







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新软件测试全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

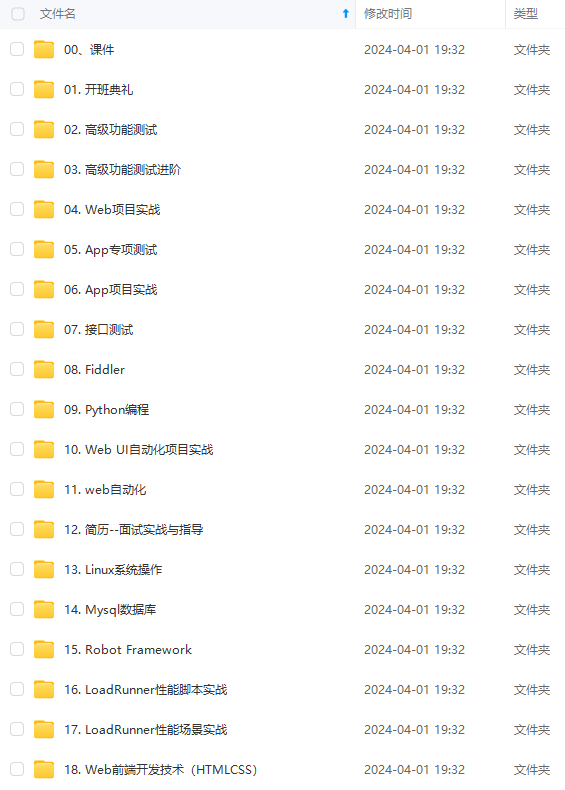
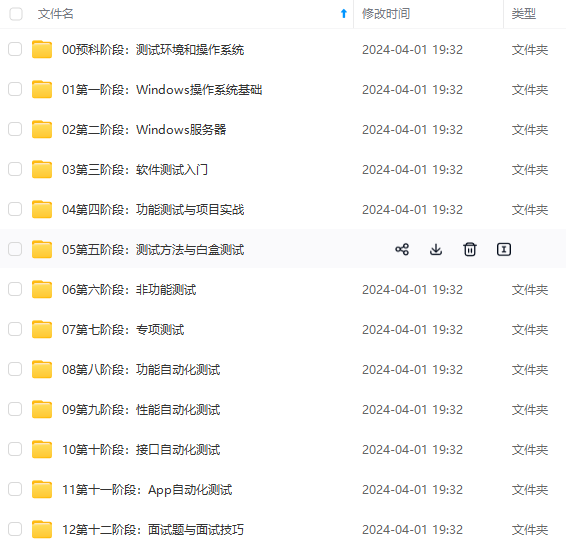
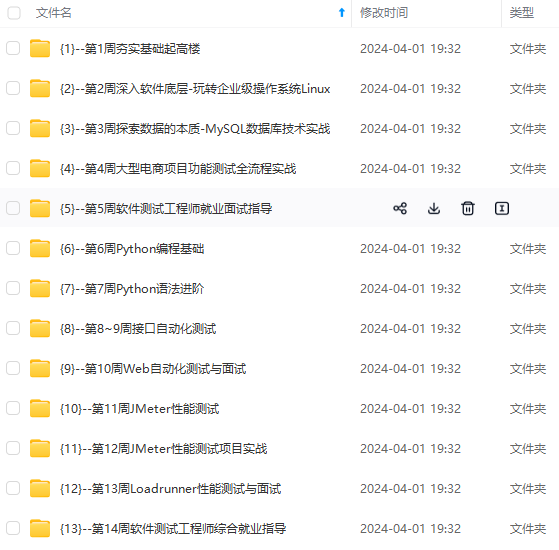

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注软件测试)

正文
- 建议89:枚举项的数量控制在64个以内
- 建议91:枚举和注解结合使用威力更大
-
- [建议92:注意@Override不同版本的区别](#92OverridehttpsgithubcomOverride_465)
引出
Java开发建议——通用准则,基本类型,类、对象及方法,字符串,数组和集合,枚举和注解,多线程和并发,性能和效率
通用的方法和准则
建议1:不要在常量和变量中出现易混淆的字母
- i、l、1;o、0等
建议2:莫让常量蜕变成变量
- 代码运行工程中不要改变常量值
建议3:三元操作符的类型务必一致
- 不一致会导致自动类型转换,类型提升int->float->double等
建议4:避免带有变长参数的方法重载
- 变长参数的方法重载之后可能会包含原方法
建议5:别让null值和空值威胁到变长方法
- 两个都包含变长参数的重载方法,当变长参数部分空值,或者为null值时,重载方法不清楚会调用哪一个方法
建议6:覆写变长方法也循规蹈矩
- 变长参数与数组,覆写的方法参数与父类相同,不仅仅是类型、数量,还包括显示形式
建议7:警惕自增的陷阱
- count=count++;操作时JVM首先将count原值拷贝到临时变量区,再执行count加1,之后再将临时变量区的值赋给count,所以count一直为0或者某个初始值。C中count=count;与count++等效,而PHP与Java类似
建议8:不要让旧语法困扰你
- Java中抛弃了C语言中的goto语法,但是还保留了该关键字,只是不进行语义处理,const关键中同样类似
建议9:少用静态导入
- Java5引入的静态导入语法import static,使用静态导入可以减少程序字符输入量,但是会带来很多代码歧义,省略的类约束太少,显得程序晦涩难懂
建议10:不要在本类中覆盖静态导入的变量和方法
- 例如静态导入Math包下的PI常量,类属性中又定义了一个同样名字PI的常量。编译器的“最短路径原则”将会选择使用本类中的PI常量。本类中的属性,方法优先。如果要变更一个被静态导入的方法,最好的办法是在原始类中重构,而不是在本类中覆盖
建议11:养成良好的习惯,显式声明UID
- 显式声明serialVersionUID可以避免序列化和反序列化中对象不一致,JVM根据serialVersionUID来判断类是否发生改变。隐式声明由编译器在编译的时候根据包名、类名、继承关系等诸多因子计算得出,极其复杂,算出的值基本唯一
建议12:避免用序列化类在构造函数中为不变量赋值
- 在序列化类中,不适用构造函数为final变量赋值)(**序列化规则1:**如果final属性是一个直接量,在反序列化时就会重新计算;**序列化规则2:**反序列化时构造函数不会执行;**反序列化执行过程:**JVM从数据流中获取一个Object对象,然后根据数据流中的类文件描述信息(在序列化时,保存到磁盘的对象文件中包含了类描述信息,不是类)查看,发现是final变量,需要重新计算,于是引用Person类中的name值,而此时JVM又发现name没有赋值(因为反序列化时构造函数不会执行),不能引用,于是它不再初始化,保持原始值状态。整个过程中需要保持serialVersionUID相同
建议13:避免为final变量复杂赋值
- 类序列化保存到磁盘上(或网络传输)的对象文件包括两部分:1、类描述信息:包括包路径、继承关系等。注意,它并不是class文件的翻版,不记录方法、构造函数、static变量等的具体实现。2、非瞬态(transient关键字)和非静态(static关键字)的实例变量值。总结:反序列化时final变量在以下情况下不会被重新赋值:1、通过构造函数为final变量赋值;2、通过方法返回值为final变量赋值;3、final修饰的属性不是基本类型
建议14:使用序列化类的私有方法巧妙解决“部分属性持久化问题”
- 部分属性持久化问题解决方案1:把不需要持久化的属性加上瞬态关键字(transient关键字)即可,但是会使该类失去了分布式部署的功能。方案2:新增业务对象。方案3:请求端过滤。方案4:变更传输契约,即覆写writeObject和readObject私有方法,在两个私有方法体内完成部分属性持久化
建议15:break万万不可忘
- switch语句中,每一个case匹配完都需要使用break关键字跳出,否则会依次执行完所有的case内容。
建议16:易变业务使用脚本语言编写
- 脚本语言:都是在运行期解释执行。脚本语言三大特性:1、灵活:动态类型;2、便捷:解释型语言,不需要编译成二进制,不需要像Java一样生成字节码,依靠解释执行,做到不停止应用变更代码;3、简单:部分简单。Java使用ScriptEngine执行引擎来执行JavaScript脚本代码
建议17:慎用动态编译
- 好处:更加自如地控制编译过程。很少使用,原因:静态编译能够完成大部分工作甚至全部,即使需要使用,也有很好的替代方案,如JRuby、Groovy等无缝的脚本语言。动态编译注意以下4点:
- 1、在框架中谨慎使用:debug困难,成本大;
- 2、不要在要求高性能的项目中使用:需要一个编译过程,比静态编译多了一个执行环节;
- 3、动态编译要考虑安全问题:防止恶意代码;
- 4、记录动态编译过程
建议18:避免instanceof非预期结果
- instanceof用来判断一个对象是否是一个类的实例,只能用于对象的判断,不能用于基本类型的判断(编译不通过),instanceof操作符的左右操作数必须有继承或实现关系,否则编译会失败。例:null instanceof String返回值是false,instanceof特有规则,若左操作数是null,结果就直接返回false,不再运算右操作数是什么类
建议19:断言绝对不是鸡肋
- 防御式编程中经常使用断言(Assertion)对参数和环境做出判断。断言是为调试程序服务的。两个特性:1、默认assert不启用;2、assert抛出的异常AssertionError是继承自Error的
建议20:不要只替换一个类
- 发布应用系统时禁止使用类文件替换方式,整体WAR包发布才是完全之策)(Client类中调用了Constant类中的属性值,如果更改了Constant常量类属性的值,重新编译替换。而不改变或者替换Client类,则Client中调用的Constant常量类的属性值并不会改变。**原因:**对于final修饰的基本类型和String类型,编译器会认为它是稳定态(Immutable Status),所以在编译时就直接把值编译到字节码中了,避免了再运行期引用,以提高代码的执行效率。而对于final修饰的类(即非基本类型),编译器认为它是不稳定态(Mutable Status),在编译时建立的则是引用关系(该类型也叫作Soft Final),如果Client类引入的常量是一个类或实例,即使不重新编译也会输出最新值
基本类型使用
建议21:用偶判断,不用奇判断
- 不要使用奇判断(i%2 == 1 ? “奇数” : “偶数”),使用偶判断(i%2 == 0 ? “偶数” : “奇数”)。原因Java中的取余(%标识符)算法:测试数据输入1 2 0 -1 -2,奇判断的时候,当输入-1时,也会返回偶数。
// 模拟取余计算,dividend被除数,divisor除数
public static int remainder(int dividend, int divisor) {
return dividend - dividend / divisor * divisor;}
建议22:用整数类型处理货币
- 不要使用float或者double计算货币,因为在计算机中浮点数“有可能”是不准确的,它只能无限接近准确值,而不能完全精确。不能使用计算机中的二进制位来表示如0.4等的浮点数。
- 解决方案:
- 1、使用BigDecimal(优先使用)
- 2、使用整型
建议23:不要让类型默默转换
- 基本类型转换时,使用主动声明方式减少不必要的Bug
public static final int LIGHT_SPEED = 30 * 10000 * 1000;long dis2 = LIGHT_SPEED * 60 * 8;
- 以上两句在参与运算时会溢出,因为Java是先运算后再进行类型转换的。因为dis2的三个运算参数都是int类型,三者相乘的结果也是int类型,但是已经超过了int的最大值,所以越界了。解决方法,在运算参数60后加L即可。
建议24:边界、边界、还是边界
- 数字越界是检验条件失效,边界测试;检验条件if(order>0 && order+cur<=LIMIT),输入的数大于0,加上cur的值之后溢出为负值,小于LIMIT,所以满足条件,但不符合要求
建议25:不要让四舍五入亏了一方
- Math.round(10.5)输出结果11;Math.round(-10.5)输出结果-10。这是因为Math.round采用的舍入规则所决定的(采用的是正无穷方向舍入规则),根据不同的场景,慎重选择不同的舍入模式,以提高项目的精准度,减少算法损失
建议26:提防包装类型的null值
- 泛型中不能使用基本类型,只能使用包装类型,null执行自动拆箱操作会抛NullPointerException异常,因为自动拆箱是通过调用包装对象的intValue方法来实现的,而访问null的intValue方法会报空指针异常。谨记一点:包装类参与运算时,要做null值校验,即(i!=null ? i : 0)
建议27:谨慎包装类型的大小比较
- 大于>或者小于<比较时,包装类型会调用intValue方法,执行自动拆箱比较。而==等号用来判断两个操作数是否有相等关系的,如果是基本类型则判断数值是否相等,如果是对象则判断是否是一个对象的两个引用,也就是地址是否相等。通过两次new操作产生的两个包装类型,地址肯定不相等
建议28:优先使用整型池
- 自动装箱是通过调用valueOf方法来实现的,包装类的valueOf生成包装实例可以显著提高空间和时间性能)valueOf方法实现源码:
public static Integer valueOf(int i) { final int offset = 128; if (i >= -128 && i <=127) { return IntegerCache.cache[i + offset]; } return new Integer(i); }class IntegerCache { static final Integer cache[] = new Integer[-(-128) + 127 + 1]; static { for (int i = 0; i < cache.length; i++) cache[i] = new Integer(i - 128); }}
- cache是IntegerCache内部类的一个静态数组,容纳的是**-128到127**之间的Integer对象。通过valueOf产生包装对象时,如果int参数在-128到127之间,则直接从整型池中获得对象,不在该范围的int类型则通过new生成包装对象。在判断对象是否相等的时候,最好是利用equals方法,避免“==”产生非预期结果。
建议29:优先选择基本类型
- int参数先加宽转变成long型,然后自动转换成Long型。Integer.valueOf(i)参数先自动拆箱转变为int类型,与之前类似
建议30:不要随便设置随机种子
- 若非必要,不要设置随机数种子)(Random r = new Random(1000);该代码中1000即为随机种子。在同一台机器上,不管运行多少次,所打印的随机数都是相同的。
在Java中,随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:1、种子不同,产生不同的随机数;
2、种子相同,即使实例不同也产生相同的随机数。
Random类默认种子(无参构造)是System.nanoTime()的返回值,这个值是距离某一个固定时间点的纳秒数,所以可以产生随机数。java.util.Random类与Math.random方法原理相同
类、对象及方法
建议31:在接口中不要存在实现代码
- 可以通过在接口中声明一个静态常量s,其值是一个匿名内部类的实例对象,可以实现接口中存在实现代码
建议32:静态变量一定要先声明后赋值
- 也可以先使用后声明,因为静态变量是类初始化时首先被加载,JVM会去查找类中所有的静态声明,然后分配空间,分配到数据区(Data Area)的,它在内存中只有一个拷贝,不会被分配多次,注意这时候只是完成了地址空间的分配还没有赋值,之后JVM会根据类中静态赋值(包括静态类赋值和静态块赋值)的先后顺序来执行,后面的操作都是地址不变,值改变
建议33:不要覆写静态方法
- 一个实例对象有两个类型:表面类型和实际类型,表面类型是声明时的类型,实际类型是对象产生时的类型。对于非静态方法,它是根据对象的实际类型来执行的,即执行了覆写方法。而对于静态方法,首先静态方法不依赖实例对象,通过类名访问;其次,可以通过对象访问静态方法,如果通过对象访问,JVM则会通过对象的表面类型查找到静态方法的入口,继而执行
建议34:构造函数尽量简化
- 通过new关键字生成对象时必然会调用构造函数。子类实例化时,首先会初始化父类(注意这里是初始化,可不是生成父类对象),也就是初始化父类的变量,调用父类的构造函数,然后才会初始化子类的变量,调用子类自己的构造函数,最后生成一个实例对象。构造函数太复杂有可能造成,对象使用时还没完成初始化
建议35:避免在构造函数中初始化其他类
- 有可能造成不断的new新对象的死循环,直到栈内存被消耗完抛出StackOverflowError异常为止
建议36:使用构造代码块精炼程序
- 四种类型的代码块:
- **1、普通代码块:**在方法后面使用“{}”括起来的代码片段;
- **2、静态代码块:**在类中使用static修饰,并使用“{}”括起来的代码片段;
- **3、同步代码块:**使用synchronized关键字修饰,并使用“{}”括起来的代码片段,表示同一时间只能有一个县城进入到该方法;
- **4、构造代码块:**在类中没有任何的前缀或后缀,并使用“{}”括起来的代码片段。编译器会把构造代码块插入到每个构造函数的最前端。
- 构造代码块的两个特性:1、在每个构造函数中都运行;2、在构造函数中它会首先运行
建议37:构造代码块会想你所想
- 编译器会把构造代码块插入到每一个构造函数中,有一个特殊情况:如果遇到this关键字(也就是构造函数调用自身其他的构造函数时)则不插入构造代码块。如果遇到super关键字,编译器会把构造代码块插入到super方法之后执行
建议38:使用静态内部类提高封装性
- Java嵌套内分为两种:1、静态内部类;2、内部类;静态内部类两个优点:加强了类的封装性和提高了代码的可读性。静态内部类与普通内部类的区别:1、静态内部类不持有外部类的引用,在普通内部类中,我们可以直接访问外部类的属性、方法,即使是private类型也可以访问,这是因为内部类持有一个外部类的引用,可以自由访问。而静态内部类,则只可以访问外部类的静态方法和静态属性,其他则不能访问。2、静态内部类不依赖外部类,普通内部类与外部类之间是相互依赖的关系,内部类不能脱离外部类实例,同声同死,一起声明,一起被垃圾回收器回收。而静态内部类可以独立存在,即使外部类消亡了;3、普通内部类不能声明static的方法和变量,注意这里说的是变量,常量(也就是final static修饰的属性)还是可以的,而静态内部类形似外部类,没有任何限制
建议39:使用匿名类的构造函数
- List l2 = new ArrayList(){}; //定义了一个继承于ArrayList的匿名类,只是没有任何的覆写方法而已
List l3 = new ArrayList(){{}}; //定义了一个继承于ArrayList的匿名类,并且包含一个初始化块,类似于构造代码块)
建议40:匿名类的构造函数很特殊
- 匿名类初始化时直接调用了父类的同参数构造器,然后再调用自己的构造代码块
建议41:让多重继承成为现实
- Java中一个类可以多种实现,但不能多重继承。使用成员内部类实现多重继承。内部类一个重要特性:内部类可以继承一个与外部类无关的类,保证了内部类的独立性,正是基于这一点,多重继承才会成为可能
建议42:让工具类不可实例化
- 工具类的方法和属性都是静态的,不需要实例即可访问。**实现方式:**将构造函数设置为private,并且在构造函数中抛出Error错误异常
建议43:避免对象的浅拷贝
- 浅拷贝存在对象属性拷贝不彻底的问题。对于只包含基本数据类型的类可以使用浅拷贝;而包含有对象变量的类需要使用序列化与反序列化机制实现深拷贝
建议44:推荐使用序列化实现对象的拷贝
- 通过序列化方式来处理,在内存中通过字节流的拷贝来实现深拷贝。使用此方法进行对象拷贝时需注意两点:1、对象的内部属性都是可序列化的;2、注意方法和属性的特殊修饰符,比如final、static、transient变量的序列化问题都会影响拷贝效果。一个简单办法,使用Apache下的commons工具包中的SerializationUtils类,直接使用更加简洁方便
建议45:覆写equals方法时不要识别不出自己
- 需要满足p.equals§返回为真,自反性
建议46:equals应该考虑null值情景
- 覆写equals方法时需要判一下null,否则可能产生NullPointerException异常
建议47:在equals中使用getClass进行类型判断
- 使用getClass方法来代替instanceof进行类型判断
建议48:覆写equals方法必须覆写hashCode方法
- 需要两个相同对象的hashCode方法返回值相同,所以需要覆写hashCode方法,如果不覆写,两个不同对象的hashCode肯定不一样,简单实现hashCode方法,调用org.apache.commons.lang.builder包下的Hash码生成工具HashCodeBuilder
建议49:推荐覆写toString方法
- 原始toString方法显示不人性化
建议50:使用package-info类为包服务
- package-info类是专门为本包服务的,是一个特殊性主要体现在3个方面:1、它不能随便被创建;2、它服务的对象很特殊;3、package-info类不能有实现代码;package-info类的作用:1、声明友好类和包内访问常量;2、为在包上标注注解提供便利;3、提供包的整体注释说明
建议51:不要主动进行垃圾回收
- 主动进行垃圾回收是一个非常危险的动作,因为System.gc要停止所有的响应(Stop 天河world),才能检查内存中是否有可回收的对象,所有的请求都会暂停
字符串
建议52:推荐使用String直接量赋值
- 一般对象都是通过new关键字生成,String还有第二种生成方式,即直接声明方式,如String str = “a”;String中极力推荐使用直接声明的方式,不建议使用new String(“a”)的方式赋值。**原因:直接声明方式:**创建一个字符串对象时,首先检查字符串常量池中是否有字面值相等的字符串,如果有,则不再创建,直接返回池中引用,若没有则创建,然后放到池中,并返回新建对象的引用。**使用new String()方式:**直接声明一个String对象是不检查字符串常量池的,也不会吧对象放到池中。String的intern方法会检查当前的对象在对象池中是否有字面值相同的引用对象,有则返回池中对象,没有则放置到对象池中,并返回当前对象
建议53:注意方法中传递的参数要求
- replaceAll方法传递的第一个参数是正则表达式
建议54:正确使用String、StringBuffer、StringBuilder
- String使用“+”进行字符串连接,之前连接之后会产生一个新的对象,所以会不断的创建新对象,优化之后与StringBuilder和StringBuffer采用同样的append方法进行连接,但是每一次字符串拼接都会调用一次toString方法,所以会很耗时。StringBuffer与StringBuilder基本相同,只是一个字符数组的在扩容而已,都是可变字符序列,不同点是:StringBuffer是线程安全的,StringBuilder是线程不安全的
建议55:注意字符串的位置
- 在“+”表达式中,String字符串具有最高优先级)(Java对加号“+”的处理机制:在使用加号进行计算的表达式中,只要遇到String字符串,则所有的数据都会转换为String类型进行拼接,如果是原始数据,则直接拼接,如果是对象,则调用toString方法的返回值然后拼接
建议56:自由选择字符串拼接方式
- 字符串拼接有三种方法:加号、concat方法及StringBuilder(或StringBuffer)的append方法。字符串拼接性能中,StringBuilder的append方法最快,concat方法次之,加号最慢。
原因:
- 1、“+”方法拼接字符串:虽然编译器对字符串的加号做了优化,使用StringBuidler的append方法进行追加,但是与纯粹使用StringBuilder的append方法不同:一是每次循环都会创建一个StringBuilder对象,二是每次执行完都要调用toString方法将其准换为字符串—toString方法最耗时;
- 2、concat方法拼接字符串:就是一个数组拷贝,但是每次的concat操作都会新创建一个String对象,这就是concat速度慢下来的真正原因;
- 3、append方法拼接字符串:StringBuidler的append方法直接由父类AbstractStringBuilder实现,整个append方法都在做字符数组处理,没有新建任何对象,所以速度快
建议57:推荐在复杂字符串操作中使用正则表达式
- 正则表达式是恶魔,威力强大,但难以控制
建议58:强烈建议使用UTF编码
- 一个系统使用统一的编码
建议59:对字符串排序持一种宽容的心态
- 如果排序不是一个关键算法,使用Collator类即可。主要针对于中文
数组和集合
建议60:性能考虑,数组是首选
- 性能要求较高的场景中使用数组替代集合)(基本类型在栈内存中操作,对象在堆内存中操作。数组中使用基本类型是效率最高的,使用集合类会伴随着自动装箱与自动拆箱动作,所以性能相对差一些
建议61:若有必要,使用变长数组
- 使用Arrays.copyOf(datas,newLen)对原数组datas进行扩容处理
建议62:警惕数组的浅拷贝
- 通过Arrays.copyOf(box1,box1.length)方法产生的数组是一个浅拷贝,这与序列化的浅拷贝完全相同:基本类型是直接拷贝值,其他都是拷贝引用地址。数组中的元素没有实现Serializable接口
建议63:在明确的场景下,为集合指定初始容量
- ArrayList集合底层使用数组存储,如果没有初始为ArrayList指定数组大小,默认存储数组大小长度为10,添加的元素达到数组临界值后,使用Arrays.copyOf方法进行1.5倍扩容处理。HashMap是按照倍数扩容的,Stack继承自Vector,所采用扩容规则的也是翻倍
建议64:多种最值算法,适时选择
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
建议62:警惕数组的浅拷贝
- 通过Arrays.copyOf(box1,box1.length)方法产生的数组是一个浅拷贝,这与序列化的浅拷贝完全相同:基本类型是直接拷贝值,其他都是拷贝引用地址。数组中的元素没有实现Serializable接口
建议63:在明确的场景下,为集合指定初始容量
- ArrayList集合底层使用数组存储,如果没有初始为ArrayList指定数组大小,默认存储数组大小长度为10,添加的元素达到数组临界值后,使用Arrays.copyOf方法进行1.5倍扩容处理。HashMap是按照倍数扩容的,Stack继承自Vector,所采用扩容规则的也是翻倍
建议64:多种最值算法,适时选择
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注软件测试)
[外链图片转存中…(img-y3rUUT6r-1713321025869)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2224
2224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









