







 本文讨论了马斯克的独特管理风格,以及深度学习模型TiledDiffusion在图像生成中的应用,包括其工作原理和训练过程。同时,文章介绍了如何利用这些技术进行图像升级和超大尺寸图像生成,以及AIGC技术的前景和学习资源。
本文讨论了马斯克的独特管理风格,以及深度学习模型TiledDiffusion在图像生成中的应用,包括其工作原理和训练过程。同时,文章介绍了如何利用这些技术进行图像升级和超大尺寸图像生成,以及AIGC技术的前景和学习资源。
今日言论:
马斯克的管理风格非常独特,他不需要非技术性的中层管理人员,员工表现不佳就会被裁,也不喜欢大型会议。
-- 前特斯拉 AI 总监安德烈·卡帕西
深入解读:Tiled Diffusion,英文翻译为**平铺扩散,**也是一种深度学习模型。
它主要用于图像生成任务。这种模型基于扩散过程,通过逐渐向图像中引入噪声,然后通过一个生成网络逐步恢复出清晰的图像。Tiled Diffusion模型将图像分成多个小块(即“瓦片”),并在每个瓦片中独立地执行扩散和生成过程,从而允许模型更有效地处理大型图像。
具体来说,Tiled Diffusion模型的训练分为两个阶段:
-
正向扩散过程(Forward Diffusion):在这个过程中,模型逐步地将图像数据转换为一个高斯噪声状态。这个过程通常包括多个步骤,每个步骤都涉及到对图像的逐步扰动。
-
反向生成过程(Backward Generation):在正向扩散过程之后,模型需要通过一个生成网络将高斯噪声转换回原始的图像数据。在Tiled Diffusion中,这个过程在每个瓦片上是独立进行的,这使得模型能够并行处理不同瓦片,从而提高了训练和推理的效率。
浅出解读:
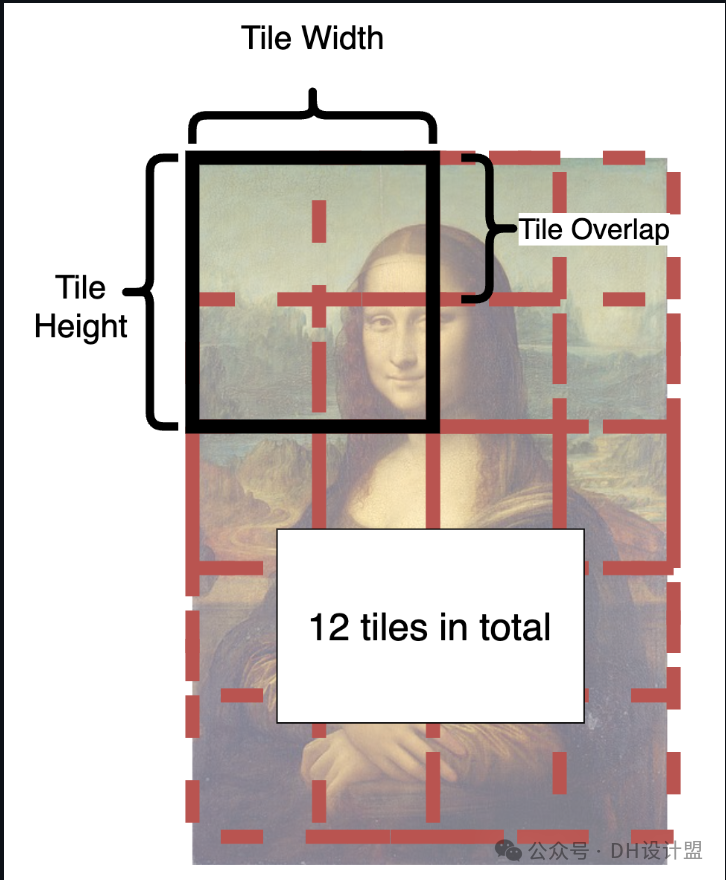
图片来源:Technical Part · pkuliyi2015/multidiffusion-upscaler-for-automatic1111 Wiki · GitHub
这个图表示的其实是重绘放大的意思。核心技术是通过Tiled VAE插件降低了现存的消耗能力,让显卡更好的发挥其威力。(double双押!)
**关于安装:**一般秋叶大神的安装包是自带的,没有可以在扩展程序里面找到。
实用解读:
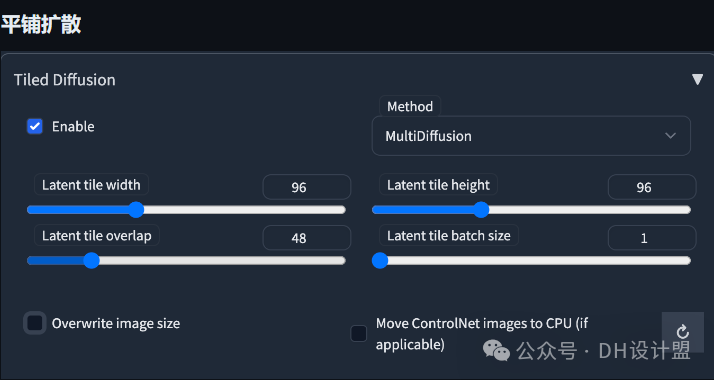
-
从图中,您可以看到如何将图像拆分为图块
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









