







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[root@k8smaster ~]# kubectl describe nodes k8smaster
查看 master 这个节点是否有污点,显示如下:

上面可以看到 master 这个节点的污点是 Noschedule
所以我们创建的 pod 都不会调度到 master 上,因为我们创建的 pod 没有容忍度
[root@k8smaster ~]# kubectl describe pods kube-apiserver-k8smaster -n kube-system
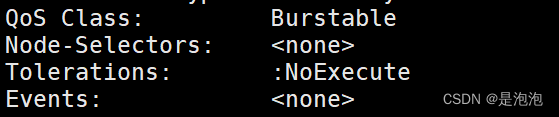
可以看到这个 pod 的容忍度是 NoExecute,则可以调度到 master1 上
#管理节点污点
[root@k8smaster ~]# kubectl taint --help
例:把 node2 当成是生产环境专用的,其他 node 是测试的
[root@k8smaster ~]# kubectl taint node k8snode2 nodetype=production:NoSchedule
node/k8snode2 tainted
给 node2 打污点,pod 如果不能容忍就不会调度过来
[root@k8smaster ~]# vim pod-taint.yaml
apiVersion: v1
kind: Pod
metadata:
name: taint-pod
namespace: default
labels:
tomcat: tomcat-pod
spec:
containers:
- name: taint-pod
ports:- containerPort: 8080
image: tomcat
imagePullPolicy: IfNotPresent
#yaml没有写污点容忍,所以调度不过去。
- containerPort: 8080
[root@k8smaster ~]# kubectl apply -f pod-taint.yaml
pod/taint-pod created
[root@k8smaster ~]# kubectl get pods -o wide
NAME READY STATUS NODE NOMINATED NODE
taint-pod 1/1 Running k8snode
可以看到都被调度到 node1 上了,因为 node2 这个节点打了污点,而我们在创建 pod 的时候没有容忍度,所以 node2 上不会有 pod 调度上去的。
给 node1 也打上污点
[root@k8smaster ~]# kubectl delete -f pod-taint.yaml
[root@k8smaster ~]# kubectl taint node xianchaonode1 node-type=dev:NoExecute
[root@k8smaster ~]# kubectl get pods -o wide
显示如下:
[root@k8smaster node]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
taint-pod 0/1 Pending 0 37s k8snode
上面可以看到已经存在的 pod 节点都被撵走了
[root@k8smaster node]# vim pod-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-deploy
namespace: default
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: nginx
ports:
- name: http
containerPort: 80
tolerations:
- key: “node-type”
operator: “Equal”
value: “production”
effect: “NoExecute”
tolerationSeconds: 3600
[root@k8smaster node]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8smaster node]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-deploy 0/1 Pending 0 16s
还是显示 pending,因为我们使用的是 equal(等值匹配),所以 key 和 value,effect 必须和node 节点定义的污点完全匹配才可以,把上面配置 effect: "NoExecute"变成 effect: "NoSchedule"成,tolerationSeconds: 3600 这行去掉.
[root@k8smaster node]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy2 created
[root@k8smaster node]# kubectl get pods
myapp-deploy 1/1 Running 0 17s k8snode2
上面就可以调度到 node2 上了,因为在 pod 中定义的容忍度能容忍 node 节点上的污点
#再次修改
tolerations:
- key: “node-type”
operator: “Exists”
value: “”
effect: “NoSchedule”
只要对应的键是存在的,exists,其值被自动定义成通配符
[root@k8smaster node]# kubectl delete -f pod-demo-1.yaml
[root@k8smaster node]# kubectl apply -f pod-demo-1.yaml
[root@k8smaster node]# kubectl get pods
发现还是调度到 node2 上
myapp-deploy 1/1 Running 0 17s k8snode2
再次修改
tolerations:
- key: “node-type”
operator: “Exists”
value: “”
effect: “”
有一个 node-type 的键,不管值是什么,不管是什么效果,都能容忍
[root@k8smaster node]# kubectl delete -f pod-demo-1.yaml
[root@k8smaster node]# kubectl apply -f pod-demo-1.yaml
[root@k8smaster node]# kubectl get pods -o wide
myapp-deploy 1/1 Running 0 17s k8snode
可以看到 node2 和 node 节点上都有可能有 pod 被调度
删除污点:
[root@k8smaster node]# kubectl taint nodes xianchaonode1 node-type:NoExecute-
[root@k8smaster node]# kubectl taint nodes xianchaonode2 node-type-
## Pod 常见的状态和重启策略
### 常见的 pod 状态
Pod 的 status 定义在 PodStatus 对象中,其中有一个 phase 字段。它简单描述了 Pod 在其生命周期的阶段。熟悉 Pod 的各种状态对我们理解如何设置 Pod 的调度策略、重启策略是很有必要的。
下面是 phase 可能的值,也就是 pod 常见的状态:
**挂起(Pending):** 我们在请求创建 pod 时,条件不满足,调度没有完成,没有任何一个节点能满足调度条件,已经创建了 pod 但是没有适合它运行的节点叫做挂起,调度没有完成,处于 pending的状态会持续一段时间:包括调度 Pod 的时间和通过网络下载镜像的时间。
**运行中(Running):** Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
**成功(Succeeded):** Pod 中的所有容器都被成功终止,并且不会再重启。
**失败(Failed):** Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止。
**未知(Unknown):** 未知状态,所谓 pod 是什么状态是 apiserver 和运行在 pod 节点的 kubelet 进行通信获取状态信息的,如果节点之上的 kubelet 本身出故障,那么 apiserver 就连不上kubelet,得不到信息了,就会 Unknown
还有其他状态,如下
**Evicted 状态:** 出现这种情况,多见于系统内存或硬盘资源不足,可 df-h 查看 docker 存储所在目录的资源使用情况,如果百分比大于 85%,就要及时清理下资源,尤其是一些大文件、docker 镜像。
**CrashLoopBackOff:** 容器曾经启动了,但可能又异常退出了 看日志解决
**Error 状态:** Pod 启动过程中发生了错误
### pod 重启策略
Pod 的重启策略(RestartPolicy)应用于 Pod 内的所有容器,并且仅在 Pod 所处的 Node 上由kubelet 进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet 将根据 RestartPolicy 的设置来进行相应的操作。
Pod 的重启策略包括 Always、OnFailure 和 Never,默认值为 Always。
Always:当容器失败时,由 kubelet 自动重启该容器。
OnFailure:当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器。
Never:不论容器运行状态如何,kubelet 都不会重启该容器。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
84847)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









