






数据结构课听得迷迷糊糊,通过查找多篇大佬博客。本篇文章基于头歌实践平台的python数据实验完成课程作业汇总而成。
图来源于(27条消息) C 数据结构之十大排序 三大查找_-牧野-的博客-CSDN博客_数据结构三大查找
第1关:二分查找算法
100
-
任务要求
-
参考答案
-
评论1
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成binarySearch函数’‘’def binarySearch(alist, item):
first = 0 # 查找范围第一项的下标
last = len(alist) - 1 # 查找范围最后一项的下标
found = Falsewhile first <= last and not found: midpoint = (first + last) // 2 # 中间项下标 # 若列表alist的中间项与查找项item相等,则查找成功,found置为True # 否则就需要缩小比对范围,分为两种情况: # 1.查找项比中间项小,说明查找项在前半部分,更改last # 2.查找项比中间项大,说明查找项在后半部分,更改first # ********** Begin ********** # if alist[midpoint]==item: found=True else: if item<alist[midpoint]: last=midpoint-1 elif item>alist[midpoint]: first=midpoint+1 # ********** End ********** # return found
第2关:二分查找的递归实现
100
-
任务要求
-
参考答案
-
评论1
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成binarySearch函数’‘’def binarySearch(alist, item):
if len(alist) == 0: # 递归的基本结束条件
return False
else:
midpoint = len(alist)//2
if alist[midpoint]==item:
return True
else: # 缩小规模
# 若查找项小于中间项,则需要递归调用自身来实现对前半部分(从最开始到中间)的查找,返回递归的结果
# 否则查找项大于中间项,则需要递归调用自身来实现对后半部分(从中间到最后)的查找,返回递归的结果
# ********** Begin ********** #
if item<alist[midpoint]:
return binarySearch(alist[:midpoint],item)
elif item>alist[midpoint]:
return binarySearch(alist[midpoint+1:],item)
# ********** End ********** ##### 第1关:冒泡排序的实现 100 -
任务要求
-
参考答案
-
评论
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成bubbleSort函数’‘’def bubbleSort(alist):
‘’’:param alist: 列表 :return: ''' for passnum in range(len(alist)-1,0,-1): # passnum从n-1开始,一直减到1,总共进行n-1趟排序 for i in range(passnum): # i从0开始,一直到(passnum-1),包括了这一趟比较的范围 # 对第i项和相邻的第i+1进行比较 # 如果是逆序的,就交换 # ********** Begin ********** # if alist[i]>alist[i+1]: temp=alist[i] alist[i]=alist[i+1] alist[i+1]=temp # ********** End ********** #####  -
第2关:冒泡排序算法的改进
100
-
任务要求
-
参考答案
-
评论
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成shortbubbleSort函数’‘’def shortbubbleSort(alist):
exchanges = True # 通过exchanges监测每趟比对是否发生过交换
passnum = len(alist)-1 # passnum从n-1开始
# 当还未完成n-1趟排序 且 上一趟排序发生了交换,则继续下一趟排序
while passnum > 0 and exchanges:
# 每趟排序首先将exchanges置为False,只要发生了交换就将其置为True
# ********** Begin ********** #
exchanges=False
for i in range(len(alist)-1):
if alist[i]>alist[i+1]:
temp=alist[i]
alist[i]=alist[i+1]
alist[i+1]=temp
exchanges=True
# ********** End ********** ##### 第1关:选择排序的实现 100 -
任务要求
-
参考答案
-
评论
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成selectionSort函数’‘’def selectionSort(alist):
for fillslot in range(len(alist)-1,0,-1): # fillslot从n-1开始,一直减到1,总共进行n-1趟排序
positionOfMax=0 # 用于记录当前最大项所在的位置
for location in range(1,fillslot+1):
# 对列表中的数据进行比较,得到最大项所在的位置
# ********** Begin ********** #
if alist[positionOfMax]<alist[location]:
positionOfMax=location# ********** End ********** # # 交换位置 temp = alist[fillslot] # ********** Begin ********** # alist[fillslot]=alist[positionOfMax] alist[positionOfMax]=temp # ********** End ********** #####  -
第1关:插入排序的实现
100
-
任务要求
-
参考答案
-
评论
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成insertionSort函数’‘’def insertionSort(alist):
for index in range(1,len(alist)): # 需要将第1个数据项后的n-1个数据项插入到有序子列表,循环n-1次
currentvalue = alist[index] # 当前的插入项
position = index
# 进行比较和移动
# ********** Begin ********** #
while position>0 and alist[position-1]>currentvalue:
alist[position]=alist[position-1]
position-=1
# ********** End ********** #
# 插入新项
alist[position]=currentvalue####  -
第1关:希尔排序的实现
100
-
任务要求
-
参考答案
-
评论
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成shellSort和gapInsertionSort函数’‘’希尔排序
def shellSort(alist):
sublistcount = len(alist) // 2 # 设定初始增量为n/2
while sublistcount > 0: # 不断缩小增量,进行多趟排序
for startposition in range(sublistcount): # 每进行一次循环就对某一个子列表进行排序
# 调用gapInsertionSort函数对子列表进行排序
# ********** Begin ********** #
gapInsertionSort(alist,startposition,sublistcount)# ********** End ********** # print("增量为", sublistcount, ":", alist) sublistcount = sublistcount // 2带间隔的插入排序
def gapInsertionSort(alist, start, gap):
for i in range(start + gap, len(alist), gap): # 循环的次数表示插入排序的趟数
currentvalue = alist[i] # 当前插入项的值
position = i # 当前插入项所在的位置
# 当 position-gap 位置有数据项 且 当前插入项小于 position-gap 位置的数据项,
# 就不断地进行以下操作
# 将 position-gap 位置的数据项在子列表中向右移动一个位置
# position 指向 position-gap 位置
# ********** Begin ********** #
while position>=gap and alist[position-gap]>currentvalue:
alist[position]=alist[position-gap]
position=position-gap# ********** End ********** # alist[position] = currentvalue # 找到当前插入项的插入位置#### 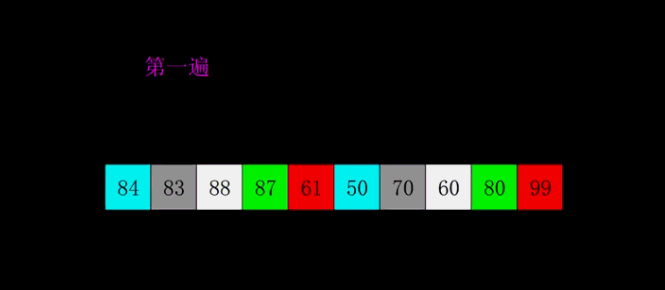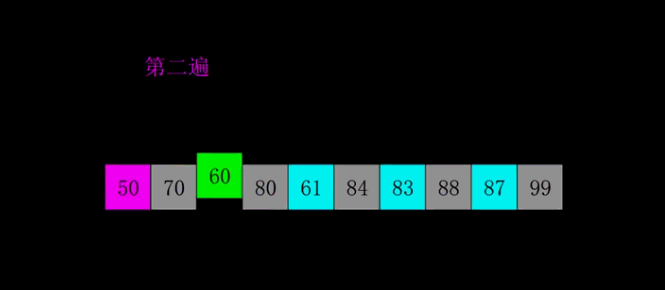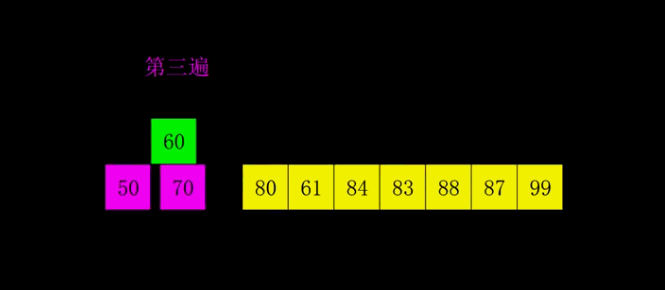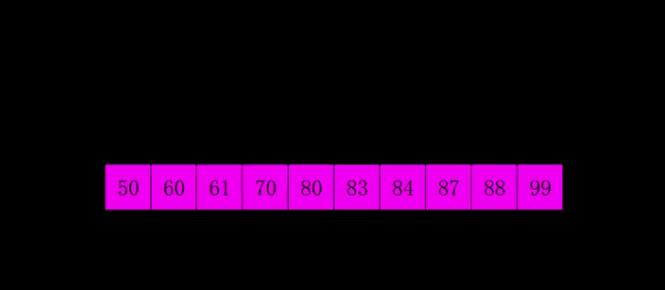 -
第1关:归并排序的实现
100
-
任务要求
-
参考答案
-
评论
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成mergeSort函数’‘’def mergeSort(alist):
if len(alist)>1: # 基本结束条件
mid = len(alist)//2
lefthalf = alist[:mid]
righthalf = alist[mid:]
# 递归调用mergeSort来对切片得到左半部分和右半部分进行排序
# ********** Begin ********** #mergeSort(lefthalf) mergeSort(righthalf) # ********** End ********** # i=0 j=0 k=0 # 此时左半部分和右半部分都已排好序,接下来需要对排好序的左右两半进行合并 while i<len(lefthalf) and j<len(righthalf): # 拉链式交错把左右半部分从小到大归并到结果列表中 if lefthalf[i]<righthalf[j]: alist[k]=lefthalf[i] i=i+1 else: # ********** Begin ********** # alist[k]=righthalf[j] j+=1 # ********** End ********** # k=k+1 # 归并左半部分的剩余项 while i<len(lefthalf): alist[k]=lefthalf[i] i=i+1 k=k+1 # 归并右半部分的剩余项 while j<len(righthalf): # ********** Begin ********** # alist[k]=righthalf[j] j+=1 k+=1 # ********** End ********** #####  -
第2关:归并排序的另一个实现
100
-
任务要求
-
参考答案
-
评论
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成merge_sort函数’‘’python风格的归并排序
def merge_sort(lst):
# 递归结束条件
if len(lst) <= 1:
return lst
# 分解问题,并递归调用
middle = len(lst) // 2
# 分别对左半部分和右半部分进行归并排序
# ********** Begin ********** #
left=merge_sort(lst[:middle])right=merge_sort(lst[middle:]) # ********** End ********** # # 合并左右半部,完成排序 merged = [] # 只要左右部分还有数据,就进行合并 # 将左半部分的首个数据(位置为0的数据)与右半部分的首个数据进行比较 # 把更小的数据添加到merged列表中,同时把它从原来所在列表中删除(下一次比较还是从0位置开始) while left and right: if left[0] <= right[0]: # ********** Begin ********** # merged.append(left.pop(0)) # ********** End ********** # else: merged.append(right.pop(0)) # 合并未合并的部分 # ********** Begin ********** # merged.extend(right if right else left) # ********** End ********** # # 返回结果 return merged#### 第1关:快速排序的实现 100 -
任务要求
-
参考答案
-
评论
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成quickSortHelper和partition函数’‘’快速排序
def quickSort(alist):
quickSortHelper(alist,0,len(alist)-1)指定当前排序列表开始(first)和结束(last)位置的快速排序
def quickSortHelper(alist,first,last):
if first<last: # 当列表至少包含两个数据项时,做以下操作
# 调用partition函数对当前排序列表进行拆分,返回分割点splitpoint
splitpoint = partition(alist,first,last)
# 递归调用quickSortHelper函数对拆分得到的左部分和右部分进行快速排序
# ********** Begin ********** #
quickSortHelper(alist,first,splitpoint-1)
quickSortHelper(alist,splitpoint+1,last)# ********** End ********** #拆分列表
def partition(alist,first,last):
pivotvalue = alist[first] # 选定基准值为列表的第一个数据项leftmark = first+1 # 左标 rightmark = last # 右标 done = False while not done: # 将左标向右移动,直至遇到一个大于基准值的数据项 while leftmark <= rightmark and alist[leftmark] <= pivotvalue: leftmark = leftmark + 1 # 将右标向左移动,直至遇到一个小于基准值的数据项 # ********** Begin ********** # while alist[rightmark]>=pivotvalue and rightmark>=leftmark: rightmark=rightmark-1 # ********** End ********** # # 右标小于左标时,结束移动 if rightmark < leftmark: done = True # 否则将左、右标所指位置的数据项交换 else: # ********** Begin ********** # temp=alist[leftmark] alist[leftmark]=alist[rightmark] alist[rightmark]=temp # ********** End ********** # # 将基准值就位 temp = alist[first] alist[first] = alist[rightmark] alist[rightmark] = temp return rightmark # 返回基准值位置,即分割点####  -
第1关:基数排序的实现
100
-
任务要求
-
参考答案
-
评论
-
测试说明```
‘’‘请在Begin-End之间补充代码, 完成radix_sort函数’‘’队列
class Queue:
def init(self):
self.items = []def isEmpty(self): # 判空 return self.items == [] def enqueue(self, item): # 入队 self.items.insert(0,item) def dequeue(self): # 出队 return self.items.pop() def size(self): return len(self.items)基数排序
def radix_sort(s):
main = Queue()
for n in s:
main.enqueue(n) # 所有数据项入队
d = len(str(max(s))) # 求出最大数据项的位数
dstr = “%%0%dd” % d # 前导零的模板,把数据项补齐为d位,位数不够的前面置0,如"%05d"表示补齐成五位数
nums = [Queue() for _ in range(10)] # 准备10个队列
for i in range(-1, -d-1, -1): # i的取值为-1到-d,代表从个位到最高位
while not main.isEmpty(): # 进行分配
n = main.dequeue()
dn = (dstr % n)[i] # 得到出队数据的第i位,转成类似"00345"[-2],即得到倒数第二位的4
nums[int(dn)].enqueue(n) # 放到对应的队列中
# 从10个队列中收集到main
# ********** Begin ********** #
for i in range(10):
while not nums[i].isEmpty():
main.enqueue(nums[i].dequeue())# 从main导出为列表 result = [] while not main.isEmpty(): result.append(main.dequeue()) return result
🤝 期待与你共同进步
🌱 亲爱的读者,非常感谢你每一次的停留和阅读!你的支持是我们前行的最大动力!🙏
🌐 在这茫茫网海中,有你的关注,我们深感荣幸。你的每一次点赞👍、收藏🌟、评论💬和关注💖,都像是明灯一样照亮我们前行的道路,给予我们无比的鼓舞和力量。🌟
📚 我们会继续努力,为你呈现更多精彩和有深度的内容。同时,我们非常欢迎你在评论区留下你的宝贵意见和建议,让我们共同进步,共同成长!💬
💪 无论你在编程的道路上遇到什么困难,都希望你能坚持下去,因为每一次的挫折都是通往成功的必经之路。我们期待与你一起书写编程的精彩篇章! 🎉
🌈 最后,再次感谢你的厚爱与支持!愿你在编程的道路上越走越远,收获满满的成就和喜悦!
关于Python学习指南
如果想要系统学习Python、Python问题咨询,或者考虑做一些工作以外的副业,都可以扫描二维码添加微信,围观朋友圈一起交流学习。


我们还为大家准备了Python资料和副业项目合集,感兴趣的小伙伴快来找我领取一起交流学习哦!
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】















 733
733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









