








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
DataStreamSource<String> s1 = env.socketTextStream("123.56.100.37", 9999);
SingleOutputStreamOperator<Bean1> bean1 = s1.map(s -> {
String[] arr = s.split(",");
return new Bean1(Integer.parseInt(arr[0]), arr[1]);
});
- socket流转表
tenv.createTemporaryView("bean1",bean1);
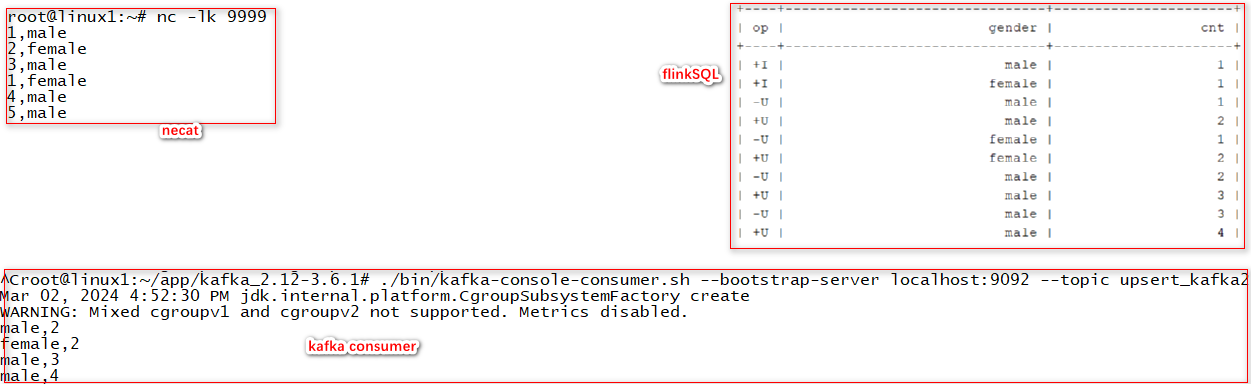
- 创建upsert-kafka表
CREATE TABLE t_upsert_kafka (
-- 这里只能NOT ENFORCED,不像MySQL中可以进行强制主键
gender STRING PRIMARY KEY NOT ENFORCED,
cnt BIGINT
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'upsert\_kafka2',
'properties.bootstrap.servers' = '123.56.100.37:9092',
'key.format' = 'csv',
'value.format' = 'csv'
);
- 写入upsert-kafka
INSERT INTO t_upsert_kafka
SELECT gender,count(1) as cnt FROM bean1 GROUP BY gender
- 执行结果
1.3、join条件下的【+I、-D、+I】
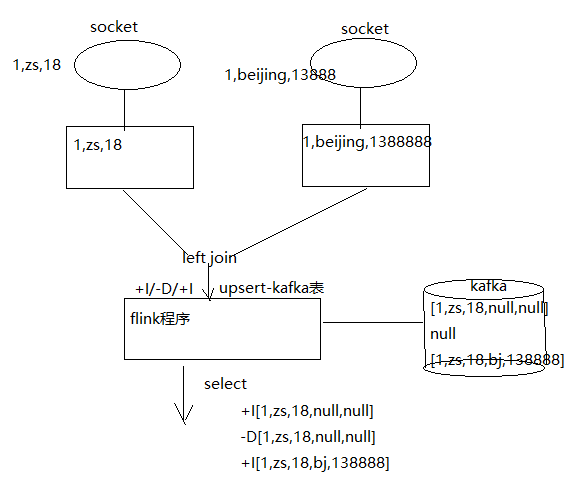
- 产生socket流
//1,zs,18
DataStreamSource<String> s1 = env.socketTextStream("123.56.100.37", 9999);
SingleOutputStreamOperator<Bean1> bean1 = s1.map(s -> {
String[] arr = s.split(",");
return new Bean1(Integer.parseInt(arr[0]),arr[1],Integer.parseInt(arr[2]));
});
//1,beijing,1388888
DataStreamSource<String> s2 = env.socketTextStream("123.56.100.37", 9998);
SingleOutputStreamOperator<Bean2> bean2 = s2.map(s -> {
String[] arr = s.split(",");
return new Bean2(Integer.parseInt(arr[0]),arr[1],Integer.parseInt(arr[2]));
});
- socket流转表
tenv.createTemporaryView("bean1",bean1);
tenv.createTemporaryView("bean2",bean2);
- 执行建表语句
CREATE TABLE t_upsert_kafka_join3 (
id INT PRIMARY KEY NOT ENFORCED,
name STRING,
age INT,
addr STRING,
phone BIGINT
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'upsert\_kafka2\_join',
'properties.bootstrap.servers' = '123.56.100.37:9092',
'key.format' = 'csv',
'value.format' = 'json'
)
- 执行join语句插入
INSERT INTO t_upsert_kafka_join3
SELECT A1.id,A1.name,A1.age,A2.addr,A2.phone
FROM bean1 AS A1
LEFT JOIN bean2 AS A2
ON A1.id = A2.id
- 查看结果
tenv.executeSql("SELECT \* FROM t\_upsert\_kafka\_join3").print();

2、Jdbc连接器
JDBC 连接器允许使用 JDBC 驱动向任意类型的关系型数据库读取或者写入数据。如果在 DDL 中定义了主键,JDBC sink 将以 upsert 模式与外部系统交换 UPDATE/DELETE 消息;否则,它将以 append 模式与外部系统交换消息且不支持消费 UPDATE/DELETE 消息。Jdbc作为source的时候,支持scan模式和lookup模式,look模式的意思参考lookup join。
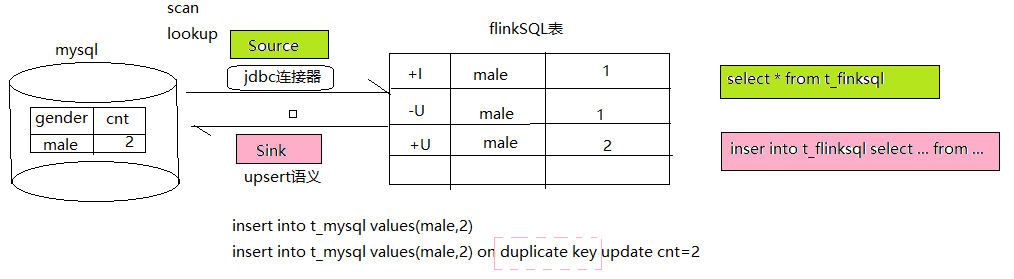
2.1、Scan Source
CREATE TABLE flink_users (
id int primary key,
name string,
age int,
gender string
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://123.56.100.37:3306/flinktest?useSSL=false',
'table-name' = 'users',
'username' = 'root',
'password' = '123456'
)
相当于有界流,只scan一次

2.2、Sink: Streaming Append & Upsert Mode
INSERT INTO flink_users
SELECT A1.id,A1.name,A1.age,A2.gender
FROM bean1 AS A1
LEFT JOIN bean2 AS A2
ON A1.id = A2.id
查询结果,select的之后只scan一次

3、CDC连接器
适用于 Apache Flink 的 CDC 连接器是一组适用于 Apache Flink 的源连接器,使用更改数据捕获 (CDC) 从不同的数据库引入更改。 适用于 Apache Flink 的 CDC 连接器集成了 Debezium 作为捕获数据更改的引擎。所以它可以充分利用Debezium的能力。
github地址:https://github.com/ververica/flink-cdc-connectors?tab=readme-ov-file
3.1、Flink-CDC源码编译
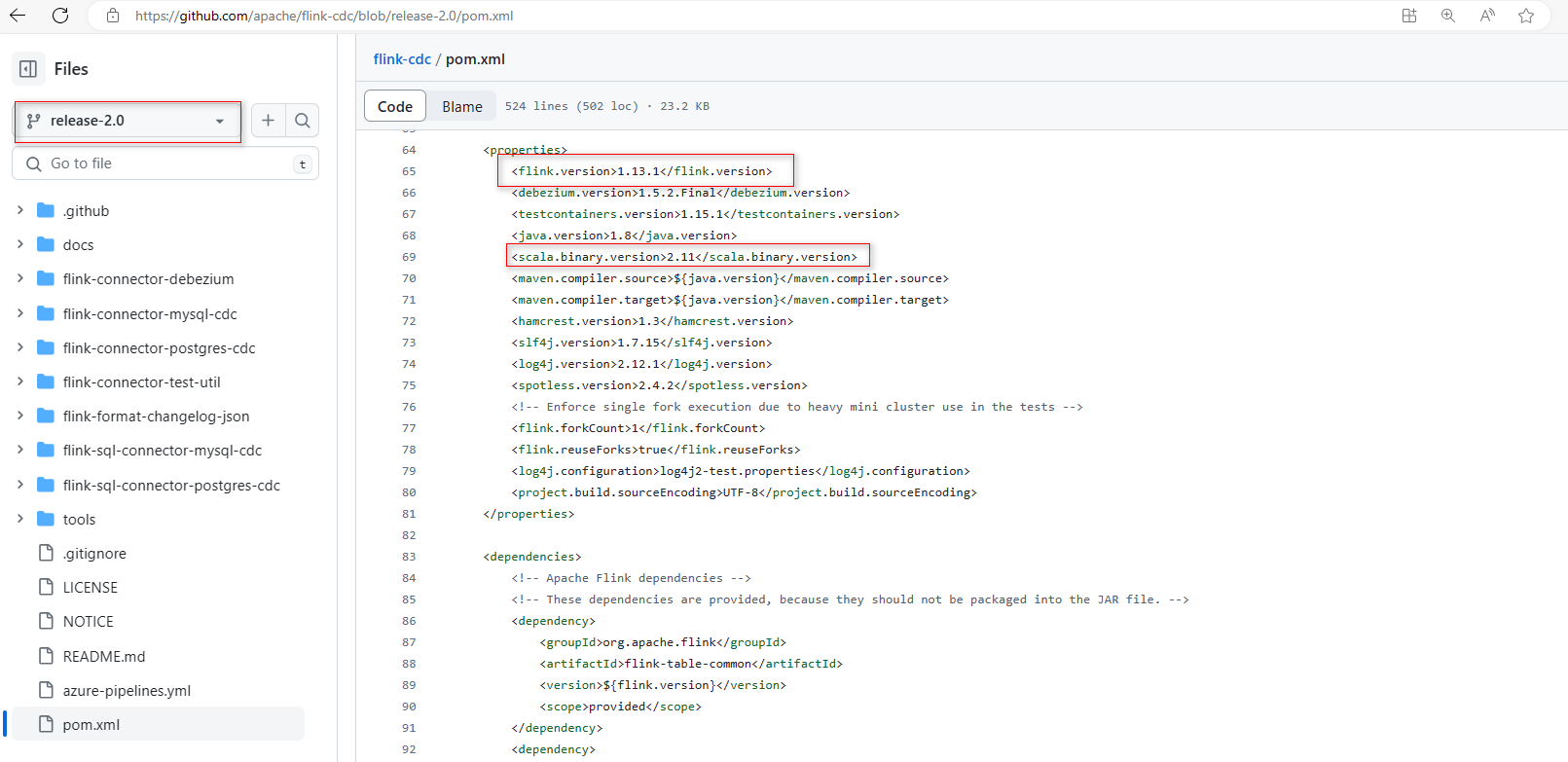
- 下载源码
https://github.com/apache/flink-cdc/blob/release-2.0/pom.xml
选择合适的版本、文章中用的事1.14.4,这里选择1.13.1版本
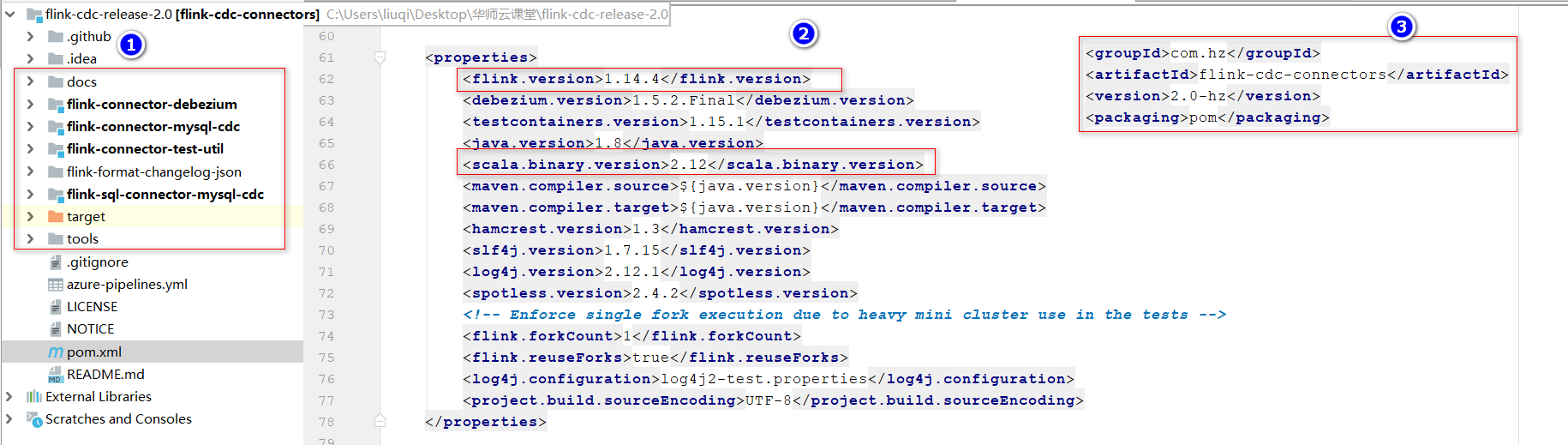
- 在idea中,通过project from version control导入maven项目,源码修改如下:
①:删除包括测试等不用的项目,避免编译多余的项目
②:修改flink版本和Scala版本,为了匹配我们现在使用的flink版本
③:修改项目的groupId和version,定义新的flink版本
这一步其实就是相当于修改源码,实际编程过程中,遇到很多细节性的错误,这里不做列举
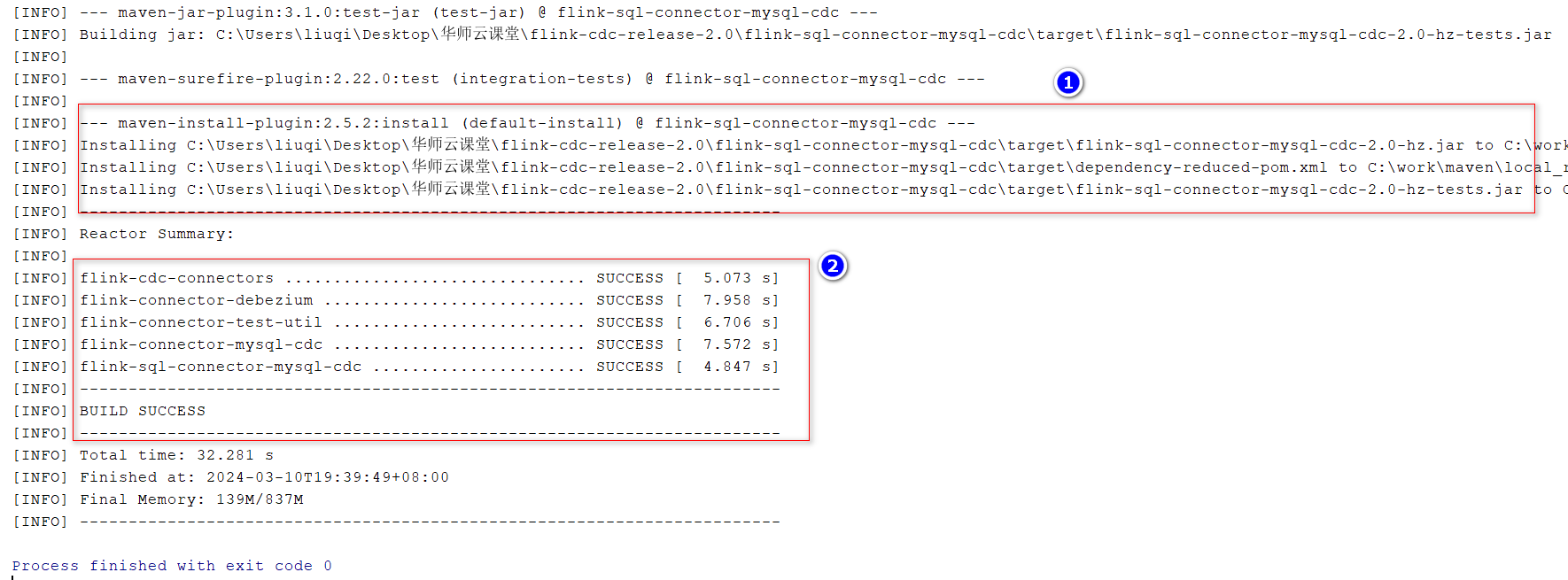
- 编译源码,打包
这里直接在idea中选择install,从而可以成功的安装到本地
3.2 、mysql开启binlog
- 修改配置文件/etc/mysql/my.cnf
github参考连接:https://github.com/apache/flink-cdc/blob/master/docs/content/docs/connectors/cdc-connectors/mysql-cdc.md
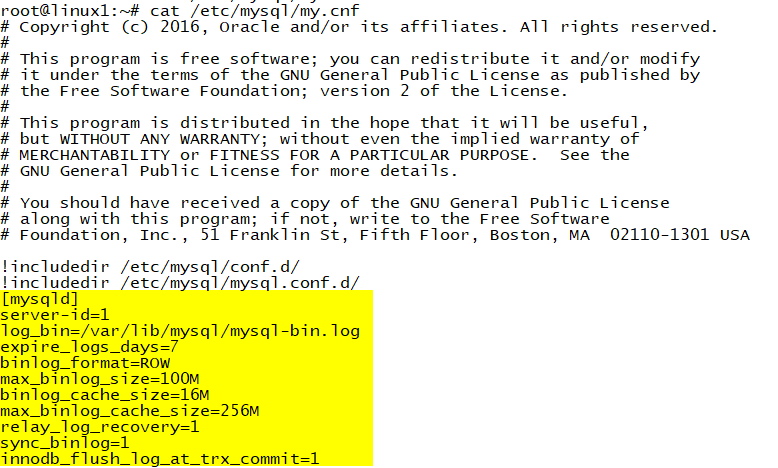
[mysqld]:https://stackoverflow.com/questions/44298071/how-to-fix-mysql-error-found-option-without-preceding-group-in-config-file - 查看binlog是否开启


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
3)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









