







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
3. ElasticSearch的搜索流程
- 客户端向集群发送请求,集群随机选择一个 NodeX 处理这次请求。
- Nodex 先计算文档在哪个主分片上,比如是主分片 A,它有三个副本 A1,A2,A3。那么请求
会轮询三个副本中的一个完成请求。 - 如果无法确认分片,比如检索的不是一个文档,就遍历所有分片。客户端发送请求到coordinate node,协调节点将搜索请求广播到所有的primary shard或replica,每个分片在本地执行搜索并构建一个匹配文档的大小为from + size的优先队列。接着每个分片返回各自优先队列中所有docld和打分值给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。协调节点根据Query阶段产生的结果,去各个节点上查询docld实际的document内容,最后由协调节点返回结果给客户端。
4. ElasticSearch如何实现master选举
Master节点负责管理集群状态信息,包括处理创建、删除索引等请求,决定分片被分配到哪个节点,维护和更新集群状态。值得注意的是,只有Master节点才能修改集群的状态信息,并负责同步给其他节点。

5. Elasticsearch更新和删除文档的过程

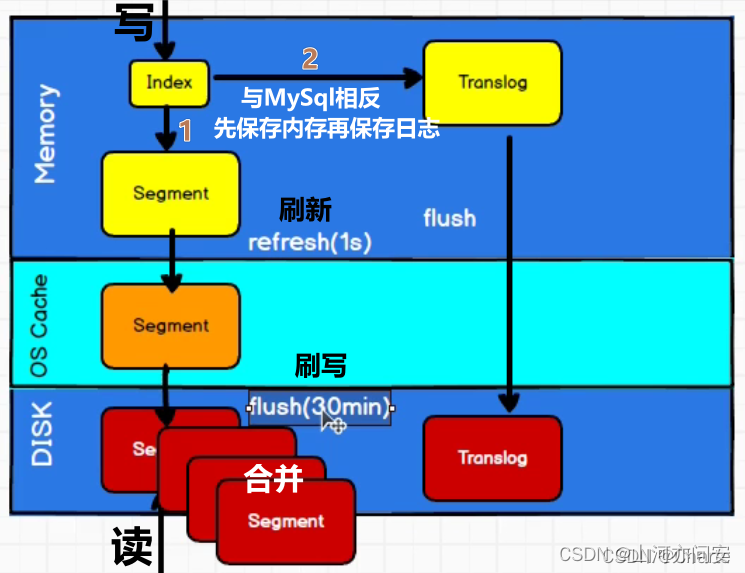
6. Elasticsearch创建索引文档的过程

7. 了解文本相似度 TF-IDF吗
TF = Term Frequency 词频,一个词在这个文档中出现的频率。值越大,说明这文档越匹配,
正向指标。
IDF = Inverse Document Frequency 反向文档频率,简单点说就是一个词在所有文档中都出
现,那么这个词不重要。
TF-IDF = TF / IDF
8. 了解ElasticSearch 深翻页的问题及解决吗?
深翻页:比如我们检索一次,轮询所有分片,汇集结果,根据 TF-IDF 等算法打分,排序后将前 10
条数据返回。用户感觉不错,说我看看下一页。ES 依然是轮询所有分片,汇集结果,根据 TF-IDF
等算法打分,排序后将前 11-20 条数据返回。
对用户来说,翻页应该很快啊,但是实际上,第一次检索多复杂,下一次检索就多复杂。
解决的话,可以把用户的检索结果,存入 Redis 中 10 分钟。这样分页就很快,超过 10 分钟,用户
不翻页,也就不会翻页了,数据就可以清除了。
9. 熟悉ElasticSearch 性能优化
- 批量提交
背景是大量的写操作,每次提交都是一次网络开销。网络永久是优化要考虑的重点。 - 优化硬盘
索引文件需要落地硬盘,段的思想又带来了更多的小文件,磁盘 IO 是 ES 的性能瓶颈。一个固态硬
盘比普通硬盘好太多。 - 减少副本数量
副本可以保证集群的可用性,但是严重影响了 写索引的效率。写索引时不只完成写入索引,还要完成索引到副本的同步。ES 不是存储引擎,不要考虑数据丢失,性能更重要。 如果是批量导入,建议就关闭副本。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









