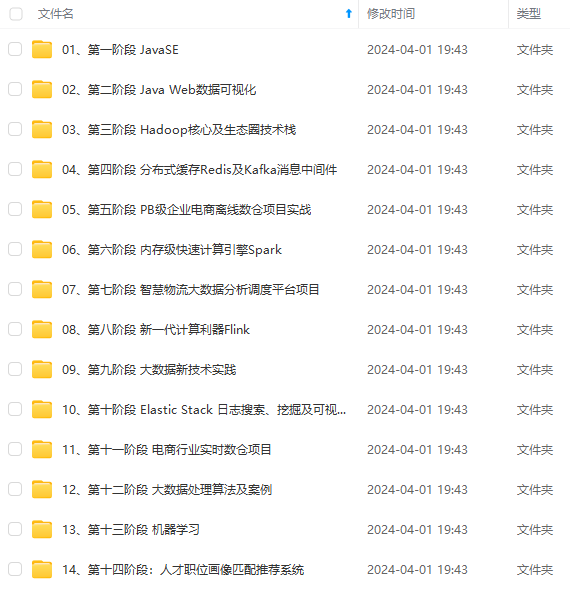
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
3.col_name为需要创建索引的字段列,该列必须从数据表中该定义的多个列中选择
4.index_name指定索引的名称,为可选参数,如果不指定,默认col_name为索引值
5.length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度
6.asc或desc指定升序或降序的索引值存储
普通索引 normal
normal 是最基本的索引,它没有任何限制,唯一任务是加快对数据的访问速度,最经常出现在查询条件(WHERE column=)或者排序条件(ORDERBY column)中的数据列创建索引
#直接创建索引
CREATE INDEX index_name ON table(column(length))
#修改表结构的方式添加索引
ALTER TABLE table_name ADD INDEX index_name ON (column(length))
#创建表的时候同时创建索引
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
PRIMARY KEY (`id`),
INDEX index_name (title(length))
)
#删除索引
DROP INDEX index_name ON table
唯一索引 unique
保证数据记录的唯一性,事实上,在许多场合,很多人创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复
与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
优点:
- 保证数据库表中每一行数据的唯一性。
- 大大提高检索的数据,以及减少表的检索行数。
- 在表连接的连接条件,可以加速表与表直接的相连。
- 在分组和排序字句进行数据检索,可以减少查询时间中分组和排序时所消耗的时间(数据库的记录会重新排序)。
#创建唯一索引
CREATE UNIQUE INDEX indexName ON table(column(length))
#修改表结构
ALTER TABLE table_name ADD UNIQUE indexName ON (column(length))
#创建表的时候直接指定
CREATE TABLE `table` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`title` char(255) CHARACTER NOT NULL ,
`content` text CHARACTER NULL ,
`time` int(10) NULL DEFAULT NULL ,
UNIQUE indexName (title(length))
);
主键索引
一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5121
5121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









