







• batch.size:批次大小,默认16k
• linger.ms:等待时间,修改为5-100ms
默认是0ms,就是数据一到队列中就发给broker,这样的好处就是实时性好,但是效率低,一次发几条数据总比一次发一条效率高。也不能改太大,太大时效性不好。
• compression.type:压缩snappy
压缩数据,这样一批次就可以存更多的数据
• RecordAccumulator:缓冲区大小,可修改为64m
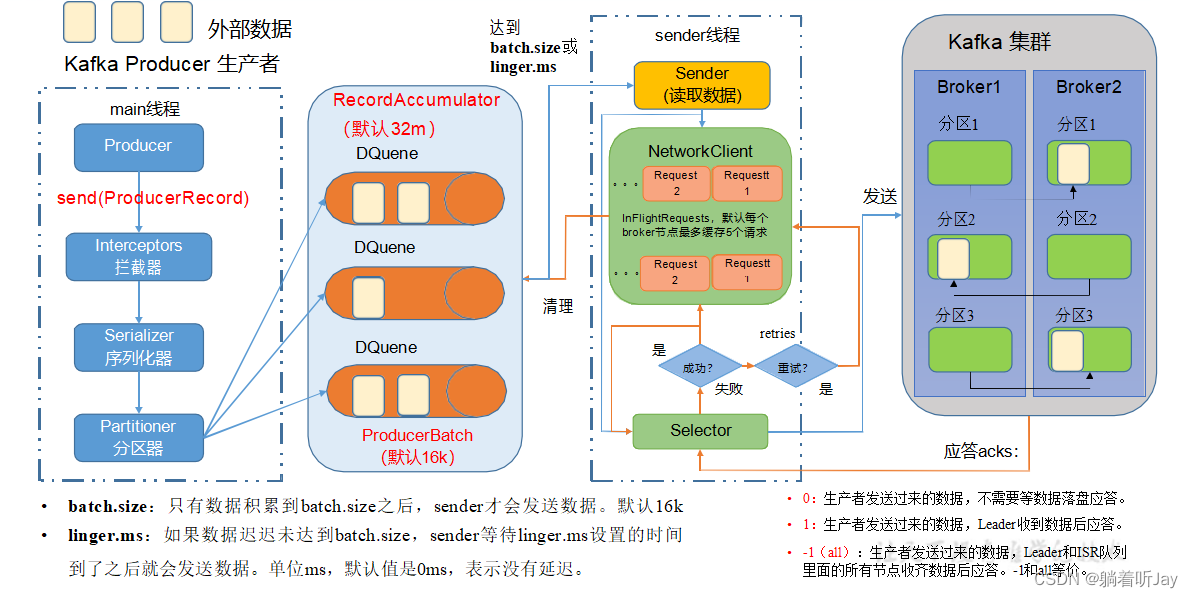
##### 生产者数据可靠性
主要是当broker收到数据后的应答机制
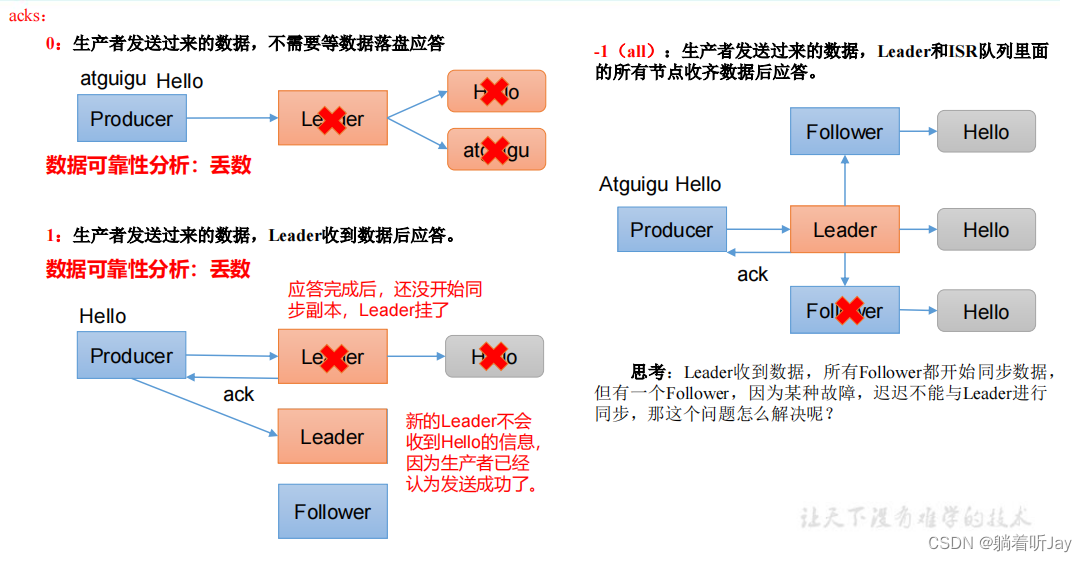
ISR队列是只一个分区的Leader和所有的Followers的集合,ISR(0,1,2),为了解决那个问题,如果Leader长时间没收到某个Follower同步数据的请求,就会认为这个Follower故障了,就会从ISR队列中踢出这个Follower,ISR(0,1)。
如果Follower长时间未向Leader发送通信请求或同步数据,则 该Follower将被踢出ISR。该时间阈值由**replica.lag.time.max.ms**参 数设定,默认30s。例如2超时,(leader:0, isr:0,1)。
数据完全可靠条件 = ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
数据可靠性越强,效率越慢

// 设置 acks
properties.put(ProducerConfig.ACKS_CONFIG, “all”);
// 重试次数 retries,默认是 int 最大值,2147483647
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
#### 消费者

消费者消费一个分区中的数据时,会跟踪他们自己消费到的偏移量,Kafka 会定期将偏移量提交到 Kafka 主题中的特殊主题(\_\_consumer\_offsets)中,这样,消费者如果停止或重新启动后,会从上次的偏移量继续消费。偏移量是每条消息在分区中的位置。
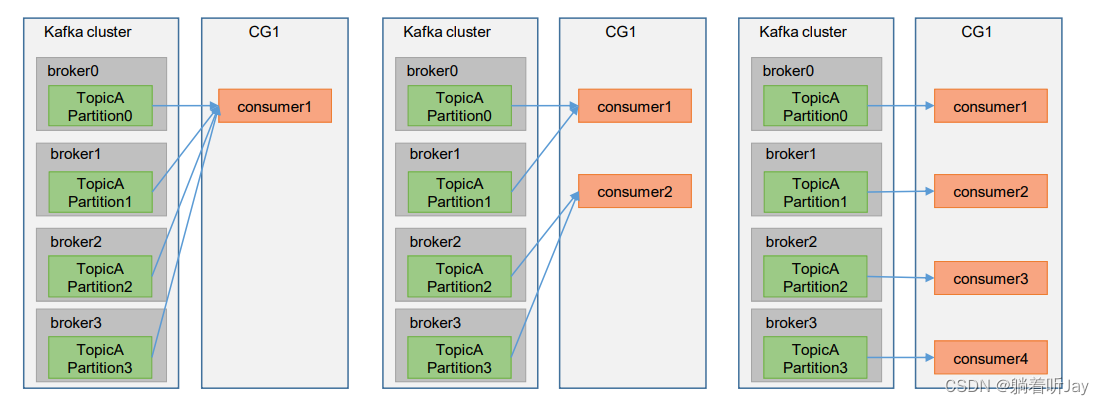
##### 消费者组
由多个kafka消费者组成的一组消费者组,用于同时消费处理kafka中一个主题所有分区中的数据。只要在创建kafka消费者的时候将group id设置成一样的,那么就可以创建多个消费者构成消费者组了。
一个主题的一个分区只能由一个消费者组内的一个消费者处理,否则会导致数据重复消费。一个消费者组的每个消费者负责消费不同分区的数据。
消费者组的好处:加快消费处理数据的速度,横向提高整个消费能力。如下图,一开始就一个消费者c1,他要自己一个人消费处理来自topicA主题的四个分区的数据,而我们可以增加三个消费者c2、c3、c4和c1构成一个消费者组来同时消费处理topicA主题的四个分区的数据,这样消费处理数据的速度就提升了。(**前提是有多个分区**)
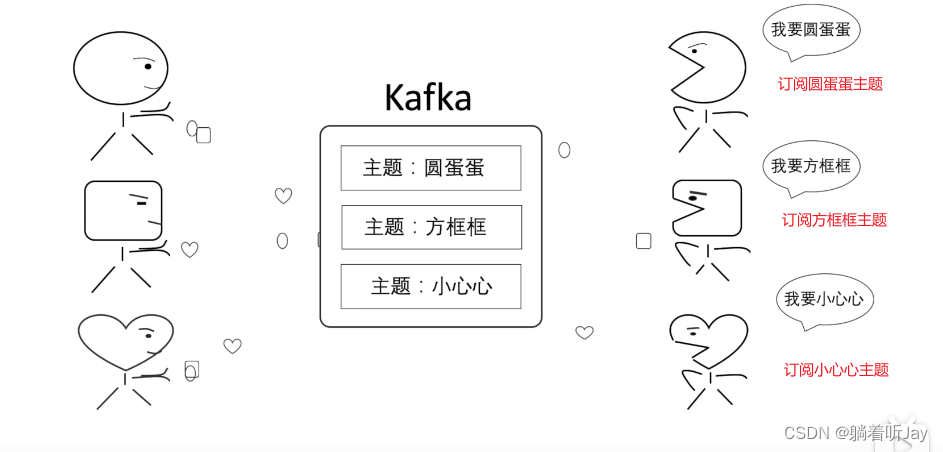
### 主题
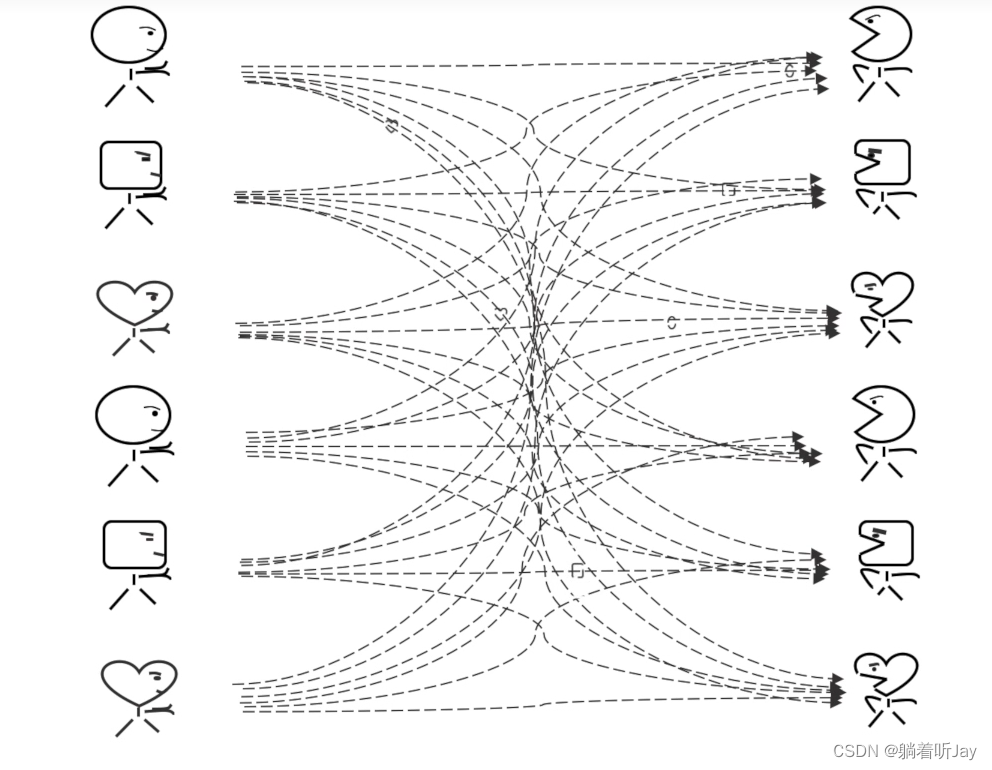
上面那样肯定不好,各种消息的的生产者(生产圆蛋蛋、生产方框框、生产小心心)将消息都发给kafka,然后kafka将消息都分类,每种分类都有相应的主题,然后消费者根据需要订阅相应的主题。就能收到对应的消息。
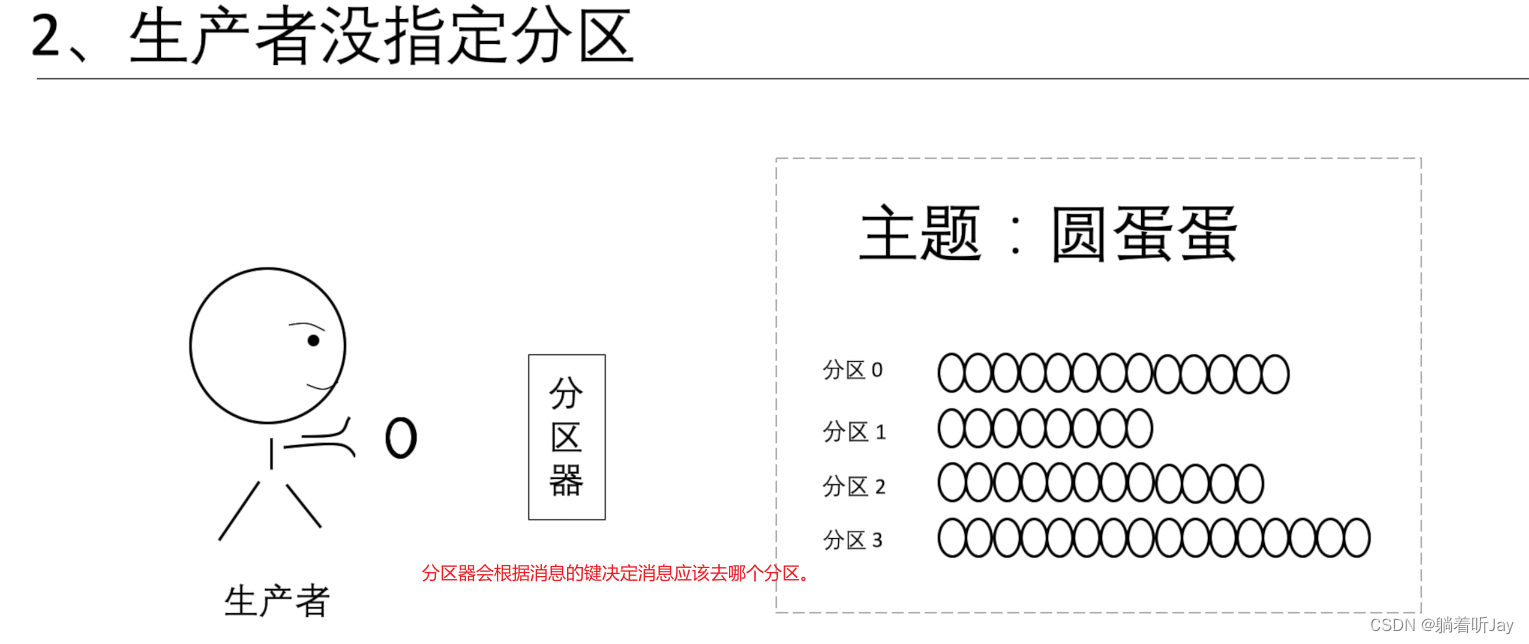
### **分区**
如果一个主题的消息比较多,就可以考虑分区,分区可以分布在不同的服务器上,所以主题也可以分布在不同的服务器上,这样比单服务器处理快。

如果生成者没有指定分区,分区器就会根据每条消息的键算出消息该去哪个分区。键:就是每条消息的一个标记,决定了消息该去哪个分区。分区器:就是一个算法,算消息该去哪个分区,输入是键,输出是消息去的分区。
### **偏移量**
偏移量就是消息在每个分区中的位置,kafka在收到消息的时候,会为每个消息设置偏移量,然后将消息存到磁盘中。
消费者只能按顺序消费读取。消费者如果要分区0的第四个,kafka就会说第三个还没读取,不给第四个。
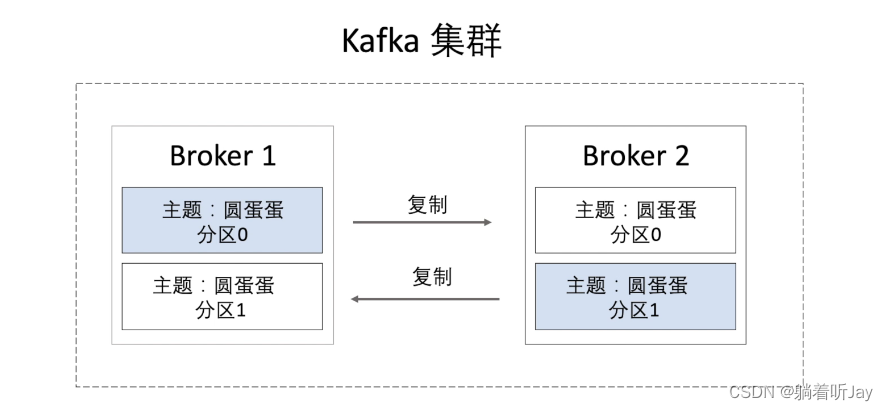
### **kafka集群**
一个broker就是一个kafka服务器。下面有两个broker构成了kafka集群,他们的数据通过复制同步,当有一个kafka宕机了,另一台就可以先顶上,保证了kafka的可靠性。
### 监控kafka
这个前提得先安装jdk
1、修改kafka的启动脚本
vim bin/kafka-server-start.sh
if [ “x$KAFKA_HEAP_OPTS” = “x” ]; then
export KAFKA_HEAP_OPTS=“-Xmx1G -Xms1G”
fi
改为
if [ “x$KAFKA_HEAP_OPTS” = “x” ]; then
export KAFKA_HEAP_OPTS=“-server -Xms2G -Xmx2G
-XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200
-XX:ParallelGCThreads=8 -XX:ConcGCThreads=5
-XX:InitiatingHeapOccupancyPercent=70”
export JMX_PORT=“9999”
#export KAFKA_HEAP_OPTS=“-Xmx1G -Xms1G”
fi
修改kafka进程信息:
-Xms2G:设置 Kafka 进程的初始堆内存大小为 2 GB。
-Xmx2G:设置 Kafka 进程的最大堆内存大小为 2 GB。
XX:PermSize=128m:设置持久代(PermGen)的初始大小为 128 MB。请注意,这个选项在 Java 8 和更新的版本中不再适用,因为 PermGen 已被 Metaspace 取代。
-XX:+UseG1GC:指定使用 G1 垃圾收集器。
-XX:MaxGCPauseMillis=200:设置最大垃圾收集暂停时间为 200 毫秒。
XX:ParallelGCThreads=8:设置并行垃圾收集线程的数量为 8。
XX:ConcGCThreads=5:设置并发垃圾收集线程的数量为 5。
XX:InitiatingHeapOccupancyPercent=70:设置堆内存占用百分比,当堆内存使用达到 70% 时,启动并发垃圾收集。
这些参数的目的是调整 Kafka 进程的性能和垃圾收集行为,以满足特定的性能需求。请注意,这些参数的值可以根据你的 Kafka 部署和硬件资源进行调整。堆内存的大小和垃圾收集器的选择将影响 Kafka 的性能和稳定性。
最后,这段脚本还设置了 JMX 端口为 9999,这是用于监控 Kafka 进程的 Java Management Extensions(JMX)端口。通过此端口,你可以使用 JMX 工具监控 Kafka 进程的性能指标和状态。如果需要监控 Kafka,你可以使用 JMX 工具连接到此端口。
2、官网下载安装包
https://www.kafka-eagle.org/
3、上传解压
第一次解压后,里面有个压缩包再解压才是真正的。
/opt/module/efak/conf/system-config.properties
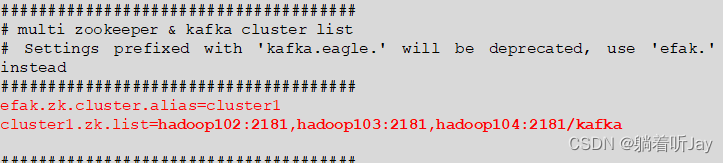

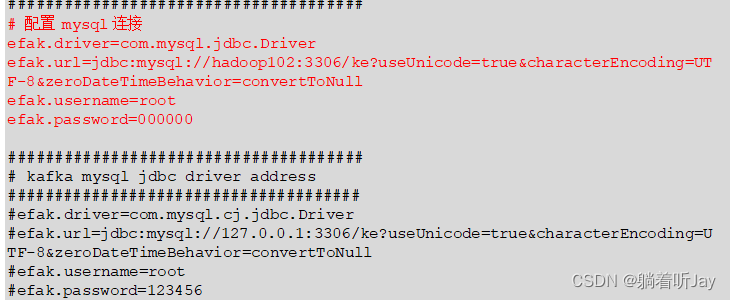
5、配置环境变量
$ sudo vim /etc/profile.d/my_env.sh
kafkaEFAK
export KE_HOME=/opt/module/efak
export PATH=
P
A
T
H
:
PATH:
PATH:KE_HOME/bin
source /etc/profile
6、启动
/bin/kf.sh start
### 压力测试
单Kafka服务器,生成者发送1000000条数据,每条大小1k,总共发送大约
bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=linjl:9092 batch.size=16384 linger.ms=0
batch.size=16384 linger.ms=0 9.76 MB/sec
record-size 是一条信息有多大,单位是字节,本次测试设置为 1k。
### BUG
1、Error while fetching metadata with correlation id : {LEADER\_NOT\_AVAILABLE}
2、
[root@linjl kafka_2.12-3.0.0]# ./bin/kafka-console-consumer.sh --topic quickstart-events --bootstrap-server linjl:9092
[2023-09-13 16:51:54,710] WARN [Consumer clientId=consumer-console-consumer-32025-1, groupId=console-consumer-32025] Error while fetching metadata with correlation id 2 : {quickstart-events=LEADER_NOT_AVAILABLE} (org.apache.kafka.clients.NetworkClient)
这个警告消息 “Error while fetching metadata with correlation id 2 : {quickstart-events=LEADER\_NOT\_AVAILABLE}” 表示 Kafka 消费者在尝试订阅主题 “quickstart-events” 时遇到了 “LEADER\_NOT\_AVAILABLE” 错误。这个错误通常表示消费者无法找到主题的 leader 分区,因此它无法读取消息。
我的猜想: 可能是因为 Kafka 服务器无法从 ZooKeeper 获取到有关 “quickstart-events” 主题的元数据信息,包括分区的 Leader 信息。
3、Received invalid metadata error in produce request on partition quickstart-events-0
due to org.apache.kafka.common.errors.KafkaStorageException: Disk error when trying to access log file on the disk… Going to request metadata update now (org.apache.kafka.clients.producer.internals.Sender)
表示在尝试将消息写入分区 “quickstart-events-0” 时,Kafka 生产者遇到了磁盘错误,无法访问日志文件。这个错误通常与磁盘故障或磁盘空间不足有关。
4、Java客户端创建生产者,发送消息给kafka没响应。
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.239.128:9092");
// key,value 序列化(必须):key.serializer,value.serializer
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName())
网络连接都能通,而且防火墙也都关了。
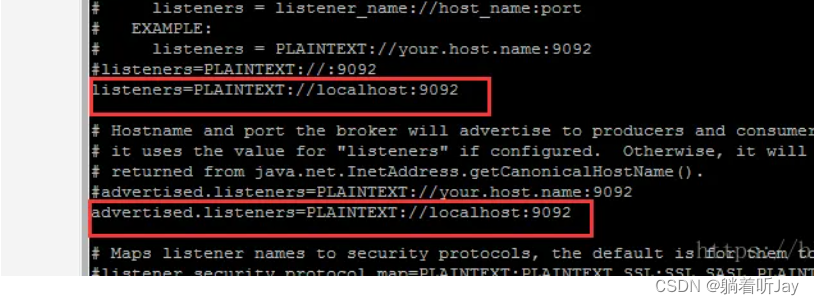
解决:在server.properties配置文件中配置
The address the socket server listens on. If not configured, the host name will be equal to the value of
java.net.InetAddress.getCanonicalHostName(), with PLAINTEXT listener name, and port 9092.
FORMAT:
listeners = listener_name://host_name:port
EXAMPLE:
listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://192.168.239.128:9092
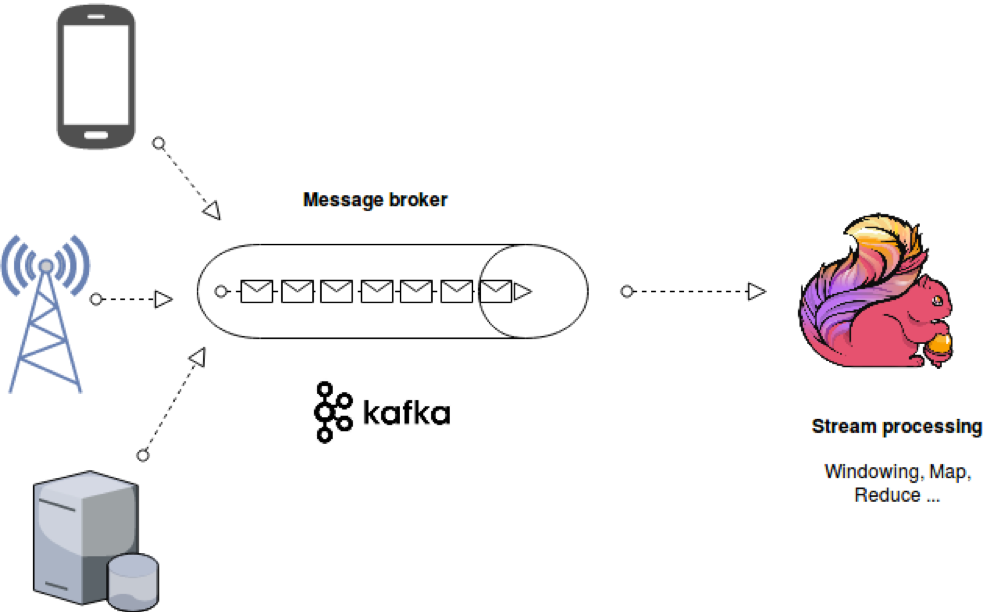
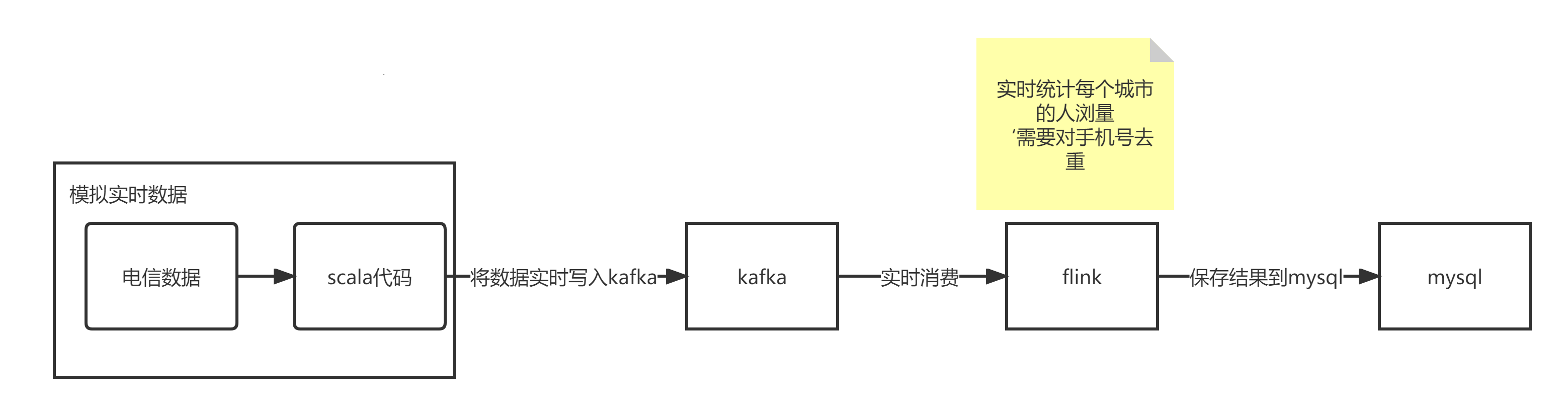
## kafka和flink结合案例
数据写入kafka,flink订阅消费
**安装kafka单服务**
1、官方下载地址:http://kafka.apache.org/downloads.html
2、解压安装包
下载完将安装包上传到centos中,然后解压
$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
3、 修改解压后的文件名称
$ mv kafka_2.12-3.0.0/ kafka
4、进入到/opt/module/kafka 目录,修改配置文件
$ cd config/
$ vim server.properties
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
每个 topic 创建时的副本数,默认时 1 个副本
offsets.topic.replication.factor=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个 segment 文件的大小,默认最大 1G
log.segment.bytes=1073741824
检查过期数据的时间,默认 5 分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
5、配置kafka环境变量
vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=
P
A
T
H
:
PATH:
PATH:KAFKA_HOME/bin
**自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。**
**深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!**
**因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。**

**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**

xYb0WNa-1712887931765)]
[外链图片转存中...(img-spS9eaM9-1712887931766)]
[外链图片转存中...(img-cIgKGg6N-1712887931766)]
[外链图片转存中...(img-QVRq0NOb-1712887931767)]
[外链图片转存中...(img-4VKI5D4Y-1712887931767)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!**
**由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新**
**如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)**
[外链图片转存中...(img-mYDs7bwl-1712887931767)]















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









