







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
systemctl enable docker
systemctl start docker
systemctl status docker
### 三、创建hadoop容器
#### 宿主机环境准备
#### 拉取镜像
`docker pull centos:7`
#### 进入存放安装包目录
`cd /mnt/docker_share`
#### 上传jdk和hadoop
* 前提:安装上传软件工具(yum install lrzsz)
`rz jdk*.tar.gz;rz hadoop*.tar.gz`
#### 解压软件包
* 解压到opt目录,后续我们将映射该目录下的软件包到docker容器
tar -xvzf jdk-8u141-linux-x64.tar.gz -C /opt
tar -xvzf hadoop-2.7.0.tar.gz -C /opt
#### 创建用于保存数据的文件夹
mkdir -p /data/dfs/nn
mkdir -p /data/dfs/dn
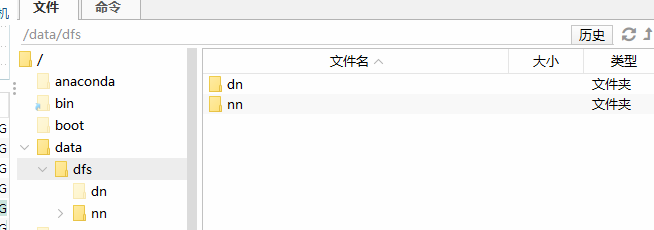
#### 容器环境准备
#### 启动hadoop容器
* 注意一定要添加 --privileged=true,否则无法使用系统服务
docker run
–net docker-bd0 --ip 172.33.0.121
-p 50070:50070 -p 8088:8088 -p 19888:19888
-v /mnt/docker_share:/mnt/docker_share
-v /etc/hosts:/etc/hosts
-v /opt/hadoop-2.7.0:/opt/hadoop-2.7.0
-v /opt/jdk1.8.0_141:/opt/jdk1.8.0_141
-v /data/dfs:/data/dfs
–privileged=true
-d -it --name hadoop centos:7
/usr/sbin/init
>
> 注意:确保在主机上禁用SELinux
>
>
>
#### 进入hadoop容器
docker exec -it hadoop bash

#### 安装vim
* 为了后续方便编辑配置文件,安装一个vim
`yum install -y vim`
#### 安装ssh
* 因为启动Hadoop集群需要进行免密登录,Centos7容器需要安装ssh
yum install -y openssl openssh-server
yum install -y openssh-client*
* 修改ssh配置文件
vim /etc/ssh/sshd_config
在文件最后添加
PermitRootLogin yes
RSAAuthentication yes
PubkeyAuthentication yes
* 启动ssh服务
systemctl start sshd.service
设置开机自动启动ssh服务
systemctl enable sshd.service
查看服务状态
systemctl status sshd.service
#### 配置免密登录
#### 生成秘钥
`ssh-keygen`
#### 设置密码
* 设置root用户的密码为123456
`passwd`
#### 拷贝公钥
`ssh-copy-id hadoop.bigdata.cn`
#### 测试免密登录
ssh hadoop.bigdata.cn
#### 配置JDK
vim /etc/profile
配置jdk的环境变量
export JAVA_HOME=/opt/jdk1.8.0_141
export CLASSPATH=
J
A
V
A
_
H
O
M
E
/
l
i
b
e
x
p
o
r
t
P
A
T
H
=
{JAVA\_HOME}/lib export PATH=
JAVA_HOME/libexportPATH={JAVA_HOME}/bin:$PATH
让上一步配置生效
source /etc/profile

#### 配置Hadoop
* core-site.xml
* hdfs-site.xml
* yarn-site.xml
* mapred-site.xml
* hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8.0_141
* slaves
hadoop.bigdata.cn
* 配置环境变量
+ vim /etc/profile
+ source /etc/profile
export HADOOP_HOME=/opt/hadoop-2.7.0
export PATH=
H
A
D
O
O
P
_
H
O
M
E
/
s
b
i
n
:
{HADOOP\_HOME}/sbin:
HADOOP_HOME/sbin:{HADOOP_HOME}/bin:$PATH
### 四、初始化并启动Hadoop
#### 格式化hdfs
`hdfs namenode -format`
#### 启动hadoop
start-all.sh
启动history server
mr-jobhistory-daemon.sh start historyserver
#### 测试hadoop
cd $HADOOP_HOME
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar pi 2 1
#### image-20230918194247221
#### 查看进程
bash-4.1# jps
561 ResourceManager
659 NodeManager
2019 Jps
1559 NameNode
1752 SecondaryNameNode
249 DataNode

### 五、配置开启容器启动Hadoop
#### 创建启动脚本
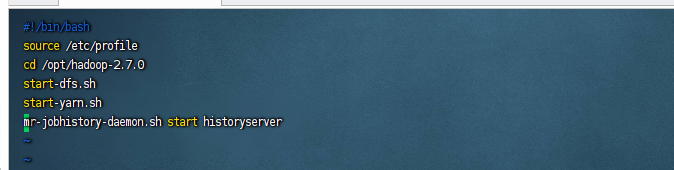
* 创建新文件存放启动脚本
touch /etc/bootstrap.sh
chmod a+x /etc/bootstrap.sh
vim /etc/bootstrap.sh
* 文件内容
#!/bin/bash
source /etc/profile
cd /opt/hadoop-2.7.0
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
#### 加入自动启动服务
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
mr-jobhistory-daemon.sh start historyserver

加入自动启动服务
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-9u4mfR66-1713382429872)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









