







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Golang全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

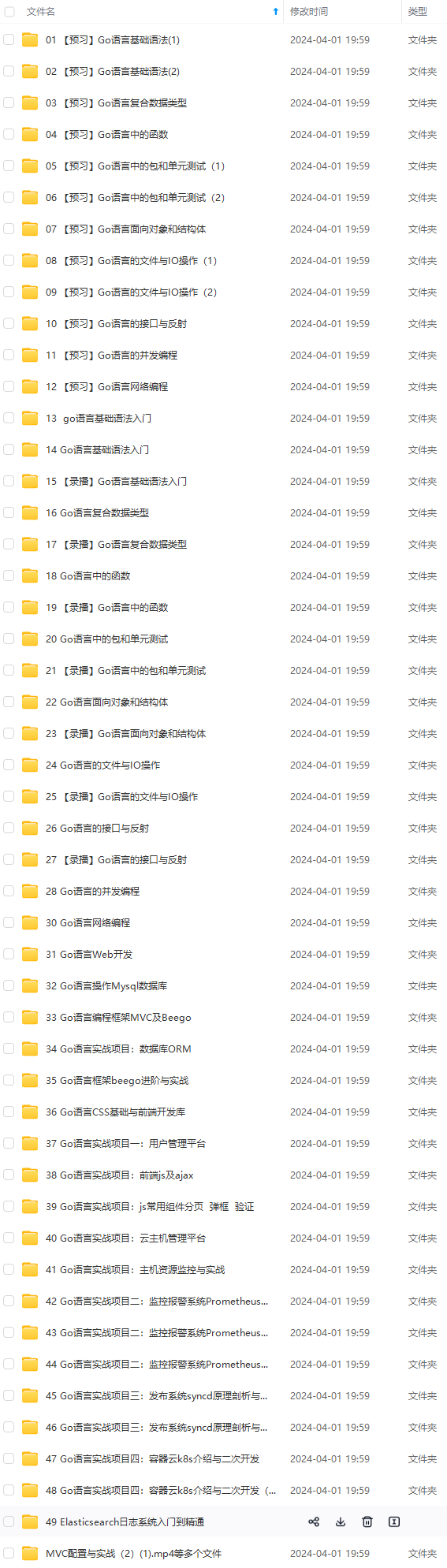
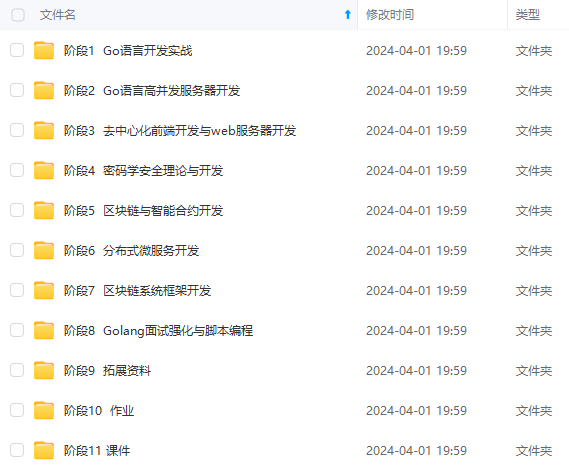
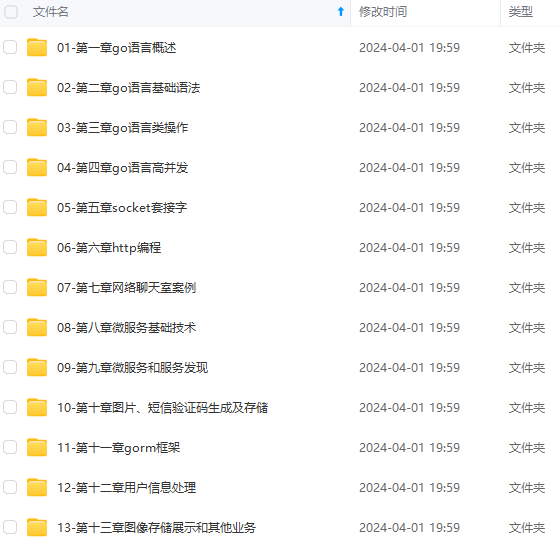
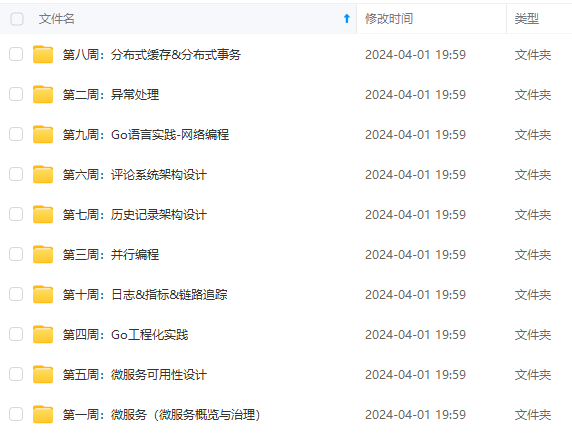
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注go)

正文
30. 在MySQL中,如何确保数据备份的完整性和一致性?
确保MySQL数据备份的完整性和一致性的方法包括:
- 使用可靠的备份工具:如
mysqldump或Percona XtraBackup。 - 确保备份时数据库的一致性:对于InnoDB表,使用
--single-transaction选项进行一致性备份。 - 定期验证备份:通过恢复过程验证备份的有效性。
- 定期执行备份:设置定期备份计划以捕捉数据的最新状态。
备份的关键是确保在需要时能够可靠地恢复数据,同时保证备份过程不会对生产环境造成显著影响。
31. MySQL中的常见性能瓶颈有哪些,以及如何解决?
常见的MySQL性能瓶颈包括:
- 磁盘I/O:优化查询,减少不必要的数据访问,使用更快的磁盘。
- 网络延迟:优化应用程序与数据库服务器之间的通信,考虑使用连接池。
- 查询效率:使用索引,优化复杂查询,避免全表扫描。
- 锁竞争:减少长事务,优化锁粒度,避免不必要的行锁。
32. 如何在MySQL中设置和使用存储过程的参数?
存储过程可以接受输入参数和返回输出参数。例如,创建一个计算两数之和的存储过程:
DELIMITER //
CREATE PROCEDURE AddNumbers(IN num1 INT, IN num2 INT, OUT sum INT)
BEGIN
SET sum = num1 + num2;
END //
DELIMITER ;
调用存储过程并获取结果:
CALL AddNumbers(10, 20, @sum);
SELECT @sum;
33. 解释MySQL中的触发器类型。
MySQL中的触发器类型包括:
- BEFORE INSERT:在插入操作之前触发。
- AFTER INSERT:在插入操作之后触发。
- BEFORE UPDATE:在更新操作之前触发。
- AFTER UPDATE:在更新操作之后触发。
- BEFORE DELETE:在删除操作之前触发。
- AFTER DELETE:在删除操作之后触发。
每种触发器都可以用来在数据变更时执行特定的逻辑。
34. 在MySQL中如何管理并调整缓冲池的大小?
InnoDB缓冲池的大小可以通过innodb_buffer_pool_size参数进行配置。这个参数决定了MySQL用于缓存数据和索引的内存量。调整缓冲池大小通常涉及以下步骤:
- 评估服务器上可用的内存量。
- 考虑到其他进程的内存需求,设置
innodb_buffer_pool_size。 - 在配置文件(例如
my.cnf或my.ini)中设置参数。 - 重启MySQL服务器以使更改生效。
35. MySQL如何处理大量的并发连接?
处理大量并发连接时,MySQL可以通过以下方式优化:
- 增加最大连接数:通过调整
max_connections参数来允许更多的并发连接。 - 使用连接池:应用层面使用连接池可以减少连接和断开连接的开销。
- 优化线程池:配置MySQL的线程池以更高效地处理请求。
- 读写分离:在主从架构中,将读操作分配给从服务器,减轻主服务器的负担。
适当配置和优化这些参数可以显著提高MySQL在高并发环境下的性能。
36. 如何在MySQL中优化COUNT()查询?
优化COUNT()查询的方法包括:
- 使用更快的存储引擎,如InnoDB。
- 对于
COUNT(*),避免使用具有许多索引的大表。 - 对于
COUNT(column),确保列上有索引。 - 考虑使用汇总表或缓存技术,特别是对于大数据集。
37. 解释MySQL中的聚集索引和非聚集索引的区别。
聚集索引和非聚集索引的主要区别在于数据的存储方式:
- 聚集索引:表数据按照索引的顺序物理存储。每个表只能有一个聚集索引,通常是主键。
- 非聚集索引:索引存储的是数据的逻辑顺序,而数据本身则存储在表的其他地方。非聚集索引可以有多个。
38. 在MySQL中,什么是预处理语句,它有什么优点?
预处理语句是预编译的SQL语句,可以执行参数化的查询。使用预处理语句的优点包括:
- 提高性能:减少解析和编译的时间。
- 防止SQL注入:通过参数化查询,防止恶意输入。
- 减少带宽使用:重复执行相同的查询时,只发送参数。
39. MySQL中的FOREIGN KEY约束是什么?
FOREIGN KEY约束用于建立两个表之间的关联。它确保一个表中的列值必须在另一个表的主键或唯一键列中存在。这有助于维护数据的完整性和一致性。例如:
CREATE TABLE Orders (
OrderID int NOT NULL,
OrderNumber int NOT NULL,
CustomerID int,
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);
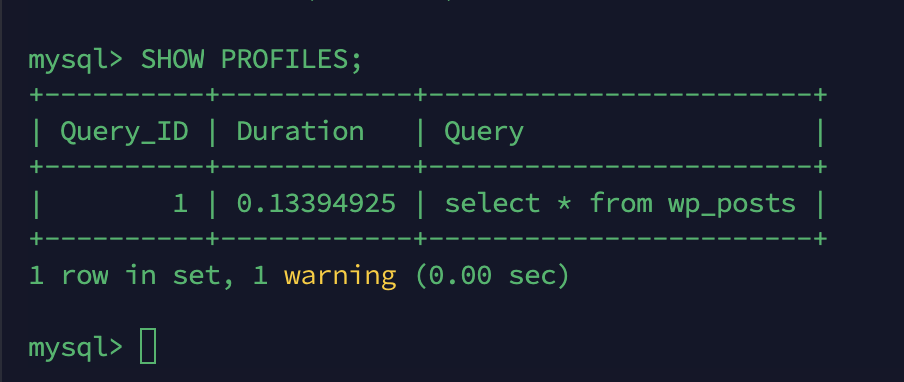
40. 如何在MySQL中进行性能剖析?
在MySQL中进行性能剖析的步骤包括:
- 开启性能剖析:使用
SET profiling = 1;。 - 执行需要剖析的SQL语句。
- 使用
SHOW PROFILES;查看性能数据。 - 使用
SHOW PROFILE FOR QUERY query_id;查看特定查询的详细性能数据。
性能剖析有助于识别查询的瓶颈,如CPU使用、I/O操作等。
41. 什么是MySQL的查询缓存,它是如何工作的?
MySQL的查询缓存是一个存储查询语句及其结果的内存区域。当执行相同的查询时,如果查询缓存中存在结果,MySQL会直接返回缓存的结果,而不是再次执行查询。查询缓存的有效性受多个因素影响,包括表的更改。在高更新环境中,查询缓存可能不会带来性能提升。
42. 解释MySQL的表分区以及它的优势。
表分区是将一个表的数据分散存储在多个物理部分,但逻辑上仍然是一个表的过程。分区的优势包括:
- 提高查询性能,特别是对大表的查询。
- 分区可以分布在不同的物理设备上,提高I/O性能。
- 简化数据管理,例如更容易删除旧数据。
分区类型包括范围、列表、散列和键分区。
43. MySQL的B树索引和哈希索引有什么区别?
B树索引和哈希索引的主要区别在于结构和应用场景:
- B树索引:适用于全键值、键值范围或键值前缀的查找。在MySQL中,大多数索引(如InnoDB的主键和二级索引)是B树索引。
- 哈希索引:适用于精确匹配查找。哈希索引在内存数据库和某些特定类型的存储引擎(如MEMORY)中更常见。
44. 什么是MySQL的慢查询日志,如何配置和使用它?
MySQL的慢查询日志是记录执行时间超过特定阈值的查询的日志文件。配置慢查询日志的步骤包括:
- 在MySQL配置文件中设置
slow_query_log和long_query_time。 - 指定日志文件的路径。
- 重新启动MySQL服务使配置生效。
- 使用日志文件进行性能分析,找出需要优化的查询。
45. MySQL如何处理大数据量的导入和导出?
处理大数据量导入和导出的策略包括:
- 使用
LOAD DATA INFILE进行高效数据导入。 - 使用
SELECT ... INTO OUTFILE进行数据导出。 - 考虑禁用索引和外键约束以加速导入过程。
- 使用
mysqldump进行大型数据库的备份和恢复。 - 分割大文件,进行分批导入或导出。
这些方法可以帮助管理大型数据集,提高数据导入和导出的效率。
46. MySQL的复制延迟是什么,如何解决?
复制延迟是指在MySQL主从复制环境中,从服务器同步主服务器数据的延迟。解决复制延迟的方法包括:
- 提高从服务器的硬件性能。
- 优化网络连接以减少数据传输时间。
- 使用并行复制,如果从服务器是MySQL 5.6或更高版本。
- 调整或减少长时间运行的复杂查询。
47. 如何在MySQL中使用变量?
在MySQL中,可以使用用户定义变量存储临时值。例如:
SET @myVar = 100;
SELECT @myVar;
这将声明一个变量myVar并将其值设置为100。
48. 解释MySQL中的视图锁定。
视图锁定是指在使用视图时,MySQL如何锁定底层表的数据。视图本身不存储数据,而是显示从底层表中检索的数据。因此,对视图的查询可能会导致对底层表的行或表锁定,这取决于查询类型和存储引擎。
49. MySQL如何优化DISTINCT查询?
DISTINCT查询用于返回唯一不同的值。优化DISTINCT查询的方法包括:
- 使用索引,特别是查询的列上有索引的情况。
- 避免在大表上使用
DISTINCT,因为它需要对结果集进行排序和去重。 - 在可能的情况下,使用
GROUP BY替代DISTINCT。
最近无意间获得一份阿里大佬写的刷题笔记和面经,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的阿里大佬写的刷题笔记,让我offer拿到手软
50. MySQL中的GTID复制是什么?
GTID(全局事务标识符)复制是MySQL中的一种复制机制,其中每个事务都有一个唯一的标识符。GTID复制简化了复制过程的管理,因为它使从服务器能够自动跟踪哪些事务已经被复制。这有助于自动故障切换和简化复制配置。
51. 解释MySQL中的LAST_INSERT_ID()函数及其用途。
LAST_INSERT_ID()函数在MySQL中用于检索最后一个INSERT操作产生的自增主键值。这在插入记录后需要获取新生成的ID时非常有用,尤其是在关联表之间插入数据时。例如,插入一条记录到users表后:
INSERT INTO users (username) VALUES (‘johndoe’);
SELECT LAST_INSERT_ID();
这将返回users表中新插入行的ID。
52. MySQL中的索引合并是什么?
索引合并是MySQL的一个优化技术,它在执行查询时可以使用多个索引。在某些情况下,MySQL优化器会选择使用多个单列索引的组合来优化查询,而不是单个复合索引。这通常发生在使用OR条件的查询中。
53. MySQL中如何实现主键和索引的重新设计?
重新设计主键和索引通常涉及以下步骤:
- 使用
ALTER TABLE命令更改表结构。 - 考虑到性能影响,可能需要在低峰时间进行。
- 在重新设计之前,通过建立临时表进行测试。
- 更新应用程序中相关的SQL语句。
这是一个敏感操作,需要谨慎处理,以避免数据完整性问题。
54. 什么是MySQL的联合索引,如何正确使用?
联合索引(或复合索引)是在两个或多个列上创建的索引。正确使用联合索引的关键是理解“最左前缀”原则,即MySQL在联合索引中从左至右使用索引列。创建和使用联合索引时,应确保查询条件匹配索引列的前缀。
55. MySQL中的隐式类型转换可能导致的问题是什么?
MySQL在执行查询时可能会进行隐式类型转换,这可能导致性能问题和意外的行为。例如,将字符串类型的列与数值进行比较时,MySQL可能会尝试将字符串转换为数值。这不仅可能导致性能下降(因为避免了索引的使用),还可能导致错误的比较结果。
56. 如何在MySQL中处理大量的DELETE操作?
处理大量的DELETE操作时,应考虑以下方法以提高效率并减少对性能的影响:
- 分批删除:将大型删除操作分成多个小批量操作,以减少对数据库性能的影响。
- 使用索引:确保删除操作涉及的列上有合适的索引,以加快查找速度。
- 考虑使用TRUNCATE:如果需要删除表中的所有行,使用
TRUNCATE TABLE而不是DELETE,因为它更快且使用更少的资源。 - 考虑归档数据:如果不需要频繁访问被删除的数据,可以先将其归档到另一个表或文件中。
57. MySQL中的EXPLAIN命令提供哪些关键信息?
EXPLAIN命令提供了关于MySQL如何执行查询的详细信息,包括:
- type:显示连接类型,如
ALL,index,range等。 - possible_keys:显示MySQL可能使用的索引来优化查询。
- key:实际使用的索引。
- rows:预计要检查的行数。
- Extra:其他重要信息,如是否使用临时表或文件排序。

58. 在MySQL中,什么是SQL注入,如何防止它?
SQL注入是一种安全漏洞,攻击者可以利用它向数据库查询注入恶意SQL代码。防止SQL注入的措施包括:
- 使用预处理语句和参数化查询:这些技术可以确保SQL语句的结构不被用户输入的数据所改变。
- 验证和清理用户输入:确保所有输入数据都经过适当的验证和转义。
- 使用最小权限原则:确保应用程序使用的数据库账户只拥有它需要的最小权限。
59. 解释MySQL中的数据库锁和表锁。
数据库锁和表锁是MySQL用来控制并发访问的机制:
- 数据库锁:用于控制对数据库级别操作的并发访问。
- 表锁:锁定整个表,防止其他用户对表执行写操作。表锁适用于一些存储引擎,如MyISAM,但对于支持行级锁的InnoDB来说,通常不是最优选择。
60. MySQL中的IN和EXISTS子句有什么区别,它们如何影响性能?
IN和EXISTS是两种用于编写子查询的SQL子句,它们在某些情况下可以互换使用,但性能可能有差异:
- IN子句:适用于外部查询的结果集较小的情况。
- EXISTS子句:通常在内部查询返回非常大的结果集时更高效,因为它一旦找到匹配的行就会停止处理。
性能差异主要是由于MySQL处理这两种子句的方式不同。通常,EXISTS在处理存在性检查时更高效。
61. 什么是MySQL的HAVING子句和WHERE子句的区别?
HAVING子句和WHERE子句都用于过滤数据,但它们的应用场景和时机不同:
- WHERE子句:用于过滤行数据,发生在数据分组之前。它不能与聚合函数一起使用。
- HAVING子句:用于过滤分组后的数据集,通常与聚合函数一起使用。
例如,筛选平均工资大于某个值的部门:
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
HAVING AVG(salary) > 5000;
62. MySQL是如何处理子查询的?
MySQL处理子查询的方式取决于子查询的类型和上下文。子查询可以是标量子查询(返回单一值)、行子查询(返回一行多列)或表子查询(返回一个完整的结果集)。MySQL可能会将某些类型的子查询优化为更有效的结构,如将IN子查询转换为JOIN操作。
63. 解释MySQL的临时表和它们的用途。
MySQL中的临时表是为单个会话创建的,并在该会话结束时自动删除。临时表在处理复杂查询(如多步聚合或中间结果存储)时非常有用。它们对其他用户是不可见的,可以避免对正常操作造成干扰。
64. MySQL的字符集和排序规则有什么重要性?
字符集(Charset)和排序规则(Collation)在MySQL中非常重要,因为它们决定了数据如何存储、比较和排序。字符集定义了支持的字符集合,而排序规则定义了字符之间比较的规则。选择合适的字符集和排序规则对于国际化支持和性能都至关重要。
65. 在MySQL中,如何处理和优化大型报告查询?
处理和优化大型报告查询通常涉及以下策略:
- 使用汇总表:预先计算并存储常见报告查询的结果。
- 查询优化:确保使用有效的索引,优化查询逻辑。
- 分批处理:将大型查询分解为多个小查询,逐步构建最终结果。
- 读取优化:在主从复制环境中,从从服务器读取数据以减轻主服务器负担。
- 硬件优化:确保有足够的内存和高效的存储来处理大型数据集。
这些方法有助于提高大型报告查询的性能,确保数据的准确和及时获取。
66. 什么是MySQL中的分布式事务?
分布式事务是指跨多个数据库系统进行的事务,其中每个系统都需要执行事务的一部分,且所有部分必须协调完成以确保整体事务的原子性。在MySQL中,分布式事务通常通过XA事务实现,它允许多个数据库资源参与到一个全局事务中。
67. 如何在MySQL中实现数据压缩?
在MySQL中,可以通过几种方式实现数据压缩:
- 使用压缩表的存储引擎,如InnoDB的压缩表特性。
- 在应用层对大型文本或二进制数据进行压缩后存储。
- 使用文件系统级别的压缩功能,例如ZFS或Btrfs。
数据压缩有助于减少存储空间的使用,提高I/O效率。
68. 在MySQL中,FLUSH命令的作用是什么?
FLUSH命令在MySQL中用于清理、刷新或重置各种内部缓存及日志。常见的使用包括:
FLUSH TABLES:关闭所有打开的表并清除表缓存。FLUSH LOGS:关闭并重新打开所有日志文件。FLUSH PRIVILEGES:重新加载授权表。
使用FLUSH命令时需要谨慎,因为它可能会影响数据库的性能。
69. 什么是MySQL中的空间数据类型,它们的用途是什么?
空间数据类型用于存储地理空间数据,如点、线和多边形。在MySQL中,这些类型包括GEOMETRY, POINT, LINESTRING, POLYGON等。它们主要用于地理信息系统(GIS)中,用于表示地图、地理位置和空间关系。
70. 如何在MySQL中处理和优化长时间运行的查询?
处理和优化长时间运行的查询的策略包括:
- 查询分析:使用
EXPLAIN或其他工具分析查询执行计划。 - 索引优化:确保查询使用了正确的索引。
- 查询重写:修改复杂的查询逻辑,简化或分解查询。
- 资源调整:增加内存分配,调整MySQL配置以优化性能。
- 硬件升级:在必要时升级服务器硬件。
这些方法有助于减少查询执行时间,提高数据库的整体性能。
71. 如何在MySQL中使用和优化子查询?
子查询是嵌套在另一个查询内部的查询。优化子查询的策略包括:
- 尽可能将子查询转换为联接,特别是在子查询返回大量数据时。
- 确保子查询中的列有适当的索引。
- 避免在子查询中使用非必要的排序和分组操作。
- 使用EXISTS而不是IN来检查存在性,尤其是当外部查询的数据量大时。
72. MySQL如何处理NULL值,对性能有什么影响?
MySQL中的NULL表示缺失或未知的数据。处理NULL值时需要注意:
- 索引通常不包括NULL值,因此包含NULL值的列上的查询可能不会使用索引。
- 在比较操作中,任何与NULL值的比较都会返回NULL(即未知),这可能影响查询逻辑。
- 使用适当的函数(如
COALESCE或IS NULL)来处理NULL值。
73. 什么是MySQL的分区索引,它如何影响查询性能?
分区索引是与表分区一起使用的索引。在分区表上,每个分区可以拥有自己的索引。这对查询性能有如下影响:
- 查询可以限制在特定的分区上,从而减少搜索的数据量。
- 索引维护(如重建索引)可以在单个分区上进行,而不是整个表。
- 但是,错误设计的分区或索引可能导致性能下降,因为MySQL可能需要检查多个分区。
74. MySQL中的索引前缀是什么,如何使用?
索引前缀是在列的一部分上创建索引的方法。对于文本类型的列特别有用,可以通过对列值的前N个字符创建索引来提高查询性能。使用索引前缀时应注意:
- 确定合适的前缀长度,过长或过短的前缀都可能影响索引效率。
- 索引前缀最适合用于字符串类型的列,特别是当完整列的索引可能非常大时。
75. 如何在MySQL中使用视图来优化查询?
在MySQL中,视图可以用来简化复杂的查询,封装复杂的联接和子查询。使用视图的优点包括:
- 提高查询的可读性和维护性。
- 重用常见的查询逻辑。
- 提供额外的安全层,限制对底层表数据的访问。
然而,应注意视图本身并不存储数据,其性能取决于底层查询的效率。
76. MySQL中的优化器提示是什么,如何使用?
优化器提示(Optimizer Hints)是一种告诉MySQL优化器如何处理特定查询的方式。它们可以用来影响查询计划的选择,例如指定或忽略特定的索引。例如,使用USE INDEX或IGNORE INDEX提示指定或排除索引:
SELECT * FROM table_name USE INDEX (index_name) WHERE column_name = ‘value’;
77. 解释MySQL的读写锁定机制。
MySQL中的读写锁定机制是用来控制对数据的并发访问:
- 读锁(共享锁):允许多个事务同时读取同一数据,但不允许写入。
- 写锁(排他锁):当事务对数据进行写操作时,阻止其他事务读取或写入同一数据。
合理使用读写锁可以提高并发性能,但也需要谨慎处理,以避免死锁。
78. 在MySQL中,如何处理和分析死锁?
处理和分析死锁的方法包括:
- 启用死锁日志,通过
SHOW ENGINE INNODB STATUS;查看死锁信息。 - 分析死锁日志来理解造成死锁的事务和操作。
- 修改应用逻辑,减少长时间持有锁的操作,或改变事务的锁定顺序。
合理处理死锁对于维护数据库的稳定性和性能非常重要。
79. MySQL中的LIMIT子句是如何工作的,对性能有什么影响?
LIMIT子句用于限制SQL查询返回的结果数量。它对性能的影响取决于查询的上下文:
- 在有索引且只需返回少量行的情况下,
LIMIT可以显著提高性能。 - 但是,如果
LIMIT后面的偏移量很大,MySQL可能需要读取大量不需要的行然后丢弃,这可能导致性能问题。
80. 如何在MySQL中处理和避免全表扫描?
避免全表扫描的方法包括:
- 使用索引优化查询,确保查询条件利用了有效的索引。
- 重写查询,避免使用会导致全表扫描的操作,如不安全的函数或类型不匹配的比较。
- 在执行计划中使用
EXPLAIN分析查询,查看是否进行了全表扫描。 - 调整数据库设计,如添加必要的索引,或修改表结构以提高查询效率。
避免全表扫描对于维护大型数据库的性能至关重要。
最近无意间获得一份阿里大佬写的刷题笔记和面经,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的阿里大佬写的刷题笔记,让我offer拿到手软
81. MySQL中的表空间是什么,它的作用是什么?
表空间(Tablespace)是MySQL中存储数据的物理单位。在InnoDB存储引擎中,表空间可以用于存储表数据、索引和撤销日志。使用表空间,可以更好地管理磁盘空间,支持大型数据库,以及进行更高效的数据恢复。
82. MySQL的视图优化技巧有哪些?
优化MySQL视图的技巧包括:
- 避免在视图中使用复杂的SQL查询和计算。
- 使用索引支持视图中的查询条件。
- 适当地使用物化视图或汇总表以提高性能。
- 定期评估视图的性能,并根据需要调整底层查询。
83. 在MySQL中,如何优化ORDER BY查询?
优化ORDER BY查询的方法包括:
- 确保排序操作所依赖的列上有索引。
- 尽量减少需要排序的数据量,例如先过滤出需要的行,然后再排序。
- 避免使用不必要的复杂表达式和函数在
ORDER BY子句中。
84. 如何在MySQL中进行批量插入数据,并优化性能?
进行批量插入数据时,可以采取以下措施以优化性能:
- 使用
INSERT INTO ... VALUES语句一次插入多行数据。 - 禁用索引和外键约束,直到数据插入完成。
- 考虑在插入过程中禁用自动提交,使用事务来管理插入。
85. MySQL中的分布式架构和复制策略有哪些?
MySQL的分布式架构和复制策略包括:
- 主从复制:数据从主服务器复制到一个或多个从服务器。
- 主主复制:两个服务器相互复制数据,提供读写能力。
- 群集复制:MySQL群集提供高可用性和故障转移能力。
- 延迟复制:在从服务器上设置复制延迟,用于灾难恢复。
每种策略都有其用途和优势,应根据具体需求和环境选择合适的方案。
86. MySQL中的触发器和存储过程有什么不同?
触发器和存储过程都是在MySQL中执行预定义操作的数据库对象,但它们的使用场景和目的不同:
- 触发器(Trigger):自动响应特定事件(如插入、更新或删除)的数据库对象。触发器隐藏在应用层之后,对用户不可见。
- 存储过程(Stored Procedure):可以手动调用执行的一组SQL语句。用于封装复杂的业务逻辑。
87. 如何在MySQL中优化大型JOIN操作?
优化大型JOIN操作的策略包括:
- 确保JOIN操作中的每个表都有适当的索引。
- 考虑表的大小和行数,合理安排JOIN顺序。
- 使用
EXPLAIN分析JOIN查询,确保效率。 - 对于非常大的表,考虑分批处理或使用临时表。
88. MySQL中的窗口函数是什么,如何使用它们?
窗口函数是MySQL 8.0引入的一项功能,允许对数据集的子集执行计算,如排名、行号、分区内聚合等。例如,使用ROW_NUMBER()窗口函数为每个部门的员工分配一个唯一的序号:
SELECT department_id, employee_id, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY employee_id) AS row_num
FROM employees;
89. 在MySQL中如何处理和优化大型UPDATE操作?
处理和优化大型UPDATE操作的方法包括:
- 分批进行UPDATE操作,避免一次性处理过多行。
- 在涉及的列上使用适当的索引。
- 更新操作前,使用
SELECT语句测试和优化WHERE子句。 - 在执行UPDATE操作期间,监控性能指标,确保系统稳定。
90. MySQL中的二级索引是什么?
二级索引(Secondary Index)是除了主键索引以外的索引。在InnoDB存储引擎中,二级索引的叶节点包含索引字段和相应行的主键值。这意味着二级索引查询可能需要两次查找:首先在二级索引中查找,然后使用找到的主键在主键索引中查找实际的行数据。
91. 在MySQL中,什么是视图的物化?
物化视图不是MySQL的标准特性,但概念上,它指的是将视图的结果集存储为实体数据。这可以通过创建一个表来手动实现,该表的内容是视图查询的输出。物化视图对于提高复杂查询的性能非常有用,尤其是当底层数据不经常更改时。
92. 如何在MySQL中处理BLOB和CLOB数据类型?
BLOB(二进制大对象)和CLOB(字符大对象)用于存储大量数据,如图像或文本文件。处理这些类型时的最佳实践包括:
- 仅在必要时使用BLOB和CLOB类型,因为它们可能会占用大量空间和内存。
- 考虑数据的压缩和编码,以减少存储和传输的数据量。
- 在应用层处理大对象的读取和写入,以减轻数据库服务器的负担。
93. MySQL中的多版本并发控制(MVCC)是什么?
多版本并发控制(MVCC)是一种用于提高数据库系统并发性能的技术。在MySQL的InnoDB存储引擎中,MVCC允许读取操作在不加锁的情况下进行,即使其他事务正在修改数据。这通过保留数据的不同版本来实现,使读取操作可以访问数据的早期版本。
94. 如何在MySQL中使用和管理索引?
使用和管理MySQL中的索引涉及:
- 为常用的查询和排序列创建索引。
- 定期使用
OPTIMIZE TABLE命令或类似工具维护和重新组织索引。 - 使用
EXPLAIN分析查询的执行计划,确保索引被有效利用。 - 避免过度索引,因为太多索引可能会减慢写操作。
95. 在MySQL中,如何确保数据的完整性和一致性?
确保数据的完整性和一致性的方法包括:
- 使用事务来维护操作的原子性、一致性、隔离性和持久性。
- 使用外键约束来维护表之间的关系和数据完整性。
- 使用合适的数据类型和约束(如NOT NULL、UNIQUE)来确保数据准确性。
- 定期检查和修复数据库,使用诸如
CHECK TABLE和REPAIR TABLE的命令。
96. 如何在MySQL中实现和管理分布式数据库?
在MySQL中实现分布式数据库通常涉及以下策略:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
并发性能的技术。在MySQL的InnoDB存储引擎中,MVCC允许读取操作在不加锁的情况下进行,即使其他事务正在修改数据。这通过保留数据的不同版本来实现,使读取操作可以访问数据的早期版本。
94. 如何在MySQL中使用和管理索引?
使用和管理MySQL中的索引涉及:
- 为常用的查询和排序列创建索引。
- 定期使用
OPTIMIZE TABLE命令或类似工具维护和重新组织索引。 - 使用
EXPLAIN分析查询的执行计划,确保索引被有效利用。 - 避免过度索引,因为太多索引可能会减慢写操作。
95. 在MySQL中,如何确保数据的完整性和一致性?
确保数据的完整性和一致性的方法包括:
- 使用事务来维护操作的原子性、一致性、隔离性和持久性。
- 使用外键约束来维护表之间的关系和数据完整性。
- 使用合适的数据类型和约束(如NOT NULL、UNIQUE)来确保数据准确性。
- 定期检查和修复数据库,使用诸如
CHECK TABLE和REPAIR TABLE的命令。
96. 如何在MySQL中实现和管理分布式数据库?
在MySQL中实现分布式数据库通常涉及以下策略:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Go)
[外链图片转存中…(img-nrkpd8V8-1713267065098)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 111
111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









