






本章将通过对分类分析的介绍,引入常见的分类算法,常见的分类算法有支持向量机、逻辑回归、决策树、K近邻、随机森林、朴素贝叶斯。结合各种算法的概念、原理、步骤等,使用Python语言及阿里云机器学习PAI平台,进行数据挖掘分析。
一,分类分析
1.1分类分析概述
分类(Categorization或Classification)就是按照某种标准给对象贴标签(label),再根据标签来区分归类。例如在水果店,水果会被分门别类地装在不同的销售框中,在销售框上会标注水果的相关信息,把水果名类比为标签,再次进货后服务员会根据水果信息,将对应的水果加入到对应的销售框,这个过程就叫作分类。
从机器学习上看,分类作为一种监督学习方法,它的目标在于通过已有数据的确定类别,学习得到一个分类函数或分类模型(也常常称作分类器),该模型能把数据库中的数据项映射到给定类别中的某一个类中。简单地说,就是在进行分类前,得到的数据已经标示了数据所属的类别,分类的目标就是得到一个分类的标准,使得能够更好地把不同类别的数据区分出来。
要构造分类器,需要有一个训练样本数据集作为输入。分类器需要由人工标注的分类训练语料训练得到,属于有指导学习范畴。训练集由一组数据库记录或元组构成,每个元组是一个由有关字段(又称属性或特征)值组成的特征向量,此外,训练样本还有一个类别标记。分类器的构造方法有统计方法、机器学习方法、神经网络方法等。
按照判别数组划分的话,分类算法可以分成二分类和多分类。在日常的生活和工作中,存在很多二分类情况和多分类情况,如交警在查酒驾的时候要判断司机是否喝酒,那么喝了酒或未喝酒,就是二分类问题;如开车到十字路口,遇到的可能是红灯、绿灯、黄灯,类似这种超过两个分类的问题就称为多分类问题。
按照分类策略进行划分的话,分类算法可以分为判别分析分类和机器学习分类,判别分析又根据不同的形式或方法再划分,如图6-1所示。
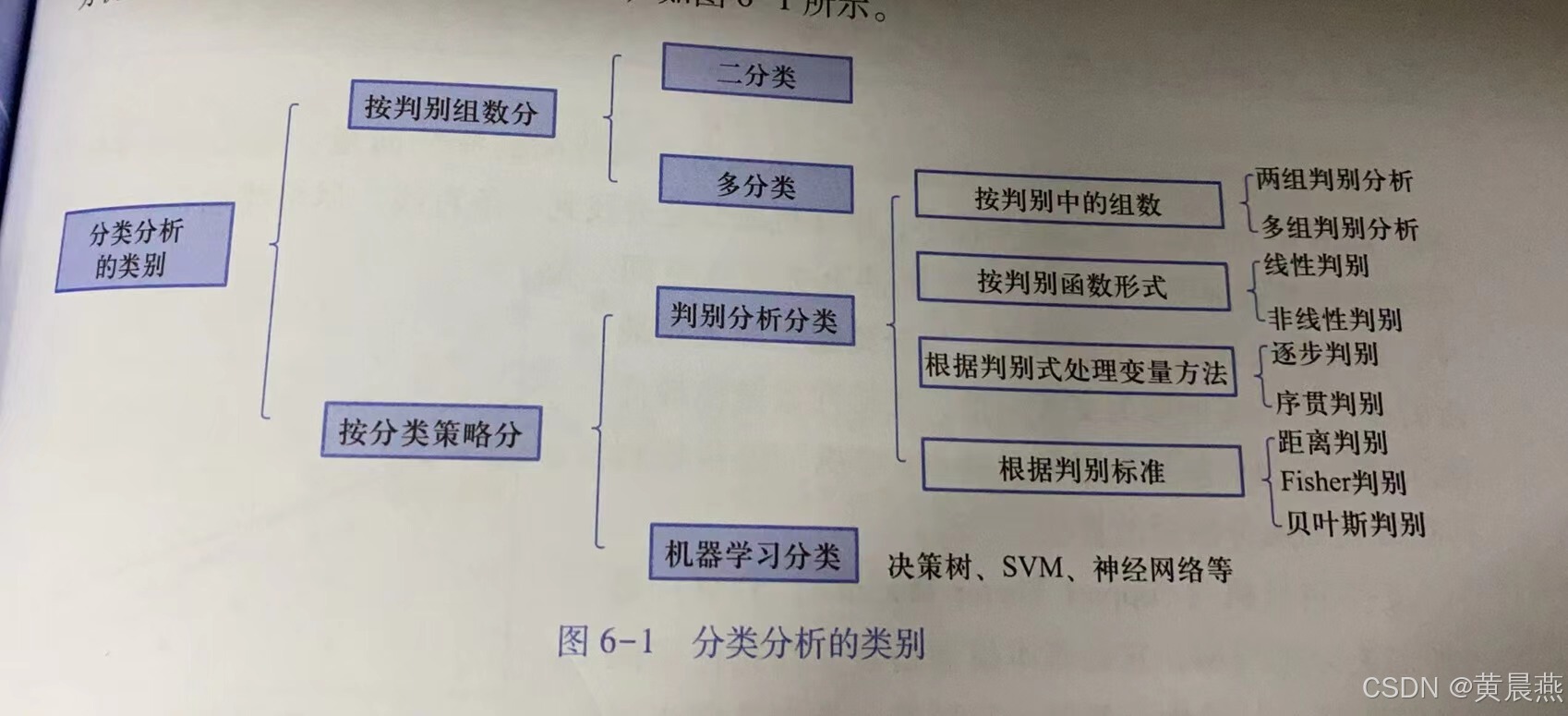
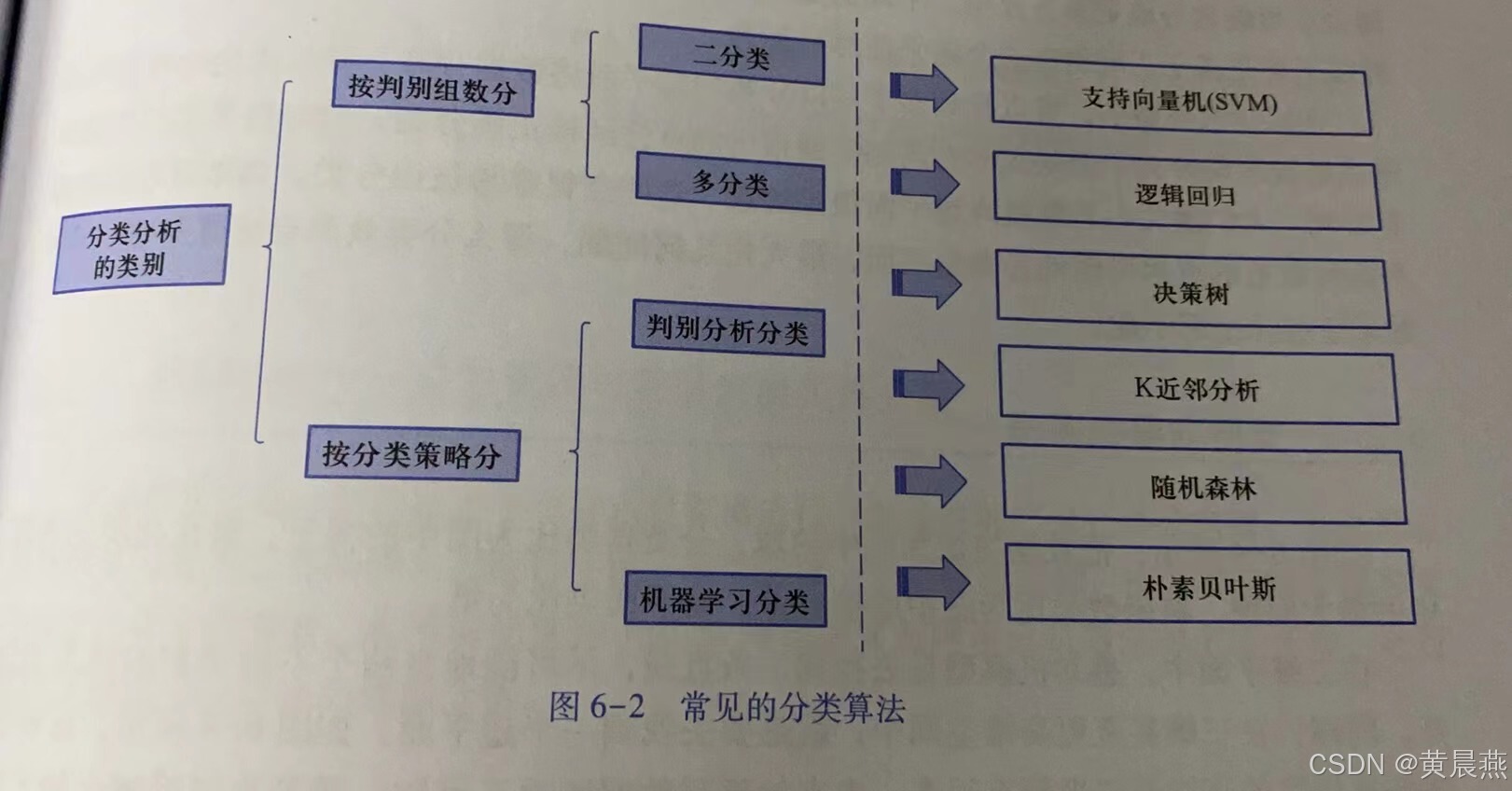
从判别或策略进行划分得到6种常见的分类算法,如图6-2所示,分别是支持向量机、逻辑回归、决策树、K近邻、随机森林、朴素贝叶斯。
1.2支持向量机
本节通过介绍支持向量机算法的基本概念、提出的背景、原理和步骤等,再结合具体的实例,使用Python编程语言及阿里云机器学习PAI平台,进行基于支持向量机算法的数据挖掘分析。
1.2.1支持向量机概念
感知机是二分类的线性分类模型,其输入为实例特征的特征向量,输出为实例的类别。如图6-3所示,在二维平面中,感知机模型是去找到一条直线,尽可能地将两个不同类别的样本点分开。
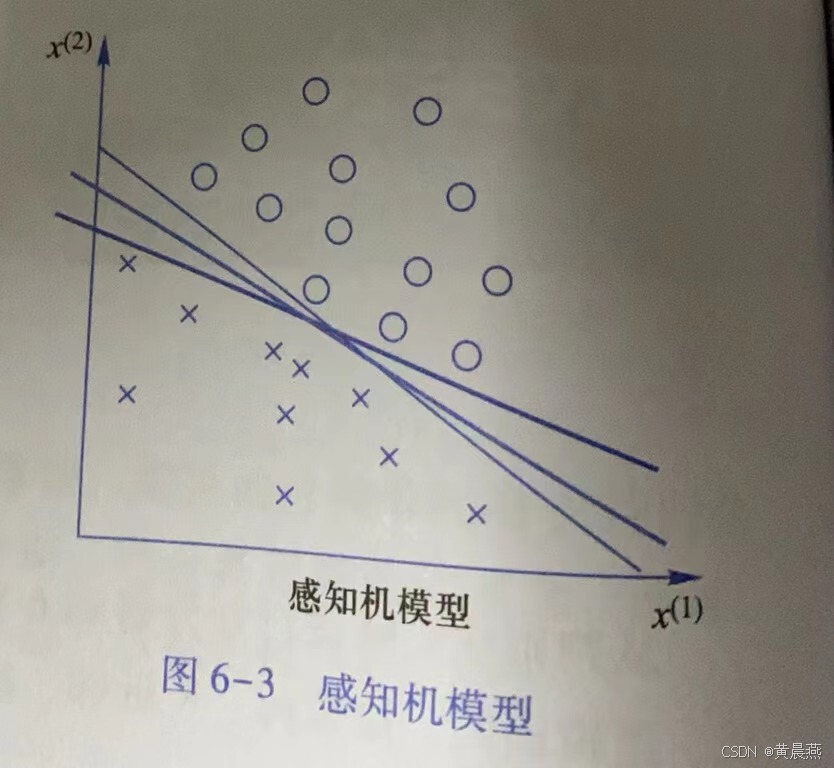
同理,在三维甚至更高维空间中,就是要去找到一个超平面。与分离超平面距离最近的样本点的实例称为支持向量。支持向量是使最优化问题中的约束条件等号成立的点,“机”是指找到具有最大间隔分隔面的算法。
1.2.2支持向量机原理
如图 6-4所示,把数据类比为图中的球,分类器类比为图中的棍子,最优化类比为图中的最大间隙,核函数类比为图中的拍桌子,超平面类比为纸。
在二维平面中,感知机模型是去找到一条直线,尽可能地将两个不同类别的样本点分开。同理,在三维甚至更高维空间中,就是要去找到一个超平面。如图6-4所示,这样起到分类作用的直线或超平面有很多,未来的预测数据性质不可知,哪条直线或哪个超平面是最优的,也就是找出具有最好的鲁棒性和最强的泛化能力的超平面。
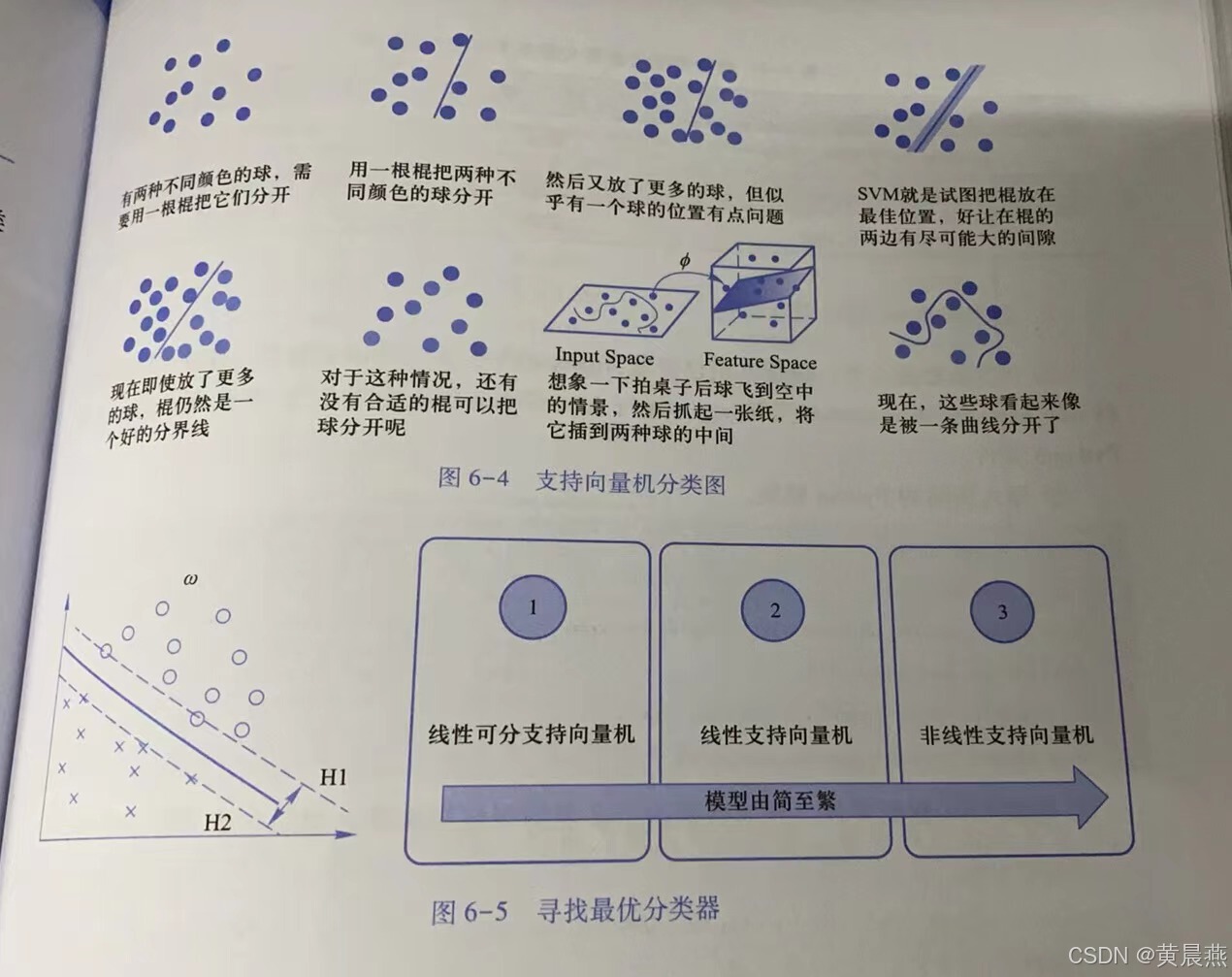
观察图 6-5可以分析得出,通过优化找到一个最优的分类器,换言之,找到一个超平面,其分类间隔最大;优化的目标函数是分类间隔,需要使得分类间隔最大;优化的对象是分类超平面。通过调整分类超平面的位置,使得间隔最大,实现优化目标。
1.2.3实战案例--食物变质与菌落含量关系分析
支持向量机是一类按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。本节通过一个具体的实例,使读者能够加深对支持向量机模型的理解,掌握如何使用Python编程语言及阿里云机器学习PAI平台,进行基于支持向量机算法的数据分析。
1.数据分析任务
本节实例提供某食物菌落含量数据,需要分析同一种食物的变质与两种不同菌落含量之间的关系,要求通过支持向量机的算法,建立菌落含量与变质之间的关系,使用支持向量机算法进行模拟实验二分类,以达成通过菌落含量预测变质与否的目标。其中数据文件为ods_bacteria_deterioration_info.csv,字段说明见表 6-1。
2.基于Python编程语言实现
①开发前准备工作:确保本机已安装Anaconda3-5.1.0及以上版本,准备本地数据文件ods_bacteria_deterioration_info.csv,运行Jupyter Notebook程序,在 Web浏览器中新建 Python3 文件。
导入所需的 Python 模块。
import numpy as np
import pandas as pd
from sklearn. model_selection import train_test_split
from sklearn. svm import SVC
from sklearn. metrics import classification_report
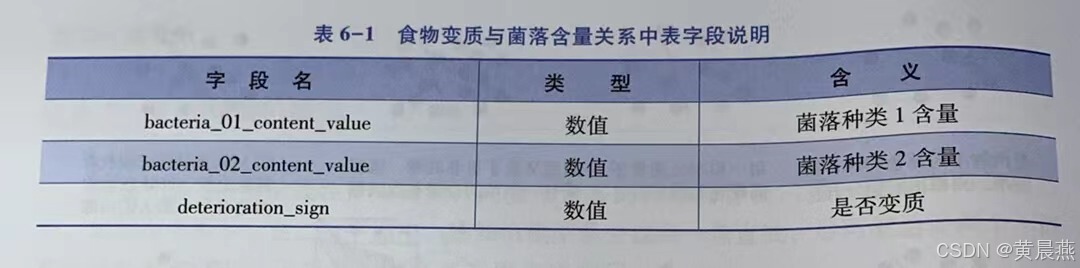
from sklearn. metrics import roc_auc_score③加载CSV数据文件,并对数据进行必要的观察和探查,如图6-6和图6-7所示。
#读取数据集
dataset = pd. read_csv( "ods_bacteria_deterioration_info.csv")
#查看数据:查看数据的前几条记录
dataset. head( )
#数据集统计性描述:观察数据的数量、中值、标准值、最大值、最小值等
dataset. describe( )
#数据集信息:查看数据集属性的数据类型、数据量、是否有空值等
dataset.info( )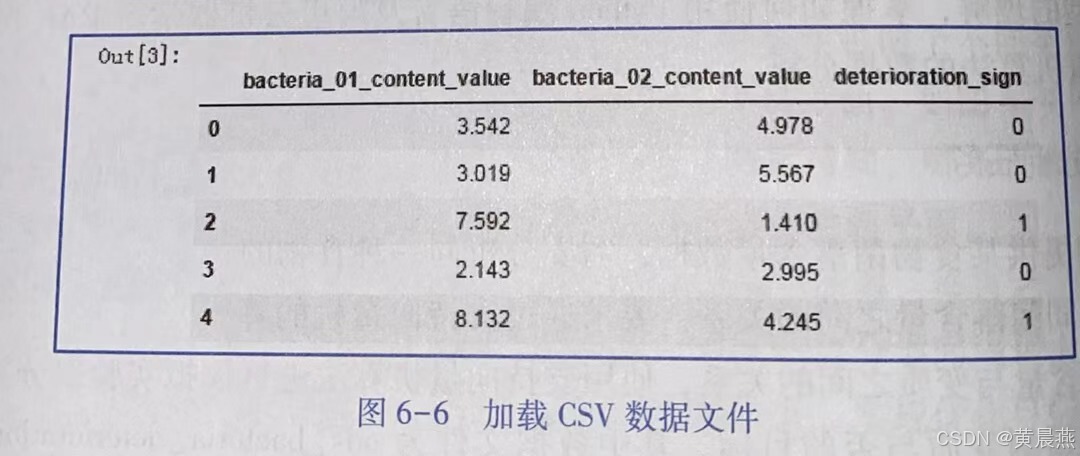
④区分输入及输出数据,其中输入数据为菌落种类含量,输出数据为是否变质,如图6-8所示。
#查看各类别计数
dataset[ "deterioration_sign" ].value_counts( )
#区分特征及标签数据
x =dataset[["bacteria_01_content_value" , " bacteria_02_content_value" ] ]. values
y =dataset[ "deterioration_sign" ]. values
⑤设置随机数种子,确保结果可重现,并按比例随机拆分训练样本和测试样本。
#设置随机数种子
np.random.seed =123
#拆分样本
( train_x,test_x, train_y,test_y) = train_test_split(x,y,train_size=0. 7, test_size=0.3)⑥使用线性核函数linear构建SVM模型,并通过样本集对模型进行训练,如图6-9所示。
#构建 SVM模型,核函数:高斯核函数rbf/线性核函数linear/多项式核函数 poly
model=SVC( kernel='linear' , probability =True )
#通过训练样本训练模型
model. fit(train_x, train_y)
⑦使用精准率Precision、召回率Recall、F1-score等指标对模型进行评价,如图6-10所示。
#通过测试样本评估模型
print("模型评分:",model.score( test_x,test_y))
#测试样本分类报告
print ( classification_report( test_y ,model. predict(test_x) ))
print( "AUC 值:" ,roc_auc_score( test_y , model. predict( test_x)))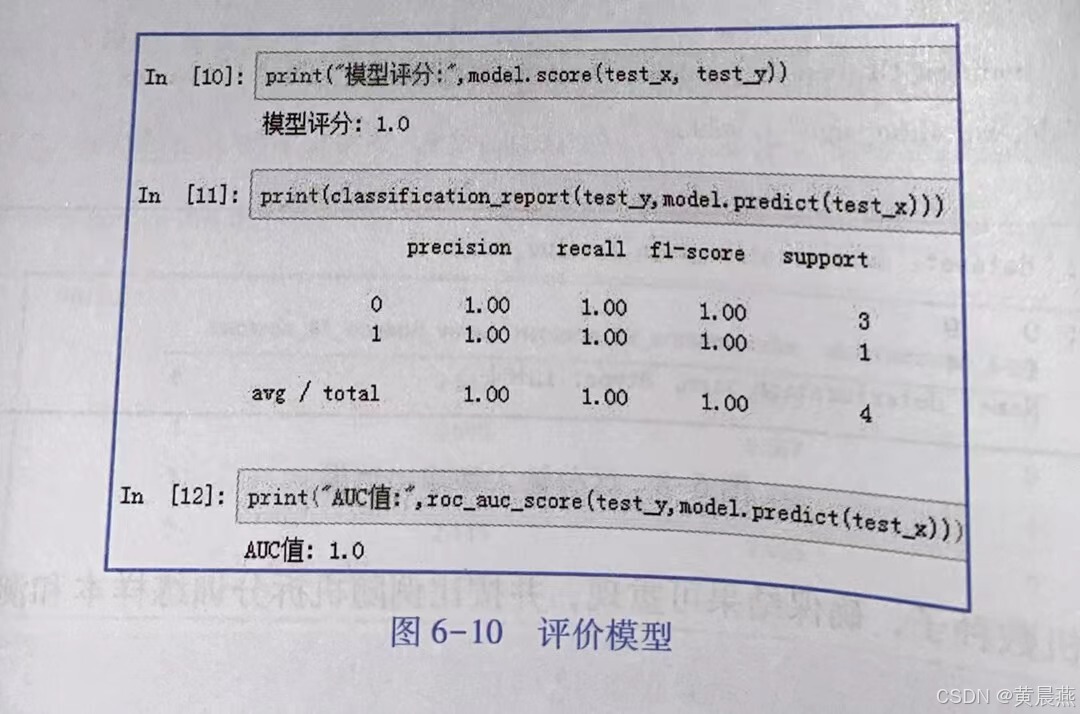 ⑧利用模型预测新的数据,如图6-11所示。
⑧利用模型预测新的数据,如图6-11所示。
#预测新数据
print( model. predict([[3,5]]))
print("概率:",model. predict_proba([[3,5]]).max( )
通过比较测试集中的属性“是否变质”和预测得到的结果,可以得出预测正确的概率为0.907,说明使用支持向量机建立的模型预测效果良好,在二分类问题上可以选择使用支持向量机算法进行建模和预测。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









