







- 当前的 BeanFactory 中的 beanDefinitionMap 容器中是否存在当前 bean对应的 BeanDefinition ,如果不存在则会去父类中继续获取,然后重新调用其父类对应的 getBean() 方法。
经过一系列的判断之后,会判断出当前 Bean 是原型还是单例,然后走不同的处理逻辑,但是不论是原型还是单例对象,最终其都会调用
AbstractAutowireCapableBeanFactory 类中的 createBean 方法进行创建 bean 实例
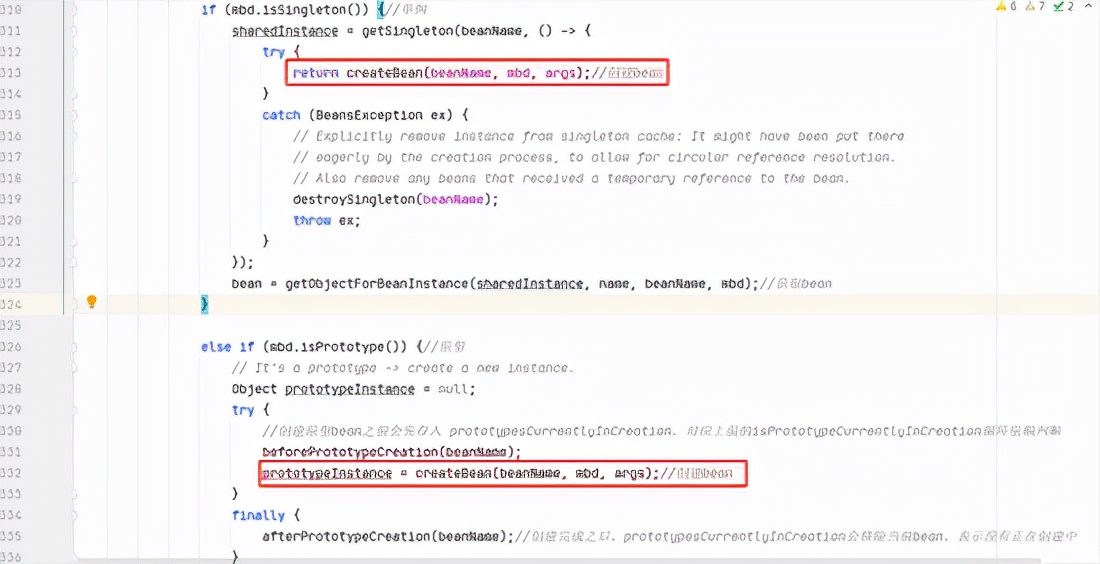
AbstractAutowireCapableBeanFactory#createBean
=============================================
这个方法里面会先确认当前情况 bean 是否可以被实例化,然后会有两个主要逻辑:
bean
这里面的第一个逻辑我们不重点分析,在这里我们主要还是分析第二个逻辑,如何创建一个 bean 实例:
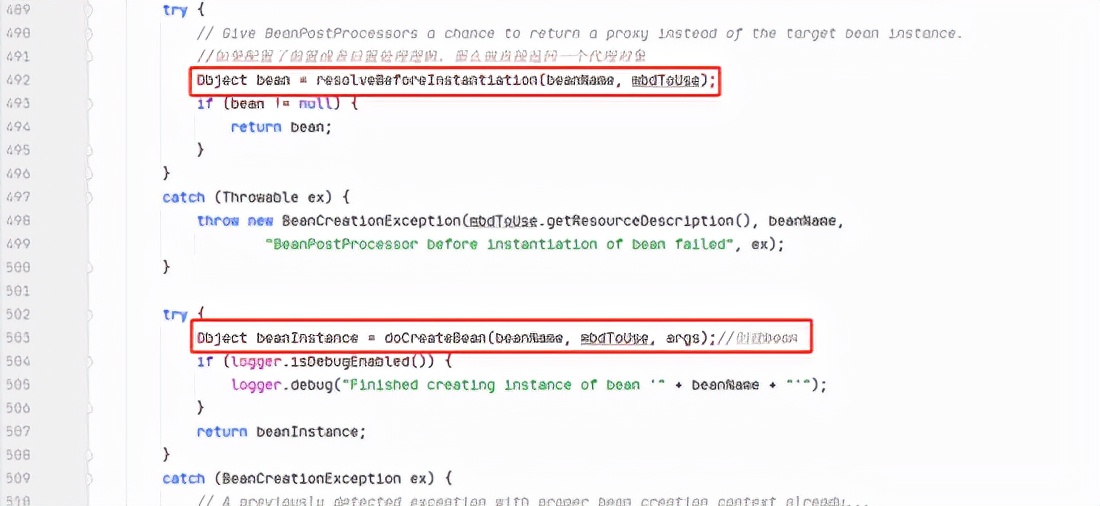
AbstractAutowireCapableBeanFactory#doCreateBean
===============================================
这又是一个以 do 开头的方法,说明这里面会真正创建一个 bean 实例对象,在分析这个方法之前,我们先自己来设想一下,假如是我们自己来实现,这个方法需要做什么操作?
在这个方法中,最核心的就是做两件事:
-
实例化一个 bean 对象。
-
遍历当前对象的属性,如果需要则注入其他 bean ,如果发现需要注入的 bean 还没有实例化,则需要先进行实例化。
创建 bean 实例(AbstractAutowireCapableBeanFactory#createBeanInstance)
=================================================================
在 doCreateBean 方法中,会调用 createBeanInstance 用方法来实例化一个 bean 。这里面也会有一系列逻辑去处理,比如判断这个类是不是具有 public 权限等等,但是最终还是会通过反射去调用当前 bean 的无参构造器或者有参构造器来初始化一个 bean 实例,然后再将其封装成一个 BeanWrapper 对象返回。
不过如果这里调用的是一个有参构造器,而这个参数也是一个 bean ,那么也会触发先去初始化参数中的 bean ,初始化 bean 实例除了有参考构造器形式之外,相对还是比较容易理解,我们就不过多去分析细节,主要重点是分析依赖注入的处理方式。
依赖注入(AbstractAutowireCapableBeanFactory#populateBean)
=====================================================
在上面创建 Bean 实例完成的时候,我们的对象并不完整,因为还只是仅仅创建了一个实例,而实例中的注入的属性却并未进行填充,所以接下来就还需要完成依赖注入的动作,那么在依赖注入的时候,如果发现需要注入的对象尚未初始化,还需要触发注入对象的初始化动作,同时在注入的时候也会分为按名称注入和按类型注入(除此之外还有构造器注入等方式):
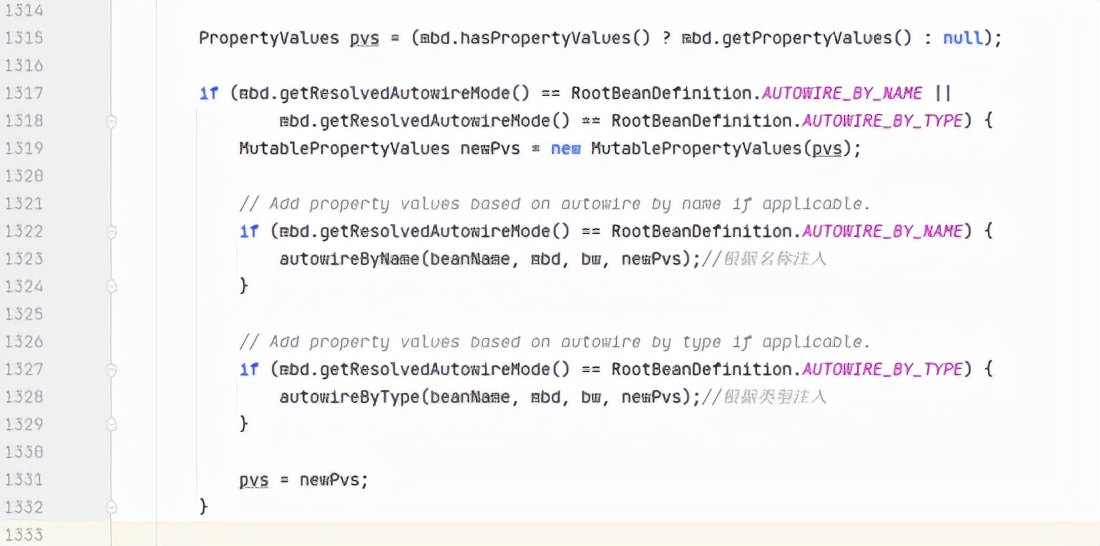
我们在依赖注入的时候最常用的是 @Autowired 和 @Resource 两个注解,而这两个注解的区别之一就是一个按照类型注入,另一个优先按照名称注入(没有找到名称就会按照类型注入),但是实际上这两个注解都不会走上面的按名称注入和按类型注入的逻辑,而是都是通过对应的
AutowiredAnnotationBeanPostProcessor 和
CommonAnnotationBeanPostProcessor 两个 Bean 的后置处理器来实现的,而且 @Resource 注解当无法通过名称找到 Bean 时也会根据类型去注入,在这里具体的处理细节我们就不过多展开分析,毕竟我们今天的目标是分析整个依赖注入的流程,如果过多纠结于这些分支细节,反而会使大家更加困惑。
上面通过根据名称或者根据属性解析出依赖的属性之后,会将其封装到对象MutablePropertyValues (即: PropertyValues 接口的实现类) 中,最后会再调用 applyPropertyValues() 方法进行真正的属性注入:
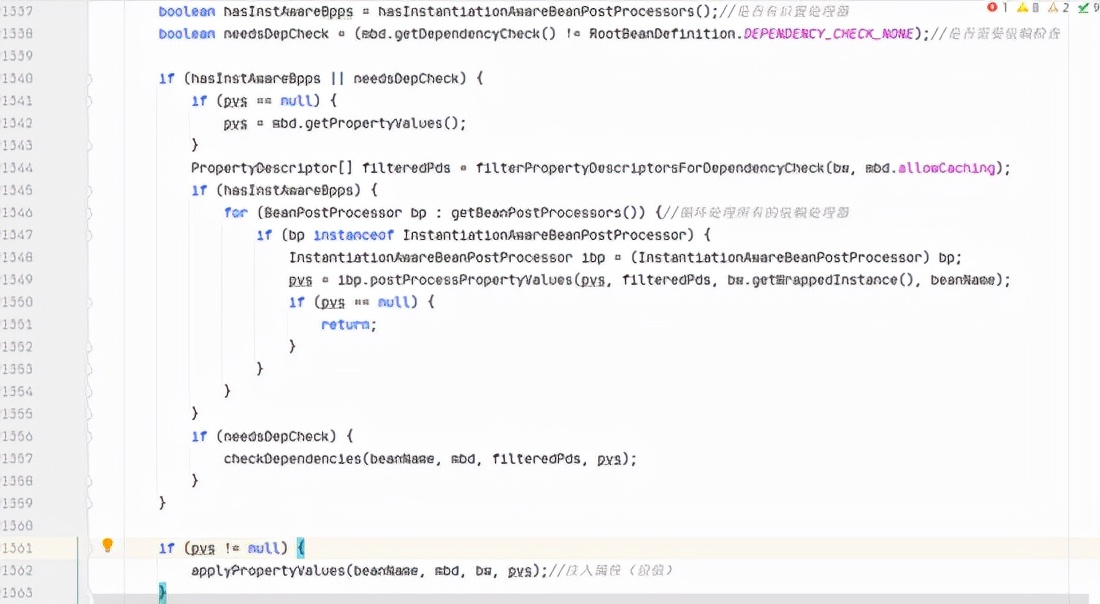
处理完之后,最后会再调用 applyPropertyValues() 方法进行真正的属性注入。
循环依赖问题是怎么解决的
============
依赖注入成功之后,整个 DI 流水就算结束了,但是有一个问题我们没有提到,那就是循环依赖问题,循环依赖指的是当我们有两个类 A 和 B ,其中 A 依赖 B , B又依赖了 A ,或者多个类也一样,只要形成了一个环状依赖那就属于循环依赖,比如下面的配置就是一个典型的循环依赖配置:
而我们前面讲解 Bean 的初始化时又讲到了当我们初始化 A 的时候,如果发现其依赖了 B ,那么会触发 B 的初始化,可是 B 又依赖了 A ,导致其无法完成初始化,这时候我们应该怎么解决这个问题呢?
在了解 Spring 中是如何解决这个问题之前,我们自己先想一下,如果换成我们来开发,我们会如何解决这个问题呢?其实方法也很简单,大家应该都能想到,那就是当我们把 Bean 初始化之后,在没有注入属性之前,就先缓存起来,这样,就相当于缓存了一个半成品 Bean 来提前暴露出来供注入时使用。
不过解决循环依赖也是有前提的,以下三种情形就无法解决循环依赖问题:
-
构造器注入产生的循环依赖。通过构造器注入产生的循环依赖会在第一步初始化就失败,所以也无法提前暴露出来。
-
非单例模式 Bean ,因为只有在单例模式下才会对 Bean 进行缓存。
-
手动设置了 allowCircularReferences=false ,则表示不允许循环依赖。
而在 Spring 当中处理循环依赖也是这个思路,只不过 Spring 中为了考虑设计问题,并非仅仅只采用了一个缓存,而是采用了三个缓存,这也就是面试中经常被问到的循环依赖相关的三级缓存问题(这里我个人意见是不太认同三级缓存这种叫法的,毕竟这三个缓存是在同一个类中的三个不同容器而已,并没有层级关系,这一点和 MyBatis 中使用到的两级缓存还是有区别的,不过既然大家都这么叫,咱一个凡人也就随波逐流了)。
Spring 中解决循环依赖的三级缓存
===================
如下图所示,在 Spring 中通过以下三个容器( Map 集合)来缓存单例 Bean :
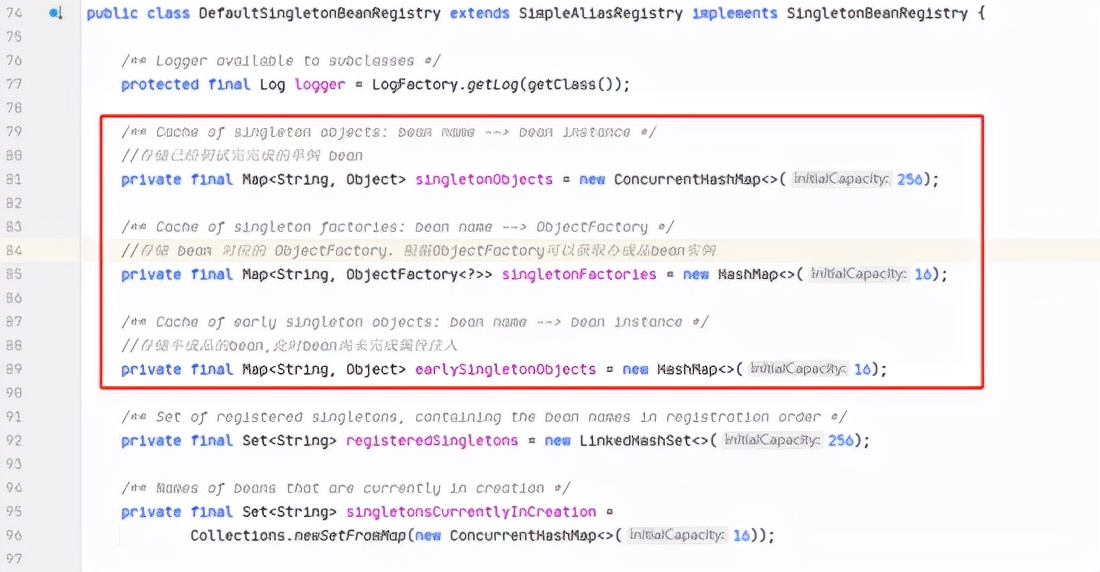
- singletonObjects
这个容器用来存储成品的单例 Bean ,也就是所谓的第一级缓存。
- earlySingletonObjects
这个用来存储半成品的单例 Bean ,也就是初始化之后还没有注入属性的 Bean,也就是所谓的第二级缓存。
- singletonFactories
存储的是 Bean 工厂对象,可以用来生成半成品的 Bean ,这也就是所谓的三级缓存。
为什么需要三级缓存才能解决循环依赖问题
===================
看了上面的三级缓存,不知道大家有没有疑问,因为第一级缓存和第二级缓存都比较好理解,一个成品一个半成品,这个都没什么好说的,那么为什么又需要第三级缓存呢,这又是出于什么考虑呢?
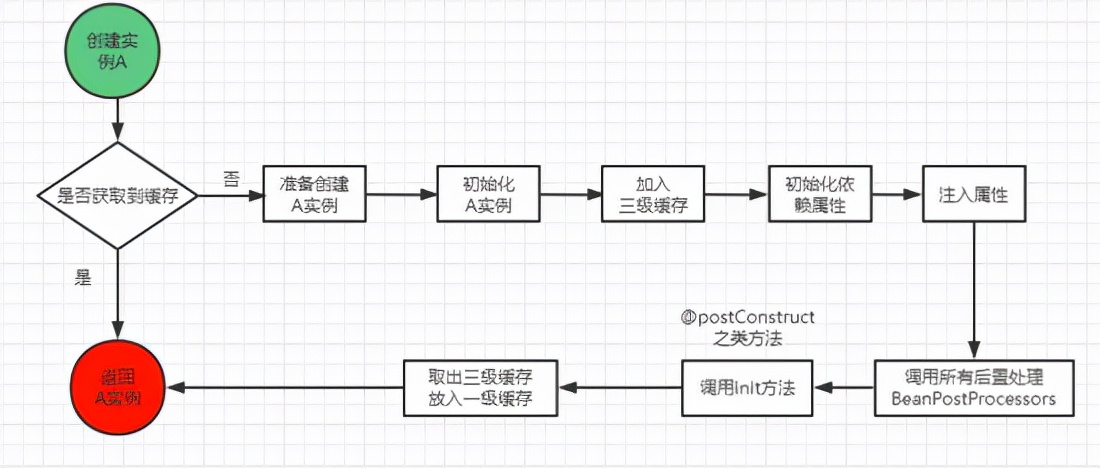
回答这个问题之前,我梳理了有循环依赖和没有循环依赖两种场景的流程图来进行对比分析:
没有循环依赖的创建 Bean A 流程:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数同学面临毕业设计项目选题时,很多人都会感到无从下手,尤其是对于计算机专业的学生来说,选择一个合适的题目尤为重要。因为毕业设计不仅是我们在大学四年学习的一个总结,更是展示自己能力的重要机会。
因此收集整理了一份《2024年计算机毕业设计项目大全》,初衷也很简单,就是希望能够帮助提高效率,同时减轻大家的负担。
既有Java、Web、PHP、也有C、小程序、Python等项目供你选择,真正体系化!
由于项目比较多,这里只是将部分目录截图出来,每个节点里面都包含素材文档、项目源码、讲解视频
如果你觉得这些内容对你有帮助,可以添加VX:vip1024c (备注项目大全获取)

中…(img-xA5GazV1-1712555152262)]
既有Java、Web、PHP、也有C、小程序、Python等项目供你选择,真正体系化!
由于项目比较多,这里只是将部分目录截图出来,每个节点里面都包含素材文档、项目源码、讲解视频
如果你觉得这些内容对你有帮助,可以添加VX:vip1024c (备注项目大全获取)
[外链图片转存中…(img-tqK2N7hM-1712555152263)]















 292
292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









