







} } //查找红黑树中的某个节点
final Node<K,V> find(int h, Object k) { if (k != null) {
for (Node<K,V> e = first; e != null; ) {
int s; K ek; //如果当前有waiter或者有写锁,走线性检索,因为红黑树虽然替代了链表,但其内部依然保留了链表的结构,虽然链表的查询性能一般,但根据先前的分析其读取的安全性有保证。
//发现有写锁改走线性检索,是为了避免等待写锁释放花去太久时间; 而发现有waiter改走线性检索,是为了避免读锁叠加的太多,导致写锁线程需要等待太长的时间; 本质上都是为了减少读写碰撞
//线性遍历的过程中,每遍历到下一个节点都做一次判断,一旦发现锁竞争的可能性减少就改走tree检索以提高性能
if (((s = lockState) & (WAITER|WRITER)) != 0) {
if (e.hash == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
e = e.next; } //对红黑树加共享锁,也就是读锁,CAS一次性增加4,也就是增加的只是3~32位
else if (U.compareAndSetInt(this, LOCKSTATE, s,
s + READER)) { TreeNode<K,V> r, p; try {
p = ((r = root) == null ? null :
r.findTreeNode(h, k, null));
} finally {
Thread w; //释放读锁,如果释放完毕且有waiter,则将其唤醒
if (U.getAndAddInt(this, LOCKSTATE, -READER) ==
(READER|WAITER) && (w = waiter) != null)
LockSupport.unpark(w); } return p;
} } } return null;
} //更新红黑树中的某个节点
final TreeNode<K,V> putTreeVal(int h, K k, V v) { Class<?> kc = null;
boolean searched = false;
for (TreeNode<K,V> p = root;😉 {
int dir, ph; K pk; //…省略处理红黑树数据结构的代码若干
else {
//写操作前加互斥锁
lockRoot(); try {
root = balanceInsertion(root, x); } finally {
//释放互斥锁
unlockRoot(); } } break;
} } assert checkInvariants(root); return null;
}}
红黑树内置了一套读写锁的逻辑,其内部定义了32位的int型变量lockState,第1位是写锁标志位,第2位是写锁等待标志位,从3~32位则是共享锁标志位。
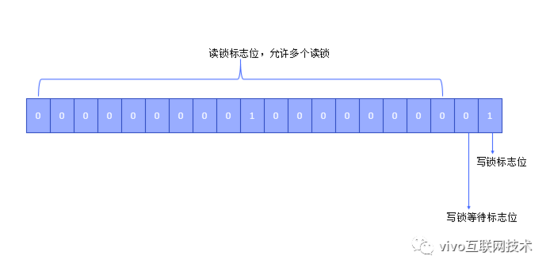
读写操作是互斥的,允许多个线程同时读取,但不允许读写操作并行,同一时刻只允许一个线程进行写操作;这样任意时间点读取的都是一个合法的红黑树,整体上是安全的。
有的同学会产生疑惑,写锁释放时为何没有将waiter唤醒的操作呢?是否有可能A线程进入了等待区,B线程获取了写锁,释放写锁时仅做了lockState=0的操作。
那么A线程是否就没有机会被唤醒了,只有等待下一个读锁释放时的唤醒了呢 ?
显然这种情况违背常理,C13Map不会出现这样的疏漏,在进一步观察,红黑树的变更操作的范围,也就是在putValue/replaceNode那一层,都是对BIN的头节点加了synchornized互斥锁的,同一时刻只能有一个写线程进入TreeBin的方法范围内,当写线程发现当前waiter不为空,其实此waiter只能是当前线程自己,可以放心的获取解锁,不用担心无法被唤醒的问题。
TreeBin在find读操作检索时,在linearSearch(线性检索)和treeSearch(树检索)间做了折衷,前者性能差但并发安全,后者性能佳但要做并发控制,可能导致锁竞争;设计者使用线性检索来尽量避免读写碰撞导致的锁竞争,但评估到race condition已消失时,又立即趋向于改用树检索来提高性能,在安全和性能之间做到了极佳的平衡。具体的折衷策略请参考find方法及注释。
由于有线性检索这样一个抄底方案,以及入口处bin头节点的synchornized机制,保证了进入到TreeBin整体代码块的写线程只有一个;TreeBin中读写锁的整体设计与ReentrantReadWriteLock相比还是简单了不少,比如并未定义用于存放待唤醒线程的threadQueue,以及读线程仅会自旋而不会阻塞等等, 可以看做是特定条件下ReadWriteLock的简化版本。
5、如果读取的bin是一个ForwardingNode
===============================
说明当前bin已迁移,调用其find方法到nextTable读取数据。
forwardingNode的find方法
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null);
this.nextTable = tab;
}
//递归检索哈希表链
Node<K,V> find(int h, Object k) {
// loop to avoid arbitrarily deep recursion on forwarding nodes
outer: for (Node<K,V>[] tab = nextTable;😉 {
Node<K,V> e; int n;
if (k == null || tab == null || (n = tab.length) == 0 ||
(e = tabAt(tab, (n - 1) & h)) == null)
return null;
for (;😉 {
int eh; K ek;
if ((eh = e.hash) == h &&
((ek = e.key) == k || (ek != null && k.equals(ek))))
return e;
if (eh < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable;
continue outer;
}
else
return e.find(h, k);
}
if ((e = e.next) == null)
return null;
}
}
}
}
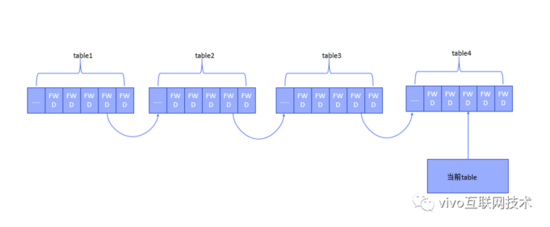
ForwardingNode中保存了nextTable的引用,会转向下一个哈希表进行检索,但并不能保证nextTable就一定是currentTable,因为在高并发插入的情况下,极短时间内就可以导致哈希表的多次扩容,内存中极有可能驻留一条哈希表链,彼此与bin的头节点上的ForwardingNode相连,线程刚读取时拿到的是table1,遍历时却有可能经历了哈希表的链条。
eh<0有三种情况:
-
如果是ForwardingNode继续遍历下一个哈希表。
-
如果是TreeBin,调用其find方法进入TreeBin读写锁的保护区读取数据。
-
如果是ReserveNode,说明当前有compute计算中,整条bin还是一个空结构,直接返回null。
6、如果读取的bin是一个ReserveNode
============================
ReserveNode用于compute/computeIfAbsent原子计算的方法,在BIN的头节点为null且计算尚未完成时,先在bin的头节点打上一个ReserveNode的占位标记。
读操作发现ReserveNode直接返回null,写操作会因为争夺ReserveNode的互斥锁而进入阻塞态,在compute完成后被唤醒后循环重试。
六、写操作putValue/replaceNode为什么是线程安全的
======================================
典型的编程范式如下:
C13Map的putValue方法
Node<K,V>[] tab = table; //将堆中的table变量赋给线程堆栈中的局部变量
Node f = tabAt(tab, i );if(f==null){
//当前槽位没有头节点,直接CAS写入
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break;
}else if(f.hash == MOVED){
//加入协助搬运行列
helpTransfer(tab,f);}//不是forwardingNode
else if(f.hash != MOVED){
//先锁住I槽位上的头节点
synchronized (f) {
//再doubleCheck看此槽位上的头节点是否还是f
if (tabAt(tab, i) == f) {
…各种写操作
}
}
}
1、当前槽位如果头节点为null时,直接CAS写入
=============================
有人也许会质疑,如果写入时resize操作已完成,发生了table向nextTable的转变,是否会存在写入的是旧表的bin导致数据丢失的可能 ?
这种可能性是不存在的,因为一个table在resize完成后所有的BIN都会被打上ForwardingNode的标记,可以形象的理解为所有槽位上都插满了红旗,而此处在CAS时的compare的变量null,能够保证至少在CAS原子操作发生的时间点table并未发生变更。
2、当前槽位如果头节点不为null
=====================
这里采用了一个小技巧:先锁住I槽位上的头节点,进入同步代码块后,再doubleCheck看此槽位上的头节点是否有变化。
进入同步块后还需要doubleCheck的原因:虽然一开始获取到的头节点f并非ForwardingNode,但在获取到f的同步锁之前,可能有其它线程提前获取了f的同步锁并完成了transfer工作,并将I槽位上的头节点标记为ForwardingNode,此时的f就成了一个过时的bin的头节点。
然而因为标记操作与transfer作为一个整体在同步的代码块中执行,如果doubleCheck的结果是此槽位上的头节点还是f,则表明至少在当前时间点该槽位还没有被transfer到新表(假如当前有transfer in progress的话),可以放心的对该bin进行put/remove/replace等写操作。
只要未发生transfer或者treeify操作,链表的新增操作都是采取后入式,头节点一旦确定不会轻易改变,这种后入式的更新方式保证了锁定头节点就等于锁住了整个bin。
如果不作doubleCheck判断,则有可能当前槽位已被transfer,写入的还是旧表的BIN,从而导致写入数据的丢失;也有可能在获取到f的同步锁之前,其它线程对该BIN做了treeify操作,并将头节点替换成了TreeBin, 导致写入的是旧的链表,而非新的红黑树;
3、doubleCheck是否有ABA问题
=========================
也许有人会质疑,如果有其它线程提前对当前bin进行了的remove/put的操作,引入了新的头节点,并且恰好发生了JVM的内存释放和重新分配,导致新的Node的引用地址恰好跟旧的相同,也就是存在所谓的ABA问题。
这个可以通过反证法来推翻,在带有GC机制的语言环境下通常不会发生ABA问题,因为当前线程包含了对头节点f的引用,当前线程并未消亡,不可能存在f节点的内存被GC回收的可能性。
还有人会质疑,如果在写入过程中主哈希表发生了变化,是否可能写入的是旧表的bin导致数据丢失,这个也可以通过反证法来推翻,因为table向nextTable的转化(也就是将resize后的新哈希表正式commit)只有在所有的槽位都已经transfer成功后才会进行,只要有一个bin未transfer成功,则说明当前的table未发生变化,在当前的时间点可以放心的向table的bin内写入数据。
4、如何操作才安全
=============
可以总结出规律,在对table的槽位成功进行了CAS操作且compare值为null,或者对槽位的非forwardingNode的头节点加锁后,doubleCheck头节点未发生变化,对bin的写操作都是安全的。
七、原子计算相关方法
==============
原子计算主要包括:computeIfAbsent、computeIfPresent、compute、merge四个方法。
1、几个方法的比较
=============
主要区别如下:
(1)computeIfAbsent只会在判断到key不存在时才会插入,判空与插入是一个原子操作,提供的FunctionalInterface是一个二元的Function, 接受key参数,返回value结果;如果计算结果为null则不做插入。
(2)computeIfPresent只会在判读单到Key非空时才会做更新,判断非空与插入是一个原子操作,提供的FunctionalInterface是一个三元的BiFunction,接受key,value两个参数,返回新的value结果;如果新的value为null则删除key对应节点。
(3)compute则不加key是否存在的限制,提供的FunctionalInterface是一个三元的BiFunction,接受key,value两个参数,返回新的value结果;如果旧的value不存在则以null替代进行计算;如果新的value为null则保证key对应节点不会存在。
(4)merge不加key是否存在的限制,提供的FunctionalInterface是一个三元的BiFunction,接受oldValue, newVALUE两个参数,返回merge后的value;如果旧的value不存在,直接以newVALUE作为最终结果,存在则返回merge后的结果;如果最终结果为null,则保证key对应节点不会存在。
2、何时会使用ReserveNode占位
========================
如果目标bin的头节点为null,需要写入的话有两种手段:一种是生成好新的节点r后使用casTabAt(tab, i, null, r)原子操作,因为compare的值为null可以保证并发的安全;
另外一种方式是创建一个占位的ReserveNode,锁住该节点并将其CAS设置到bin的头节点,再进行进一步的原子计算操作;这两种办法都有可能在CAS的时候失败,需要自己反复尝试。
(1)为什么只有computeIfAbsent/compute方法使用占位符的方式
=============================================
computeIfPresent只有在BIN结构非空的情况下才会展开原子计算,自然不存在需要ReserveNode占位的情况;锁住已有的头节点即可。
computeIfAbsent/compute方法在BIN结构为空时,需要展开Function或者BiFunction的运算,这个操作是外部引入的需要耗时多久无法准确评估;这种情况下如果采用先计算,再casTabAt(tab, i, null, r)的方式,如果有其它线程提前更新了这个BIN,那么就需要重新锁定新加入的头节点,并重复一次原子计算(C13Map无法帮你缓存上次计算的结果,因为计算的入参有可能会变化),这个开销是比较大的。
而使用ReserveNode占位的方式无需等到原子计算出结果,可以第一时间先抢占BIN的所有权,使其他并发的写线程阻塞。
(2)merge方法为何不需要占位
=====================
原因是如果BIN结构为空时,根据merge的处理策略,老的value为空则直接使用新的value替代,这样就省去了BiFunction中新老value进行merge的计算,这个消耗几乎是没有的;因此可以使用casTabAt(tab, i, null, r)的方式直接修改,避免了使用ReserveNode占位,锁定该占位ReserveNode后再进行CAS修改的两次CAS无谓的开销。
C13Map的compute方法
public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
if (key == null || remappingFunction == null)
throw new nullPointerException();
int h = spread(key.hashCode());
V val = null;
int delta = 0;
int binCount = 0;
for (Node<K, V>[] tab = table; ; ) {
Node<K, V> f;
int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & h)) == null) {
//创建占位Node
Node<K, V> r = new ReservationNode<K, V>();
//先锁定该占位Node
synchronized ® {
//将其设置到BIN的头节点
if (casTabAt(tab, i, null, r)) {
binCount = 1;
Node<K, V> node = null;
try {
//开始原子计算
if ((val = remappingFunction.apply(key, null)) != null) {
delta = 1;
node = new Node<K, V>(h, key, val, null);
}
} finally {
//设置计算后的最终节点
setTabAt(tab, i, node);
}
}
}
if (binCount != 0)
break;
} else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
//此处省略对普通链表的变更操作
} else if (f instanceof TreeBin) {
//此处省略对红黑树的变更操作
}
}
}
}
}
if (delta != 0)
addCount((long) delta, binCount);
return val;
}
3、如何保证原子性
=============
computeIfAbsent/computeIfPresent中判空与计算是原子操作,根据上述分析主要是通过casTabAt(tab, i, null, r)原子操作,或者使用ReserveNode占位并锁定的方式,或者锁住bin的头节点的方式来实现的。
也就是说整个bin一直处于锁定状态,在获取到目标KEY的value是否为空以后,其它线程无法变更目标KEY的值,判空与计算自然是原子的。
而casTabAt(tab, i, null, r)是由硬件层面的原子指令来保证的,能够保证同一个内存区域在compare和set操作之间不会有任何其它指令对其进行变更。
八、resize过程中的并发transfer
==========================
C13Map中总共有三处地方会触发transfer方法的调用,分别是addCount、tryPresize、helpTransfer三个函数。
-
addCount 用于写操作完成后检验元素数量,如果超过了sizeCtl中的阈值,则触发resize扩容和旧表向新表的transfer。
-
tryPresize 是putAll一次性插入一个集合前的自检,如果集合数目较大,则预先触发一次resize扩容和旧表向新表的transfer。
-
helpTransfer 是写操作过程中发现bin的头节点是ForwardingNode, 则调用helpTransfer加入协助搬运的行列。
1、开始transfer前的检查工作
======================
以addCount中的检查逻辑为例:
addCount中的transfer检查
Node<K, V>[] tab, nt;
int n, sc;
//当前的tableSize已经超过sizeCtl阈值,且小于最大值
while (s >= (long) (sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
//已经在搬运中
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
//搬运线程数加一
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
} else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
//尚未搬运,当前线程是本次resize工作的第一个线程,设置初始值为2,非常巧妙的设计
transfer(tab, null);
s = sumCount();
}
多处应用了对变量sizeCtl的CAS操作,sizeCtl是一个全局控制变量。
参考下此变量的定义:private transient volatile int sizeCtl;
-
初始值是0表示哈希表尚未初始化
-
如果是-1表示正在初始化,只允许一个线程进入初始化代码块
-
初始化或者reSize成功后,sizeCtl=loadFactor * tableSize也就是触发再次扩容的阈值,是一个正整数
-
在扩容过程中,sizeCtrl是一个负整数,其高16位是与当前的tableSize关联的邮戳resizeStamp,其低16位是当前从事搬运工作的线程数加1
在方法的循环体中每次都将table、sizeCtrl、nextTable赋给局部变量以保证读到的是当前的最新值,且保证逻辑计算过程中变量的稳定。
如果sizeCtrl中高16位的邮戳与当前tableSize不匹配,或者搬运线程数达到了最大值,或者所有搬运的线程都已经退出(只有在遍历完所有槽位后才会退出,否则会一直循环),或者nextTable已经被清空,跳过搬运操作。
如果满足搬运条件,则对sizeCtrl做CAS操作,sizeCtrl>=0时设置初始线程数为2,sizeCtrl<0时将其值加1,CAS成功后开始搬运操作,失败则进入下一次循环重新判断。
首个线程设置初始值为2的原因是:线程退出时会通过CAS操作将参与搬运的总线程数-1,如果初始值按照常规做法设置成1,那么减1后就会变为0。
此时其它线程发现线程数为0时,无法区分是没有任何线程做过搬运,还是有线程做完搬运但都退出了,也就无法判断要不要加入搬运的行列。
值得注意的是,代码中的“sc == rs + 1 || sc == rs + MAX_RESIZERS“是JDK8中的明显的BUG,少了rs无符号左移16位的操作;JDK12已经修复了此问题。
2、并发搬运过程和退出机制
=================
C13Map的transfer方法
private final void transfer(Node<K, V>[] tab, Node<K, V>[] nextTab) {
int n = tab.length, stride;
//一次搬运多少个槽位
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE;
if (nextTab == null) {
try {
//首个搬运线程,负责初始化nextTable
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n << 1];
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
//初始化当前搬运索引
transferIndex = n;
}
int nextn = nextTab.length;
//公共的forwardingNode
ForwardingNode<K, V> fwd = new ForwardingNode<K, V>(nextTab);
boolean advance = true;
boolean finishing = false; // 保证提交nextTable之前已遍历旧表的所有槽位
for (int i = 0, bound = 0; ; ) {
Node<K, V> f;
int fh;
//循环CAS获取下一个搬运区段
while (advance) {
int nextIndex, nextBound;
//搬运已结束,或者当前区段尚未完成,退出循环体;最后一次抄底扫描时,仅辅助做i减一的运算
if (–i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
} else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
//并非最后一个退出的线程
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
//异常巧妙的设计,最后一个线程推出前将i回退到最高位,等于是强制做最后一次的全表扫描;程序直接执行后续的else if代码,看有没有哪个槽位漏掉了,或者说是否全部是forwardingNode标记;
//可以视为抄底逻辑,虽然检测到漏掉槽位的概率基本是0
i = n;
}
} else if ((f = tabAt(tab, i)) == null)
//空槽位直接打上forwardingNode标记,CAS失败下一次循环继续搬运该槽位,成功则进入下一个槽位
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; //最后一次抄底遍历时,正常情况下所有的槽位应该都被打上forwardingNode标记
else {
//锁定头节点
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K, V> ln, hn;
if (fh >= 0) {
//…此处省略链表搬运代码:职责是将链表拆成两份,搬运到nextTable的i和i+n槽位
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
//设置旧表对应槽位的头节点为forwardingNode
setTabAt(tab, i, fwd);
advance = true;
} else if (f instanceof TreeBin) {
//…此处省略红黑树搬运代码:职责是将红黑树拆成两份,搬运到nextTable的i和i+n槽位,如果满足红黑树的退化条件,顺便将其退化为链表
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
//设置旧表对应槽位的头节点为forwardingNode
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
多个线程并发搬运时,如果是首个搬运线程,负责nextTable的初始化工作;然后借助于全局的transferIndex变量从当前table的n-1槽位开始依次向低位扫描搬运,通过对transferIndex的CAS操作一次获取一个区段(默认是16),当transferIndex达到最低位时,不再能够获取到新的区段,线程开始退出,退出时会在sizeCtl上将总的线程数减一,最后一个退出的线程将扫描坐标i回退到最高位,强迫做一次抄底的全局扫描。
3、transfer过程中的读写安全性分析
=========================
(1)首先是transfer过程中是否有可能全局的哈希表table发生多次resize,或者说存在过期的风险?
===========================================================
观察nextTable提交到table的代码,发现只有在所有线程均搬运完毕退出后才会commit,所以但凡有一个线程在transfer代码块中,table都不可能被替换;所以不存在table过期的风险。
(2)有并发的写操作时,是否存在安全风险?
=========================
因为transfer操作与写操作都要竞争bin的头节点的syncronized锁,两者是互斥串行的;当写线程得到锁后,还要做doubleCheck,发现不是一开始的头节点时什么事情都不会做,发现是forwardingNode,就会加入搬运行列直到新表被提交,然后去直接操作新表。
nextTable的提交总是在所有的槽位都已经搬运完毕,插上ForwardingNode的标识之后的,因此只要新表已提交,旧表必定无法写入;这样就能够有效的避免数据写入旧表。
推理:获取到bin头节点的同步锁开始写操作----------> transfer必然未完成--------->新表必然未提交-------→写入的必然是当前表。
也就说永远不可能存在新旧两张表同时被写入的情况,table被写入时nextTable永远都只能被读取。
(3)有并发的读操作时,是否存在安全风险?
=========================
transfer操作并不破坏旧的bin结构,如果尚未开始搬运,将会照常遍历旧的BIN结构;如果已搬运完毕,会调用到forwadingNode的find方法到新表中递归查询,参考上文中的forwadingNode介绍。
九、Traverser遍历器
==================
因为iterator或containsValue等通用API的存在,以及某些业务场景确实需要遍历整个Map,设计一种安全且有性能保证的遍历机制显得理所当然。
C13Map遍历器实现的难点在于读操作与transfer可能并行,在扫描各个bin时如果遇到forwadingNode该如何处理的问题。
由于并发transfer机制的存在,在某个槽位上遇到了forwadingNode,仅表明当前槽位已被搬运,并不能代表其后的槽位一定被搬运或者尚未被搬运;也就是说其后的若干槽位是一个不可控的状态。
解决办法是引入了类似于方法调用堆栈的机制,在跳转到nextTable时记录下当前table和已经抵达的槽位并进行入栈操作,然后开始遍历下一个table的i和i+n槽位,如果遇到forwadingNode再一次入栈,周而复始循环往复;
每次如果i+n槽位如果到了右半段快要溢出的话就会遵循原来的入栈规则进行出栈,也就是回到上一个上下文节点,最终会回到初始的table也就是initialTable中的节点。
C13Map的Traverser组件
static class Traverser<K,V> {
Node<K,V>[] tab; // current table; updated if resized
Node<K,V> next; // the next entry to use
TableStack<K,V> stack, spare; // to save/restore on ForwardingNodes int index; // index of bin to use next
int baseIndex; // current index of initial table
int baseLimit; // index bound for initial table
final int baseSize; // initial table size
Traverser(Node<K,V>[] tab, int size, int index, int limit) { this.tab = tab; this.baseSize = size; this.baseIndex = this.index = index; this.baseLimit = limit; this.next = null;
} /** * 返回下一个节点 */ final Node<K,V> advance() { Node<K,V> e; if ((e = next) != null)
e = e.next;
for (;😉 {
Node<K,V>[] t; int i, n; // 局部变量保证稳定性 if (e != null)
return next = e;
if (baseIndex >= baseLimit || (t = tab) == null ||
(n = t.length) <= (i = index) || i < 0)
return next = null;
if ((e = tabAt(t, i)) != null && e.hash < 0) {
if (e instanceof ForwardingNode) {
tab = ((ForwardingNode<K,V>)e).nextTable; e = null; pushState(t, i, n); continue; } else if (e instanceof TreeBin)
e = ((TreeBin<K,V>)e).first; else
e = null; } //当前如果有跳转堆栈直接回放 if (stack != null)
recoverState(n); //没有跳转堆栈说明已经到initalTable else if ((index = i + baseSize) >= n)
index = ++baseIndex; // visit upper slots if present
} } /** * 遇到ForwardingNode时保存当前上下文 */ private void pushState(Node<K,V>[] t, int i, int n) { TableStack<K,V> s = spare; // reuse if possible
if (s != null)
spare = s.next;
else
s = new TableStack<K,V>(); s.tab = t; s.length = n; s.index = i; s.next = stack;
stack = s; } /** * 弹出上下文 * */ private void recoverState(int n) { TableStack<K,V> s; int len;
//如果当前有堆栈,且index已经到达右半段后溢出当前table,说明该回去了
//如果index还在左半段,则只辅助做index+=s.length操作 while ((s = stack) != null && (index += (len = s.length)) >= n) {
n = len;
index = s.index; tab = s.tab; s.tab = null; TableStack<K,V> next = s.next;
s.next = spare; // save for reuse
stack = next;
spare = s; } //已经到initialTable,索引自增 if (s == null && (index += baseSize) >= n)
index = ++baseIndex; }}
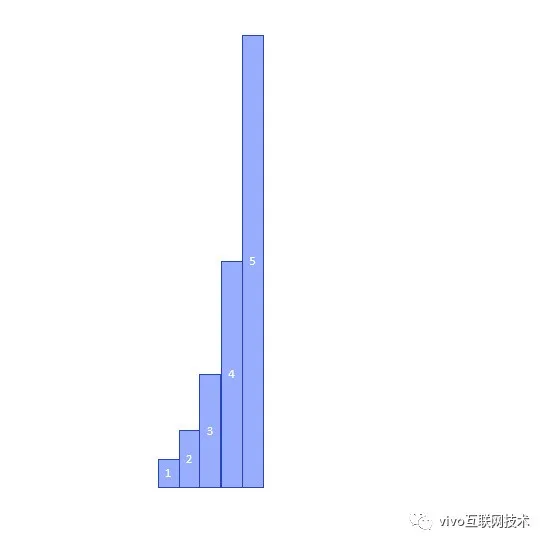
假设在整个遍历过程中初始表initalTable=table1,遍历到结束时最大的表为table5,也就是在遍历过程中经历了四次扩容,属于一边遍历一边扩容的最复杂场景;
那么整个遍历过程就是一个以初始化表initalTable为基准表,以下一张表的i和i+n槽位为forwadingNode的跳转目标,类似于粒子裂变一般的从最低表向最高表放射的过程;
traverser并不能保证一定遍历某张表的所有的槽位,但如果假设低阶表的某个槽位在最高阶表总是有相应的投影,比如table1的一个节点在table5中就会对应16个投影;
traverser能够保证一次遍历的所有槽位在最高阶表上的投影,可以布满整张最高阶表,而不会有任何遗漏。
十、并发计数
==========
与HashMap中直接定义了size字段类似,获取元素的totalCount在C13MAP中肯定不会去遍历完整的数据结构;那样元素较多时性能会非常差,C13MAP设计了CounterCell[]数组来解决并发计数的问题。
CounterCell[]机制并不理会新旧table的更迭,不管是操作的新表还是旧表,对于计数而言没有本质的差异,CounterCell[]只关注总量的增加或减少。
1、从LongAdder到CounterCell内存对齐
================================
C13MAP借鉴了JUC中LongAdder和Striped64的计数机制,有大量代码与LongAdder和Striped64是重复的,其核心思想是多核环境下对于64位long型数据的计数操作,虽然借助于volatile和CAS操作能够保证并发的安全性,但是因为多核操作的是同一内存区域,而每个CPU又有自己的本地cache,例如LV1 Cache,LVL2 Cache,寄存器等。
由于内存一致性协议MESI的存在,会导致本地Cache的频繁刷新影响性能,一个比较好的解决思路是每个CPU只操作固定的一块内存对齐区域,最终采用求和的方式来计数。
这种方式能提高性能,但是并非所有场景都适用,因为其最终的value是如何估算出来的,CounterCell累加求和的过程并非原子,不能代表某个时刻的精准value,所以像compareAndSet这样的原子操作就无法支持。
2、CounterCell[] 、cellBusy、baseCount的作用
============================================
CounterCell[]中存放2的指数幂个CounterCell,并发操作期间有可能会扩容,每次扩容都是原有size的两倍,一旦超过了CPU的核数即不再扩容,因为CPU的总数通常也是2的指数幂,所以其size往往等于CPU的核数CounterCell[]初始化、扩容、填充元素时,借助cellBusy其进行spinLock控制baseCount是基础数据。
在并发量不那么大,CAS没有出现失败时直接基于baseCount变量做计数;一旦出现CAS失败,说明有并发冲突,就开始考虑CounterCell[]的初始化或者扩容操作,但在初始化未完成时,还是会将其视为抄底方案进行计数。
所以最终的技术总和=baseCount+所有CounterCell中的value。
C13Map的addCount方法
private final void addCount(long x, int check) {
CounterCell[] cs; long b, s;
//初始时总是直接对baseCount计数,直到出现第一次失败,或者已经有现成的CounterCell[]数组可用
if ((cs = counterCells) != null ||
!U.compareAndSetLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell c; long v; int m;
//是否存在竞态,为true时表示无竞态
boolean uncontended = true;
if (cs == null || (m = cs.length - 1) < 0 ||
//先生成随机数再对CounterCell[]数组size求余,也就是随机分配到其中某个槽位
(c = cs[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSetLong(c, CELLVALUE, v = c.value, v + x))) {
//该槽位尚未初始化或者CAS操作又出现竞态
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
//检测元素总数是否超过sizeCtl阈值
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n) << RESIZE_STAMP_SHIFT;
if (sc < 0) {
if (sc == rs + MAX_RESIZERS || sc == rs + 1 ||
(nt = nextTable) == null || transferIndex <= 0)
break;
if (U.compareAndSetInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSetInt(this, SIZECTL, sc, rs + 2))
transfer(tab, null);
s = sumCount();
}
}
}
写在最后
在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。
需要完整版PDF学习资源私我
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 926
926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









