







给大家的福利
零基础入门
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
网络安全面试题
绿盟护网行动
还有大家最喜欢的黑客技术
网络安全源码合集+工具包

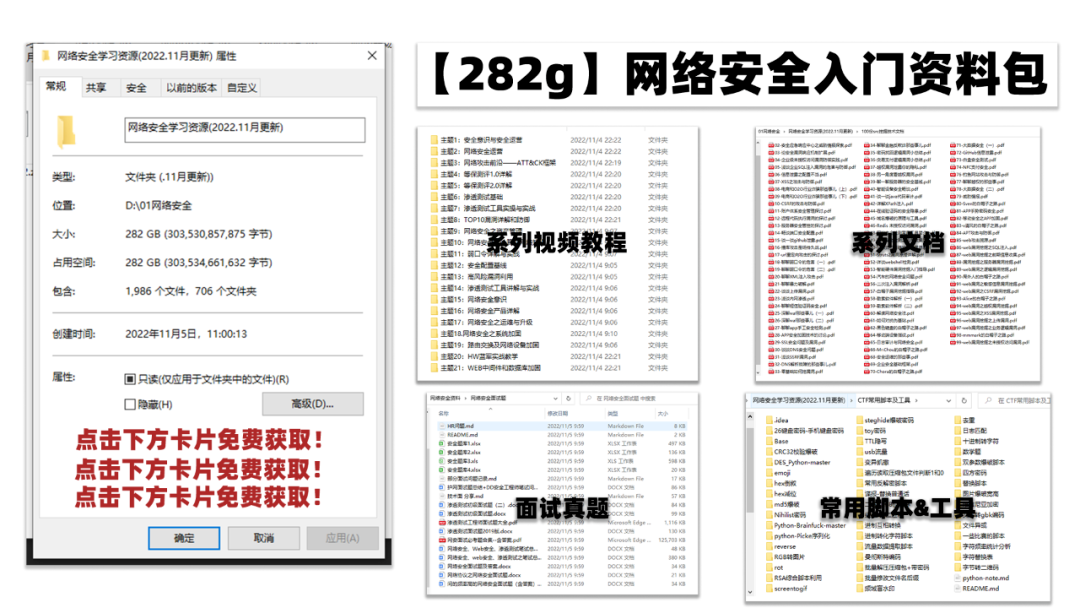
所有资料共282G,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
数据采集
数据来源分为内部数据和外部数据,内部数据主要是企业数据库里的数据,外部数据主要是下载一些公开数据取或利用网络爬虫获取。(如果数据分析仅对内部数据做处理,那么这个步骤可以忽略。)
公开的数据集我们直接下载即可,所以这部分的重点知识内容是网络爬虫。那么我们必须掌握的技能有Python 基础语法、如何编写 Python 爬虫。
Python 基础语法:掌握元素(列表、字典、元组等)、变量、循环、函数等基础知识,达到能够熟练编写代码,至少不能出现语法错误。
Python 爬虫内容:掌握如何使用成熟的 Python 库(如urllib、BeautifulSoup、requests、scrapy)实现网络爬虫。
大部分的网站都有自己的反爬机制,所以还需要学习一些技巧去应对不同网站的反爬策略。主要包括:正则表达式、模拟用户登录、使用代理、设置爬取频率、使用cookie信息等等。
三大板块:
- 两组Python基础术语
- 如何实现爬虫
- 如何做数据分析
1.两大Python基础术语
A.变量和赋值
Python可以直接定义变量名字并进行赋值的,例如我们写出a = 4时,Python解释器干了两件事情:
- 在内存中创建了一个值为4的整型数据
- 在内存中创建了一个名为a的变量,并把它指向4
用一张示意图表示Python变量和赋值的重点:
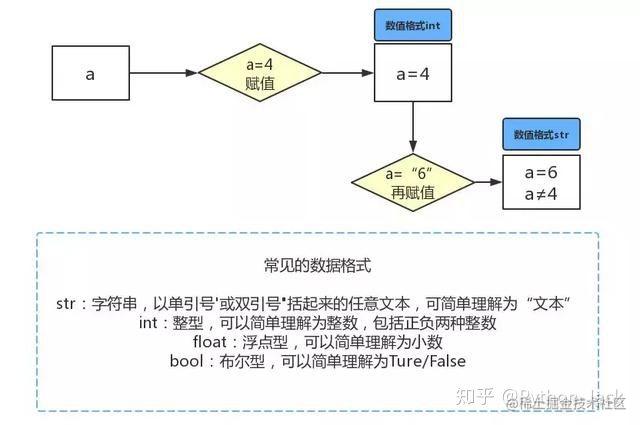
例如下图代码,“=”的作用就是赋值,同时Python会自动识别数据类型:
a=4 #整型数据
b=2 #整型数据
c=“4” #字符串数据
d=“2” #字符串数据
print(“a+b结果为”,a+b)#两个整数相加,结果是6
print(“c+d结果为”,c+d)#两个文本合并,结果是文本“42”
#以下为运行结果
>>>a+b结果为 6
>>>c+d结果为 42
复制代码
请阅读代码块里的代码和注释,你会发现Python是及其易读易懂的。
B.数据类型
在初级的数据分析过程中,有三种数据类型是很常见的:
- 列表list(Python内置)
- 字典dic(Python内置)
- DataFrame(工具包pandas下的数据类型,需要import pandas才能调用)
它们分别是这么写的:
列表(list):
#列表
liebiao=[1,2.223,-3,'刘强东','章泽天','周杰伦','昆凌',['微博','B站','抖音']]
复制代码
list是一种有序的集合,里面的元素可以是之前提到的任何一种数据格式和数据类型(整型、浮点、列表……),
并可以随时指定顺序添加其中的元素,其形式是:
#ist是一个可变的有序表,所以,可以往list中追加元素到末尾:
liebiao.append('瘦')
ptint(liebiao)
#结果1
>>>[1, 2.223, -3, '刘强东', '章泽天', '周杰伦', '昆凌', ['微博', 'B站', '抖音'], '瘦']
#也可以把元素插入到指定的位置,比如索引号为5的位置,插入“胖”这个元素:
liebiao.insert(5, '胖')
ptint(liebiao)
#结果2
>>>[1, 2.223, -3, '刘强东', '章泽天', '胖', '周杰伦', '昆凌', ['微博', 'B站', '抖音'], '瘦']
复制代码
字典(dict):
#字典
zidian={'刘强东':'46','章泽天':'36','周杰伦':'40','昆凌':'26'}
复制代码
字典使用**键-值(key-value)**存储,无序,具有极快的查找速度。以上面的字典为例,想要快速知道周杰伦的年龄,
就可以这么写:
zidian['周杰伦']
>>>'40'
复制代码
dict内部存放的顺序和key放入的顺序是没有关系的,也就是说,"章泽天"并非是在"刘强东"的后面。
DataFrame:
DataFrame可以简单理解为excel里的表格格式。导入pandas包后,字典和列表都可以转化为DataFrame,
以上面的字典为例,转化为DataFrame是这样的:
import pandas as pd
df=pd.DataFrame.from_dict(zidian,orient='index',columns=['age'])#注意DataFrame的D和F是大写
df=df.reset_index().rename(columns={'index':'name'})#给姓名加上字段名
复制代码
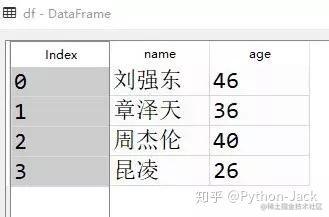
和excel一样,DataFrame的任何一列或任何一行都可以单独选出进行分析。
是不是有很多东西在学Python新手入门教程的时候不懂的,在这里悟了一些呢!
以上三种数据类型是python数据分析中用的最多的类型,基础语法到此结束,接下来就可以着手写一些函数计算数据了。
2.从Python爬虫来学循环函数
掌握了以上基本语法概念,我们就足以开始学习一些有趣的函数。我们以爬虫中绕不开的遍历url为例,讲讲大家最难理解的循环函数for的用法:
- for函数
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









