







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

大多数人没有那么多数据
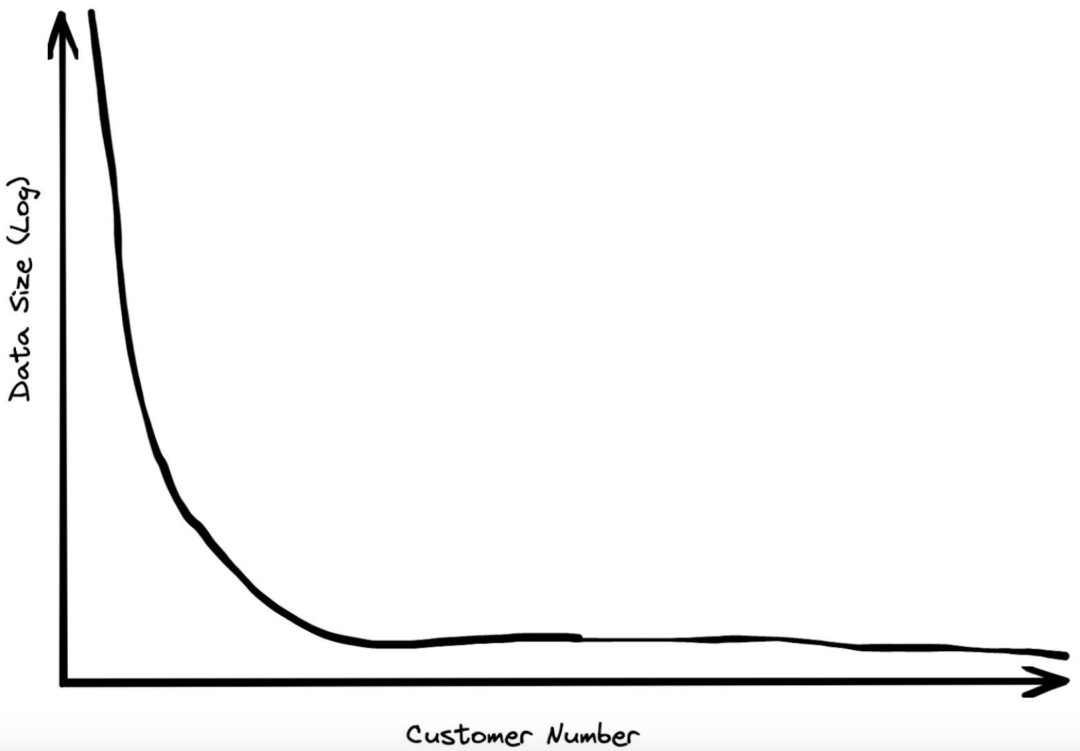
根据上述“大数据即将到来”的图表,用不了多久每个人都会数据淹没。然而十年过去了,我们“预期的未来”仍然未能成为现实。我们可以几种方式验证这一点:查看数据(定量),询问数据量是否与人们的感知一致(定性),从第一原则出发(归纳)思考这个问题。
当初在 BigQuery 工作的时候,我花了很多时间研究客户规模。相关的数据是保密的,所以我不能直接分享任何数字。但是,我可以说绝大多数客户的总数据存储量都不到 1TB。当然,也有一些客户拥有大量数据,但大多数组织,甚至一些巨头企业,他们的数据量也属于中等水平。
客户的数据规模呈幂律分布。存储量最大的客户是第二大客户的两倍,而第二大客户是第三大客户的两倍,依此类推。因此,虽然有些客户拥有数百 PB 的数据,但在分布图上这个规模的下降速度很快。成千上万的客户每月支付的数据存储费用不足 10 美元,即 0.5TB。在大量使用我们的服务的客户中,数据存储规模的中位数远低于 100 GB。
在与行业分析师(Gartner、Forrester 等)交谈的过程中,我们获得了进一步的肯定。当论及我们拥有处理海量数据集的能力时,他们会耸耸肩,然后说:“话虽如此,但绝大多数企业的数据仓库都小于 1 TB。”业内人士给我们的反馈普遍是,适合数据仓库的数量级约为 100 GB。我们的基准测试主要瞄准的也是这个尺度。
我们的一位投资者有意找出分析数据的真实规模,并调查了他自己投资的公司。其中有一些是科技公司,这些公司的数据量普遍偏大。他发现,他投资的最大的 B2B 公司拥有大约 1TB 的数据,而最大的 B2C 公司拥有大约 10TB 的数据。事实上,大多数公司的数据远没有那么多。
为了理解为什么大数据如此罕见,我们需要思考数据的实际来源。假设你拥有一家中型企业,客户规模约为 1000 名。假设每位客户每天都会下一个新订单&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1779
1779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









