







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

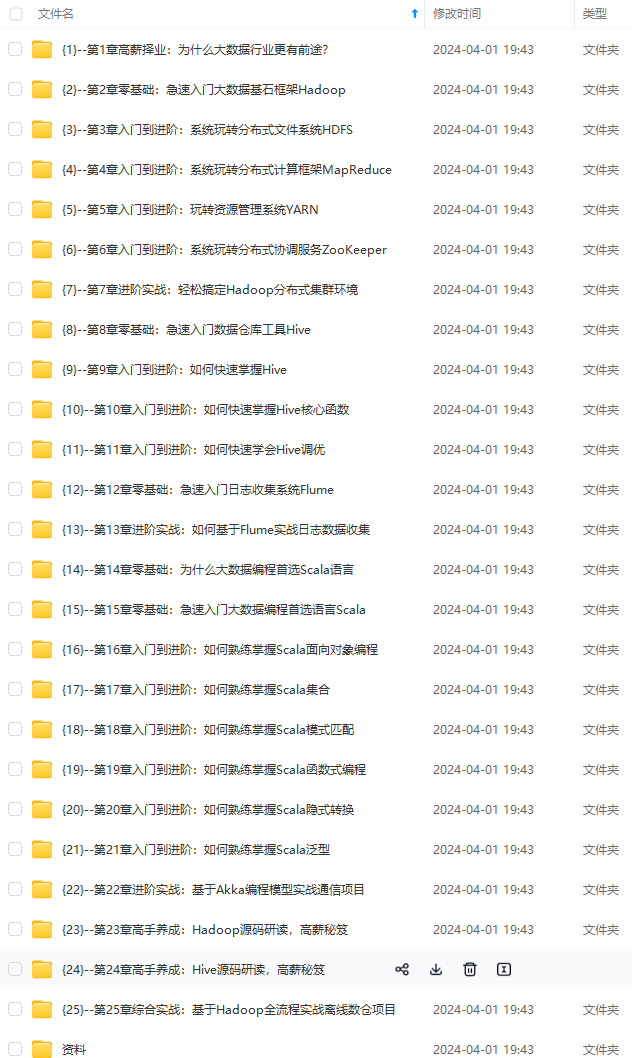
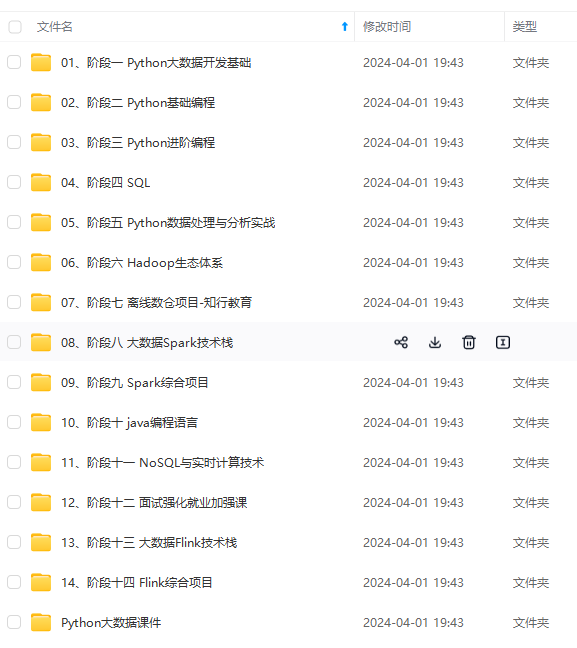
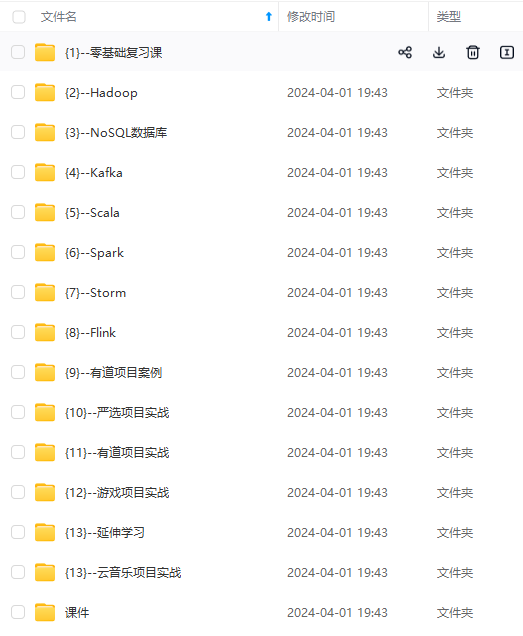
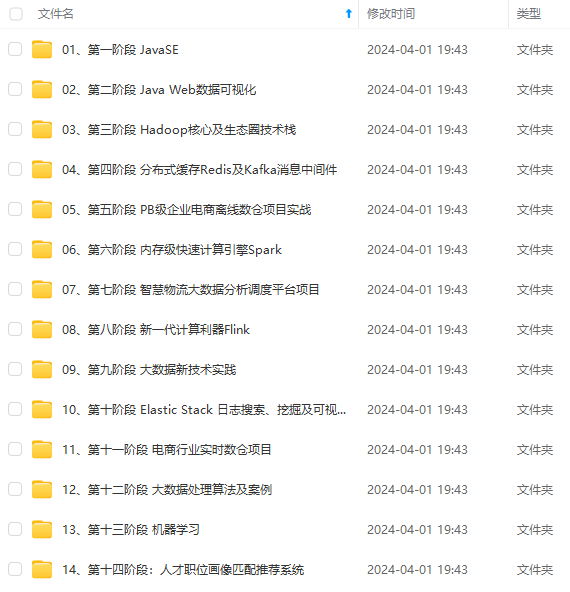
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
容错性
良好的容错性,即使节点出现问题 SQL 仍能够正常完成
Hive缺点
- Hive 的 HQL 表达能力有限,迭代式算法无法表达,比如 pagerank 。数据挖掘方面,比如 k-means 。
- Hive 的效率比较低,Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
- Hive 调优比较困难,粒度较粗
- Hive 可控性差
Hive体系架构
Hive架构图
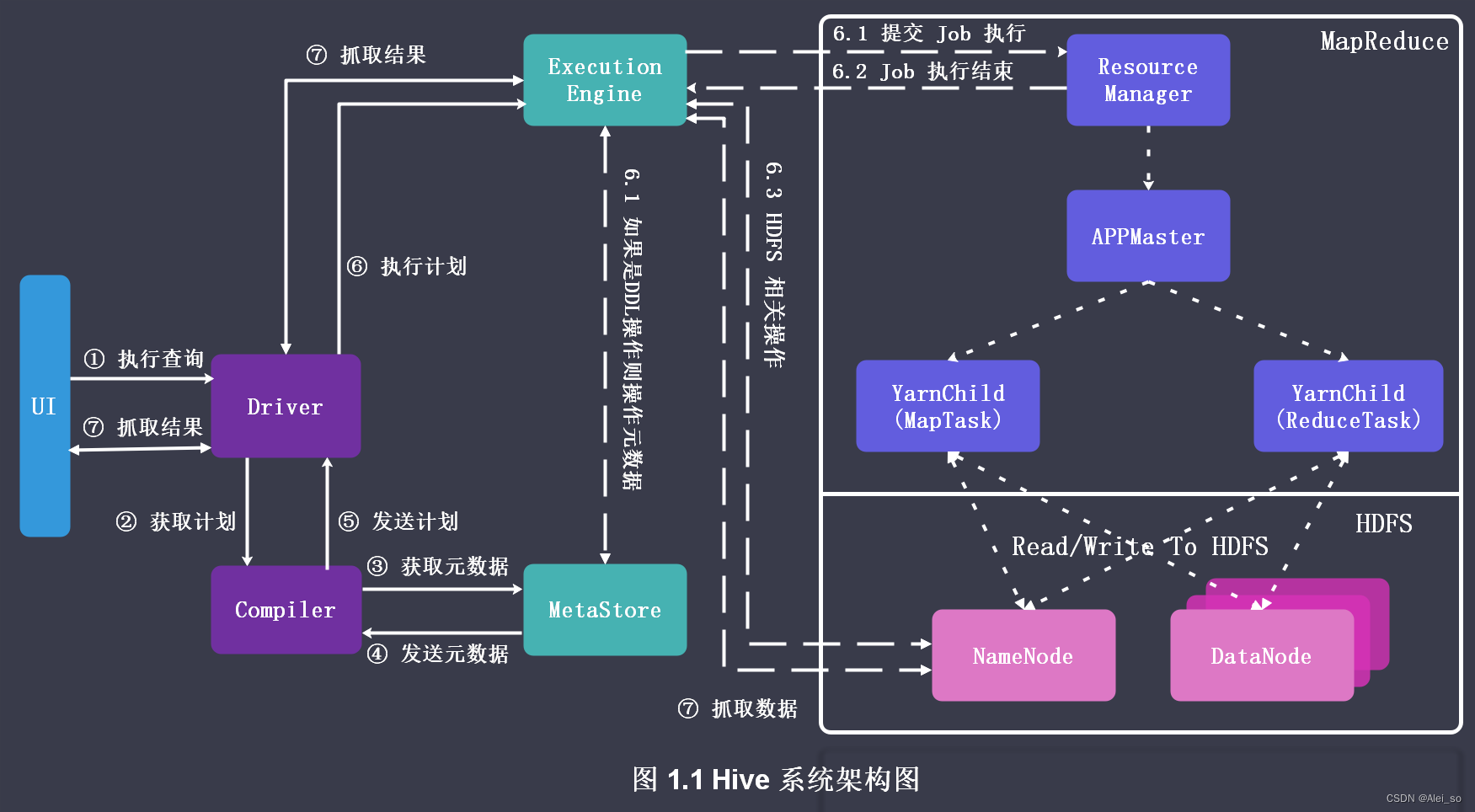
Hive架构基本组成
Hive 的体系结构主要分为以下几个部分:
用户接口
用户接口主要有 3 个:CLI,Client 和 WEBUI。其中最常用的就是 CLI,CLI启动时会启动一个 Hive 副本【其实就是一个 Shell 客户端】;Client 是 Hive 的客户端,用户通过其连接至 HiveServer2,在启动 Client 模式的时候,需要指出 HiveServer2 所在节点和端口,并且在该节点启动 HiveServer2;WEBUI 就是通过浏览器访问 Hive,可以使用 Hue 组件在浏览器上写 HQL 执行相关操作。
MetaStore
Hive 将元数据存储在关系型数据库中,比如 MySQL、Derby等。Hive 中的元数据包括表的名字、表的列和分区及其属性,表的属性(是否为外部表等)、表的数据所在目录等等
ThriftServer
ThriftServer 是将 Hive 作为一个服务器,其他机器可以作为客户端进行访问,可以使用多种编程语言【Java、Python 】通过代码操作 Hive。
Driver
- SQL Parser
- Hive 的解析器是将查询字符串转换成抽象语法树 —— AST,对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误
- Physical Plan
将 AST 编译生成逻辑执行计划- SQL Optimizer
对逻辑执行计划进行优化- Execution
把逻辑执行计划转换成可以运行的物理计划任务树。对于 Hive 来说,就是 MR/Spark
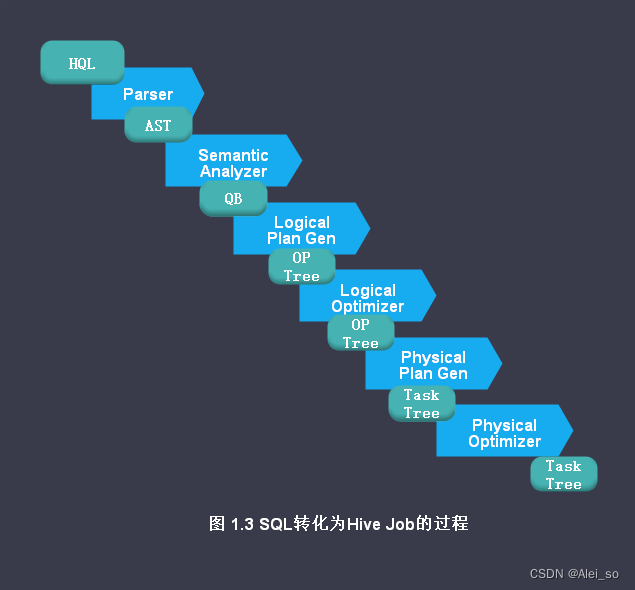
1.完成 SQL 词法,语法解析,将 SQL 转化为抽象语法树 AST Tree
2.遍历 AST Tree,抽象出查询的基本组成单元 Query Block
3.遍历 Query Block,翻译为执行操作树 OperatorTree,即逻辑执行计划
4.逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 Shuffle 数据量
5.遍历 OperatorTree,翻译为 Hive job 任务,即物理计划
6.物理层优化器进行 Hive job 任务的变换,生成最终的执行计划
数据库和数据仓库
OLTP : 联机事务处理就是保存我们日常生活中的各种用户行为产生的记录的数据平台.
- 特点: 服务于业务,需要少量数据的频繁增删改查,要保证响应速度,保证数据安全,保证时效性.
OLAP : 联机分析处理,就是我们数据分析时所使用的海量数据存放的数据平台,一般会将多个业务数据库或各种数据源中的数据提取出来,统一存放在OLAP服务中.
- 特点: 服务于分析,要能应对海量的数据存储和数据计算,对于响应速度要求不高,我们很少修改数据,所以也不需要对于数据的一致性,安全性等进行考虑.
数据库和数据仓库的区别
- 本质的区别就是OLTP 和OLAP系统的区别
- 数据库更偏重于事务处理,要求其支持事务,增删改查效率较高
- 事务: 最小业务单元, 在执行过程中,要么全部 成功,要么全部失败
- 举例: 小椭圆给小绿转账1000元 , 银行系统需要给小椭圆减少1000元, 给小绿增加一千元 要么同时成功,要么同时失败
- 落实到代码层面就是多条sql语句,要么全部成功,要么全部失败.
- 事务: 最小业务单元, 在执行过程中,要么全部 成功,要么全部失败
- 数据仓库偏重于数据吞吐量和稳定,不要求支持事务,不要求较高的响应效率,但必须可以处理海量数据或文件
- 数据仓库不是大型的数据库,也没有要取代数据库的目标,只是一个数据分析的平台。
- 数据库更偏重于事务处理,要求其支持事务,增删改查效率较高
数据仓库核心特征
面向主题性(Subject-Oriented)
主题(subject)是一个抽象的概念 数据综合体。一个分析的主题可以对应多个数据源。
在数仓中开展分析,首先确定分析的主题,然后基于主题寻找、采集跟主题相关的数据。
在数据分析中,要做到宁滥勿缺.
集成性(Integrated)
数仓不是生成数据的平台 其数据来自于各个不同的数据源
当我们确定主题之后 就需要把和主题相关的数据从各个数据源集成过来。
因为同一个主题的数据可能来自不同的数据源 它们之间会存在着差异(异构数据):字段同名不统一、单位不统一、编码不统一;
因此在集成的过程中需要进行ETL(Extract抽取 Transform转换 load加载)
不可更新性(Non-Volatile)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**
[外链图片转存中…(img-KmnBihrv-1713297980872)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









