







我们简单介绍一下每一个概念的具体含义:
Producer(生产者):生产消息的一方,向Kafka实例推送消息的客户端。
Consumer(消费者):消费消息的一方,从Kafka实例拉取消息的客户端。
Consumer Group(消费者组):Kafka消费信息是按消费者组来的,一个消费者组内包含多个消费者,这些消费者共享一个组id
Broker(代理):一个独立的Kafka实例。多个Kafka实例(broker)组成一个Kafka集群。
Topic(主题):同类消息的集合是逻辑概念。生产者按主题生产消息,消费者按主题消费消息。
Partition(分区):Partition是物理概念,将同一Topic分布到多个Broker。例如上图Topic A被分成三个分区(Part0、Part1、Part2),分布在三个Broker。Kafka多分区可以提升消息消费速度(多消费者消费同一主题消息)。
Replica(副本):Leader和Follower的集合,一个Topic的每个分区都有若干副本(一个Leader,多个Follower)。多副本可以实现数据备份,提高Kafka的可用性。
Leader(主副本):每个分区多个副本的主副本,生产者和消费者操作的对象。
Follower(从副本):每个分区多个副本的从副本,实时从主副本同步数据,当Leader发生故障某个Follower成为新的Leader对外提供服务。
1.2.Kafka存储机制
Kafka的数据最终都会存储到磁盘中,最直观的感受就是一个个文件。这些文件是怎么存储和管理的呢。
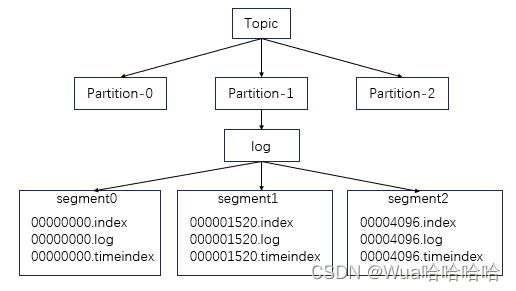
为了提升并发,Kafka会将同一话题(Topic)的消息分布在不同的分区(Partition)上。
其中每个分区会对应一个log文件,在log文件过大时,会存在数据定位效率低下的问题。为了解决这个问题Kafka采用了分片和索引机制,将每个分区(partition)分为多个segment,每个segement分为.index文件、.log文件和.timeindex文件。
其中segement是逻辑存在的,具有相同文件名前缀的XXX.index、XXX.log、XXX.timeindex为同一个segment。其中文件前缀为同一个segment中所有消息的最小offset。例如00000000.index对应segment中最小的offset是0,00004096.index对应segment中最小的offset是4096。
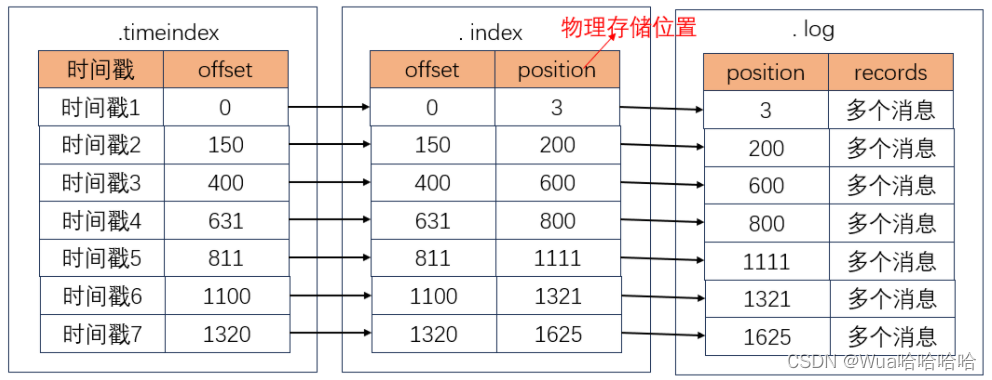
消息的存储方式了解了,如何通过offset找到消息?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**














 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









