







public TokenizerMapper() {
// 构造函数,没有实际操作
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 实现 Mapper 类中的 map 函数,对输入数据进行处理
StringTokenizer itr = new StringTokenizer(value.toString()); // 将输入数据转化为字符串
while(itr.hasMoreTokens()) { // 如果还有单词可以读取
this.word.set(itr.nextToken()); // 获取下一个单词
context.write(this.word, one); // 输出键值对,键为单词,值为 one
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// 定义一个 Reducer 类,继承自 Reducer<Text, IntWritable, Text, IntWritable>
private IntWritable result = new IntWritable(); // 定义一个整数类型变量 result,用于保存累加结果
public IntSumReducer() {
// 构造函数,没有实际操作
}
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 实现 Reducer 类中的 reduce 函数,对经过 Mapper 处理后的数据进行汇总
int sum = 0; // 定义一个整数变量 sum,用于保存累加结果
for(IntWritable val : values) { // 遍历键值对列表
sum += val.get(); // 累加键值对的值
}
this.result.set(sum); // 将累加的结果设置为 result 的值
context.write(key, this.result); // 输出键值对,键为单词,值为累加结果
}
}
}
3、将做好的新闻分词文件上传至hadoop平台
通过xftp将分词文本上传至Linux系统中的B20041316目录下
./bin/hdfs dfs -mkdir B20041316 #在hdfs上生成一个目录
#将文件上传至hdfs中的B20041316目录下
./bin/hdfs dfs -put ./B20041316/a1.txt B20041316
4、将java程序生成可执行jar包后运行
运行可执行jar文件进行词频统计
./bin/hadoop jar ./myapp/WordCount.jar B20041316 output
5、查看运行结果
./bin/hdfs dfs -cat output/*
**(2****)实现效果图:**

图 3-1 词频统计完成
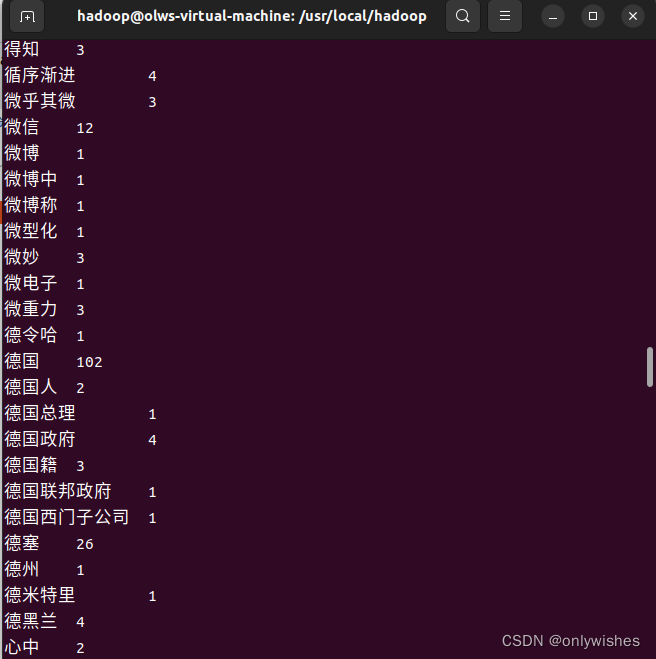
图 3-2 词频统计结果
ps:使用Python实现词频统计
with open(‘…/分词结果/a1.txt’, ‘r’, encoding=‘utf-8’) as f:
lines = f.read().split()
dic = {}
for w in lines:
dic[w] = dic.get(w, 0) + 1
ls = list(dic.items())
ls.sort(key=lambd
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









