







* ssh免密码登陆(本步骤可以省略,但是后面你重启hadoop进程时是需要手工输入密码才行)
ssh-keygen -t rsa
cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
4)Hadoop配置文件修改:`~/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop`
* hadoop-env.sh
配置Java目录`export JAVA_HOME=/home/hadoop/app/jdk1.7.0_51`
* core-site.xml
配置伪分布式
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/tmp</value>
</property>
* hdfs-site.xml
调整副本系数
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
5)格式化HDFS
注意:这一步操作,**只是在第一次时执行** ,每次如果都格式化的话,那么HDFS上的数据就会被清空
`~/app/hadoop-2.6.0-cdh5.7.0/bin/hdfs namenode -format`
看到下面日志表示成功
X X X X Xhas been successfully formatted.
6)启动HDFS
`~/app/hadoop-2.6.0-cdh5.7.0/sbin/start-dfs.sh`
验证是否启动成功:
jps
DataNode
SecondaryNameNode
NameNode
浏览器
http://hadoop001:50070/
7)停止HDFS
`sbin/stop-dfs.sh`
#### HDFS命令
[hadoop@hadoop000 bin]$ ./hadoop
Usage: hadoop [–config confdir] COMMAND
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar run a jar file
checknative [-a|-h] check native hadoop and compression libraries availability
distcp copy file or directories recursively
archive -archiveName NAME -p * create a hadoop archive
classpath prints the class path needed to get the
credential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
s3guard manage data on S3
trace view and modify Hadoop tracing settings
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
[hadoop@hadoop000 bin]$ ./hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile … ]
[-cat [-ignoreCrc] …]
[-chgrp [-R] GROUP PATH…]
[-chmod [-R] <MODE[,MODE]… | OCTALMODE> PATH…]
[-chown [-R] [OWNER][:[GROUP]] PATH…]
[-copyFromLocal [-f] [-p] [-l] … ]
[-copyToLocal [-p] [-ignoreCrc] [-crc] … ]
[-count [-q] [-h] [-v] [-x]
[-cp [-f] [-p | -p[topax]] … ]
[-df [-h] [
[-du [-s] [-h] [-x]
[-find
[-get [-p] [-ignoreCrc] [-crc] … ]
[-getfacl [-R]
[-getfattr [-R] {-n name | -d} [-e en]
[-getmerge [-nl] ]
[-help [cmd …]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [
[-mkdir [-p]
[-moveFromLocal … ]
[-moveToLocal ]
[-mv … ]
[-put [-f] [-p] [-l] … ]
[-rm [-f] [-r|-R] [-skipTrash] …]
[-rmdir [–ignore-fail-on-non-empty]
[-test -[defsz]
[-text [-ignoreCrc] …]
[-touchz
[-usage [cmd …]]
* 常用命令
`hadoop fs -ls /`
`hadoop fs -cat /``hadoop fs -text /`
`hadoop fs -put /``hadoop fs -copyFromLocal /`
`hadoop fs -get /README.txt ./`
`hadoop fs -mkdir /hdfs-test`
`hadoop fs -mv`
`hadoop fs -rm`
`hadoop fs -rmdir`
`hadoop fs -rmr`==`hadoop fs -rm -r`
`hadoop fs -getmerge`
`hadoop fs -mkdir /hdfs-test`
### MapReduce
>
> `MapReduce`性能远低于`Spark`
> 并且只适合做离线处理不适合做实时处理和流式处理
>
>
>
#### YARN架构详解
>
> **Apache YARN** (Yet Another Resource Negotiator) 是 hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在 YARN 上,由 YARN 进行统一地管理和资源分配。
>
>
>
>
> The fundamental idea of MRv2 is to split up the two major functionalities of the JobTracker, **resource management and job scheduling** /monitoring, into separate daemons. The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job in the classical sense of Map-Reduce jobs or a DAG of jobs.
>
>
>
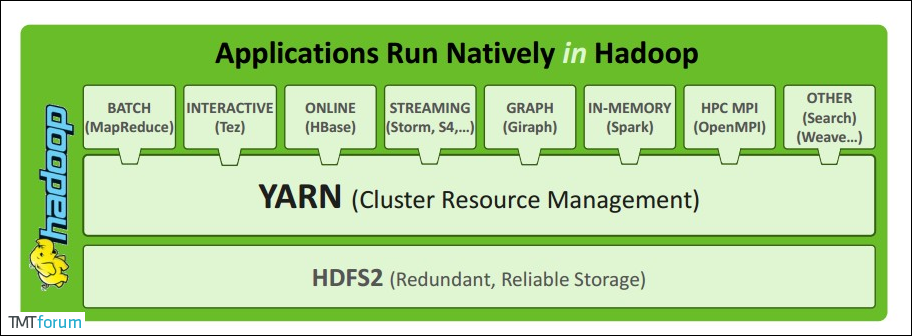
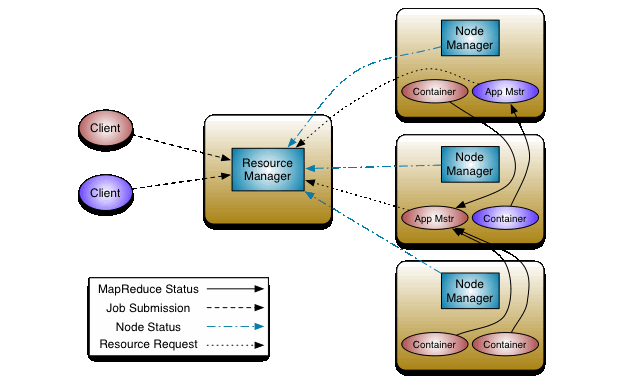
1 RM(ResourceManager) + N NM(NodeManager)
1. **Client**
* 向`RM`提交任务
* 杀死任务
2. **ResourceManager**
* `ResourceManager` 通常在独立的机器上以后台进程的形式运行,**一个集群active状态的`ResourceManager`只有一个** ,它是整个 **集群资源的主要协调者和管理者** 。
-2)启动/监控`ApplicationMaster`(一个作业对应一个AM)和监控`NodeManager`
* **负责给用户提交的所有应用程序分配资源** ,它根据应用程序优先级、队列容量、ACLs、数据位置等信息,做出决策,然后以共享的、安全的、多租户的方式制定分配策略,调度集群资源。
3. **NodeManager**
整个集群中有N个,负责单个节点的资源管理和使用以及task的运行情况
* `NodeManager` 是 YARN 集群中的每个具体 **节点的管理者** 。
* 主要 **负责该单个节点内所有容器的生命周期的管理,监视资源和跟踪节点健康** 。具体如下:
+ 定时启动时向 `ResourceManager` 注册并定时发送心跳消息,等待 `ResourceManager` 的指令;
+ 维护 `Container` 的生命周期,监控 `Container` 的资源使用情况和启停的各种命令;
+ 管理任务运行时的相关依赖,根据 `ApplicationMaster` 的需要,在启动 `Container` 之前将需要的程序及其依赖拷贝到本地。
4. **ApplicationMaster**
每个应用/作业对应一个,负责应用程序的管理
* 在用户提交一个应用程序时,YARN 会启动一个轻量级的 **进程** `ApplicationMaster`。
* `ApplicationMaster` 负责协调来自 `ResourceManager` 的资源,并通过 `NodeManager` 监视容器内资源的使用情况,同时还负责任务的监控与容错。具体如下:
+ 根据应用的运行状态来决定动态计算资源需求;
+ 向 `ResourceManager` 申请资源,为应用程序向RM申请资源(container),并分配给内部任务
+ 跟踪任务状态和进度,NM通信以启停task, task是运行在container中的
+ 负责任务的容错。
5. **Container**
* `Container` 是 YARN 中的 **资源抽象** ,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
* 当 AM 向 RM 申请资源时,RM 为 AM 返回的资源是用 `Container` 表示的。
* YARN 会为每个任务分配一个 `Container`,该任务只能使用该 `Container` 中描述的资源。`ApplicationMaster` 可在 `Container` 内运行任何类型的任务。例如,`MapReduce ApplicationMaster` 请求一个容器来启动 map **或** reduce 任务
#### YARN执行流程
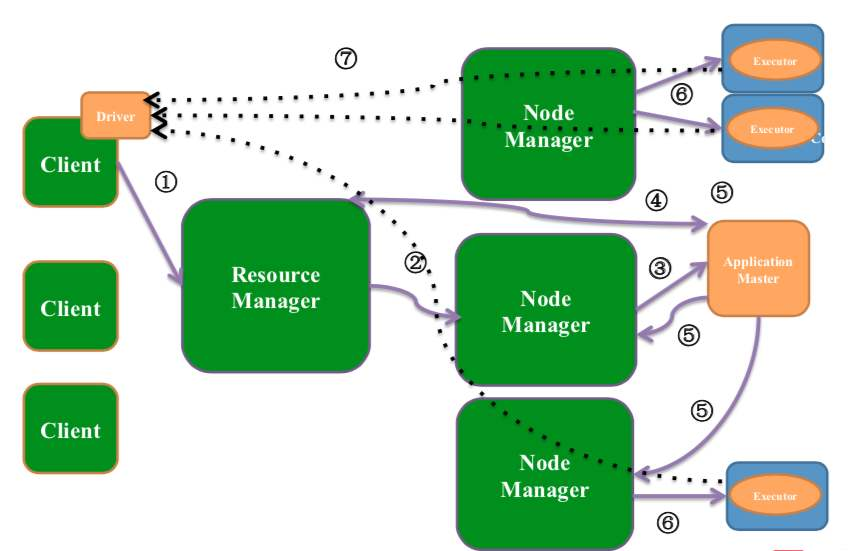
1. 客户端`client`向`yarn集群`提交作业 , 首先①向`ResourceManager`申请分配资源
2. `Resource Manager`会为作业分配一个`Container(Application manager)`,`Container`里面运行这(Application Manager)
3. `Resource Manager`会找一个对应的`NodeManager`通信②,要求`NodeManager`在这个`container`上启动应用程序`Application Master` ③
4. `Application Master`向`Resource Manager`申请资源④(采用轮询的方式通过`RPC`协议),`Resource scheduler`将资源封装发给`Application master`④,
5. `Application Master`将获取到的资源分配给各个`Node Manager`,并监控运行情况⑤
6. `Node Manage`得到任务和资源开始执行作业⑥
7. 再细分作业的话可以分为 先执行`Map Task`,结束后在执行`Reduce Task` 最后再将结果返回給`Application Master`等依次往上层递交⑦
#### YARN环境搭建
[hadoop@hadoop001 hadoop]$ pwd
/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
* mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
* yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
启动`yarn:sbin/start-yarn.sh`
验证是否启动成功
jps
ResourceManager
NodeManager
web: http://hadoop001:8088
停止`yarn: sbin/stop-yarn.sh`
提交mr作业到yarn上运行: wc
hadoop jar /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount /input/wc/hello.txt /output/wc/
[hadoop@hadoop001 sbin]$ hadoop fs -ls /output/wc
20/10/16 05:17:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Found 2 items
-rw-r–r-- 1 hadoop supergroup 0 2020-10-16 04:54 /output/wc/_SUCCESS
-rw-r–r-- 1 hadoop supergroup 26 2020-10-16 04:54 /output/wc/part-r-00000
[hadoop@hadoop001 sbin]$ hadoop fs -cat /output/wc/part-r-00000
20/10/16 05:17:52 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
hello 2
welcome 2
world 1
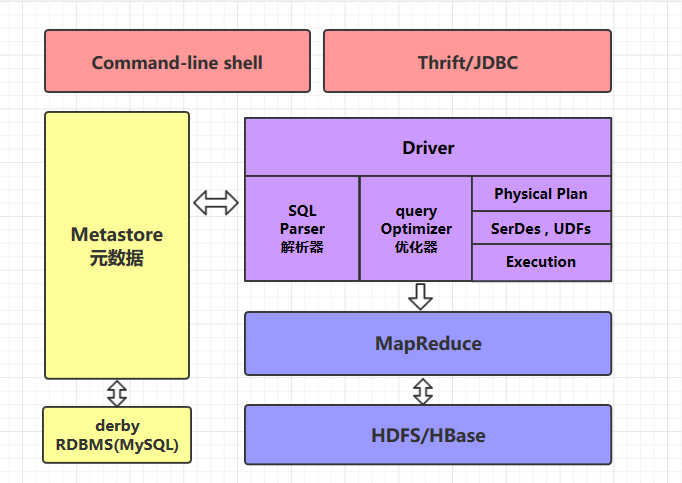
#### Hive环境搭建
| | Hive | RDBMS |
| --- | --- | --- |
| 查询语言 | Hive SQL | SQL |
| 数据储存 | HDFS | Raw Device or Local FS |
| 索引 | 无(支持比较弱) | 有 |
| 执行 | MapReduce、 Tez | Excutor |
| 执行时延 | 高,离线 | 低 , 在线 |
| 数据规模 | 非常大, 大 | 小 |
Hive底层的执行引擎有:`MapReduce、Tez、Spark`
Hive on MapReduce
Hive on Tez
Hive on Spark
1)Hive下载:http://archive.cloudera.com/cdh5/cdh/5/
`wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.7.0.tar.gz`
2)解压
`tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ~/app/`
3)配置
系统环境变量(~/.bahs\_profile)
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH
实现安装一个mysql, yum install xxx
进入/home/hadoop/app/hive-1.1.0-cdh5.14.2/conf
4)`cp hive-env.sh.template hive-env.sh`
`hive-env.sh`修改HADOOP\_HOME
5)新建hive-site.xml文件
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/sparksql?createDatabaseIfNotExist=true useUnicode=true characterEncoding=UTF-8 useSSL=false</value>#不然会报错MySQL版本的关系
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
6)拷贝mysql驱动到$HIVE\_HOME/lib/
https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.30.zip下载
scp mysql-connector-java-5.1.30-bin.jar ~/app/hive-1.1.0-cdh5.14.2/lib/
7)启动hive: `$HIVE_HOME/bin/hive`
关于Hive具体操作可以见:https://www.cnblogs.com/hiszm/p/13616589.html
#### 配置虚拟机



**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
启动hive: `$HIVE_HOME/bin/hive`
关于Hive具体操作可以见:https://www.cnblogs.com/hiszm/p/13616589.html
#### 配置虚拟机
[外链图片转存中...(img-BPM4erwx-1714776205218)]
[外链图片转存中...(img-dkuy2uYA-1714776205219)]
[外链图片转存中...(img-xvxzXRxL-1714776205219)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









