







本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。
最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。
最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!下面就开始进入正题,如何从一个萌新一步一步进入网络安全行业。
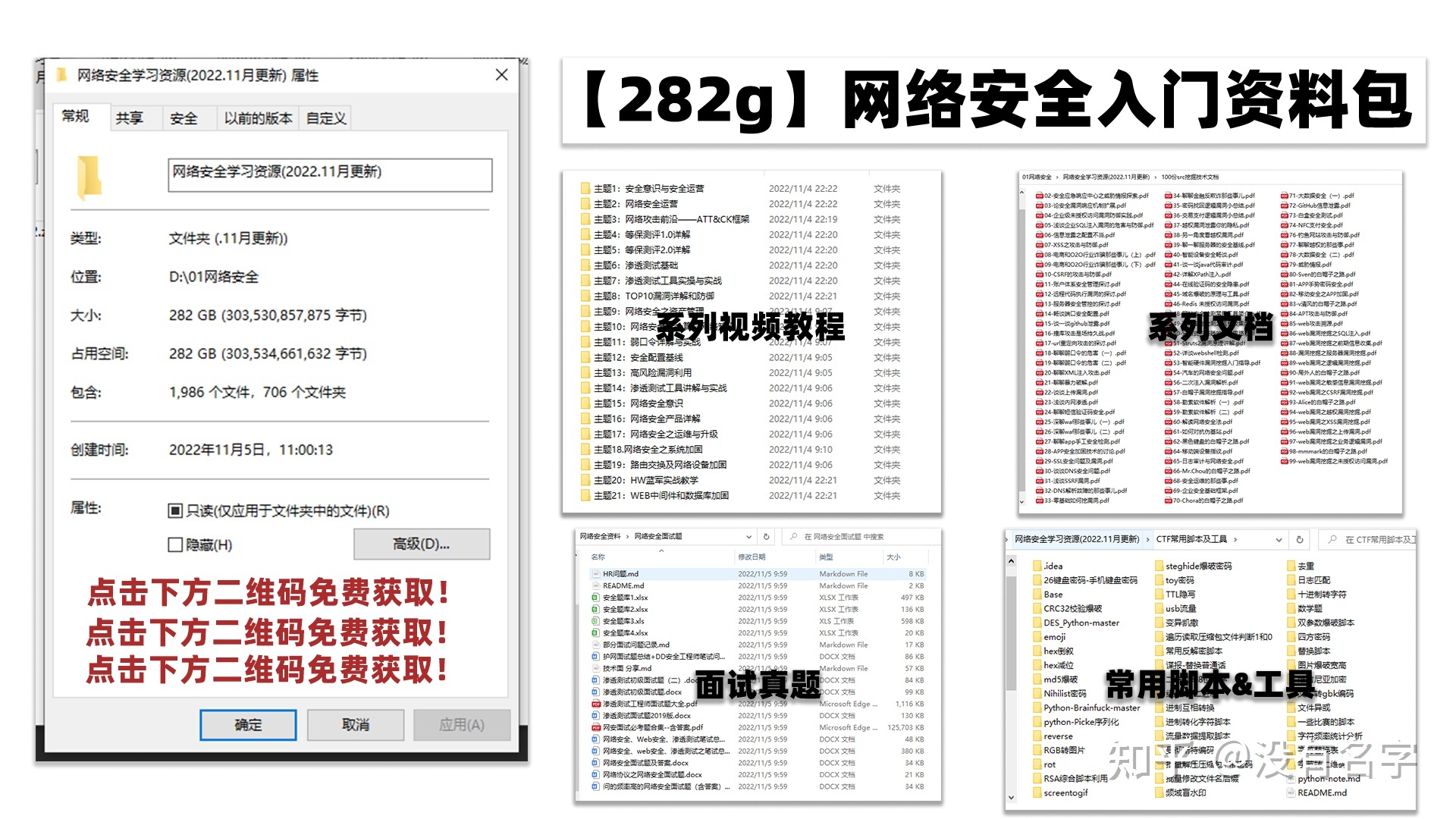
学习路线图
其中最为瞩目也是最为基础的就是网络安全学习路线图,这里我给大家分享一份打磨了3个月,已经更新到4.0版本的网络安全学习路线图。
相比起繁琐的文字,还是生动的视频教程更加适合零基础的同学们学习,这里也是整理了一份与上述学习路线一一对应的网络安全视频教程。
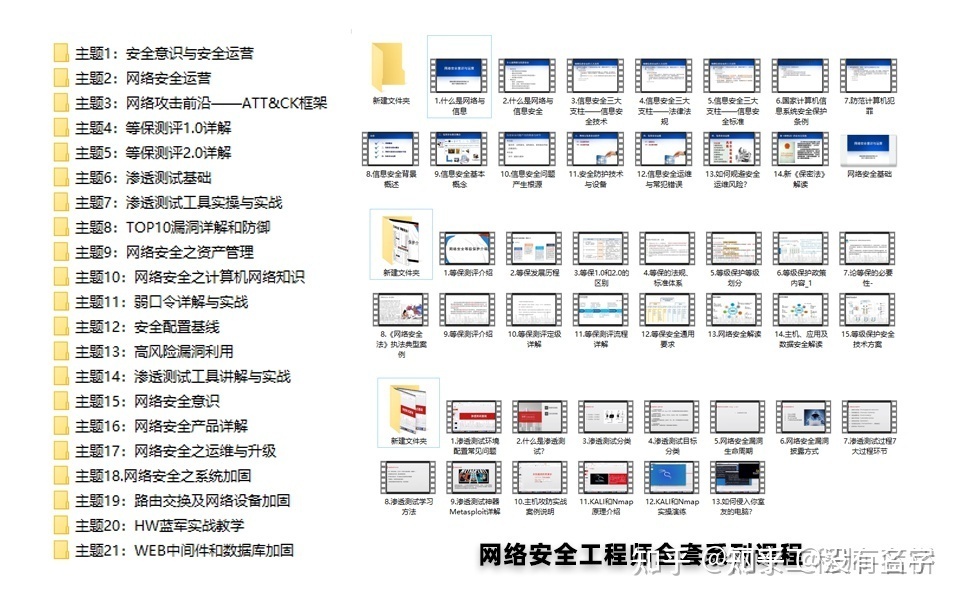
网络安全工具箱
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,你肯定需要学习各种工具的使用以及大量的实战项目,这里也分享一份我自己整理的网络安全入门工具以及使用教程和实战。
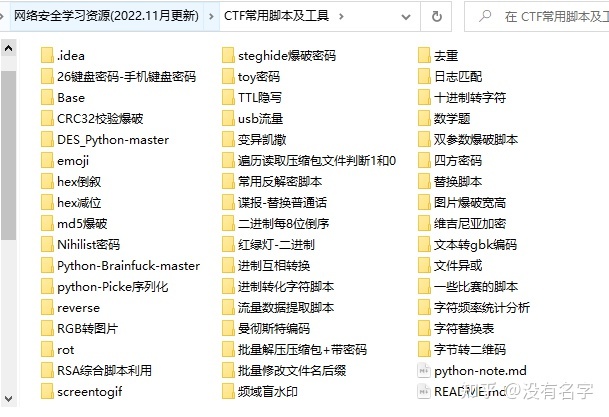
项目实战
最后就是项目实战,这里带来的是SRC资料&HW资料,毕竟实战是检验真理的唯一标准嘛~

面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
4.0.0
org.example
flink_hudi_test
1.0-SNAPSHOT
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
org.apache.hadoop
hadoop-client
2.9.2
org.apache.hadoop
hadoop-hdfs
2.9.2
org.apache.hadoop
hadoop-common
2.9.2
org.apache.flink
flink-core
1.12.2
org.apache.flink
flink-streaming-java_2.11
1.12.2
org.apache.flink
flink-connector-jdbc_2.11
1.12.2
org.apache.flink
flink-java
1.12.2
org.apache.flink
flink-clients_2.11
1.12.2
org.apache.flink
flink-table-api-java-bridge_2.11
1.12.2
org.apache.flink
flink-table-common
1.12.2
org.apache.flink
flink-table-planner_2.11
1.12.2
org.apache.flink
flink-table-planner-blink_2.11
1.12.2
org.apache.flink
flink-table-planner-blink_2.11
1.12.2
test-jar
com.alibaba.ververica
flink-connector-mysql-cdc
1.2.0
org.apache.hudi
hudi-flink-bundle_2.11
0.9.0
mysql
mysql-connector-java
5.1.49
我们通过构建查询`insert into t2 select replace(uuid(),'-',''),id,name,description,now() from mysql_binlog` 将创建的mysql表,插入到hudi里。
package name.lijiaqi;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class MysqlToHudiExample {
public static void main(String[] args) throws Exception {
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, fsSettings);
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
// 数据源表
String sourceDDL =
“CREATE TABLE mysql_binlog (\n” +
" id INT NOT NULL,\n" +
" name STRING,\n" +
" description STRING\n" +
“) WITH (\n” +
" ‘connector’ = ‘jdbc’,\n" +
" ‘url’ = ‘jdbc:mysql://127.0.0.1:3306/test’, \n"+
" ‘driver’ = ‘com.mysql.jdbc.Driver’, \n"+
" ‘username’ = ‘root’,\n" +
" ‘password’ = ‘dafei1288’, \n" +
" ‘table-name’ = ‘test_cdc’\n" +
“)”;
// 输出目标表
String sinkDDL =
“CREATE TABLE t2(\n” +
“\tuuid VARCHAR(20),\n”+
“\tid INT NOT NULL,\n” +
“\tname VARCHAR(40),\n” +
“\tdescription VARCHAR(40),\n” +
“\tts TIMESTAMP(3)\n”+
// “\tpartition VARCHAR(20)\n” +
“)\n” +
// “PARTITIONED BY (partition)\n” +
“WITH (\n” +
“\t’connector’ = ‘hudi’,\n” +
“\t’path’ = ‘hdfs://172.19.28.4:9000/hudi_t4/’,\n” +
“\t’table.type’ = ‘MERGE_ON_READ’\n” +
“)” ;
// 简单的聚合处理
String transformSQL =
“insert into t2 select replace(uuid(),‘-’,‘’),id,name,description,now() from mysql_binlog”;
tableEnv.executeSql(sourceDDL);
tableEnv.executeSql(sinkDDL);
TableResult result = tableEnv.executeSql(transformSQL);
result.print();
env.execute(“mysql-to-hudi”);
}
}
查询hudi
package name.lijiaqi;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class ReadHudi {
public static void main(String[] args) throws Exception {
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, fsSettings);
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
String sourceDDL =
“CREATE TABLE t2(\n” +
“\tuuid VARCHAR(20),\n”+
“\tid INT NOT NULL,\n” +
“\tname VARCHAR(40),\n” +
“\tdescription VARCHAR(40),\n” +
“\tts TIMESTAMP(3)\n”+
// “\tpartition VARCHAR(20)\n” +
“)\n” +
// “PARTITIONED BY (partition)\n” +
“WITH (\n” +
“\t’connector’ = ‘hudi’,\n” +
“\t’path’ = ‘hdfs://172.19.28.4:9000/hudi_t4/’,\n” +
“\t’table.type’ = ‘MERGE_ON_READ’\n” +
“)” ;
tableEnv.executeSql(sourceDDL);
TableResult result2 = tableEnv.executeSql(“select * from t2”);
result2.print();
env.execute(“read_hudi”);
}
}
展示结果

## Flink CDC 2.0 on Hudi
### 添加依赖
添加如下依赖到$FLINK\_HOME/lib下
* hudi-flink-bundle\_2.11-0.10.0-SNAPSHOT.jar (修改 Master 分支的 Hudi Flink 版本为 1.13.2 然后构建)
* hadoop-mapreduce-client-core-2.7.3.jar (解决 Hudi ClassNotFoundException)
* flink-sql-connector-mysql-cdc-2.0.0.jar
* flink-format-changelog-json-2.0.0.jar
* flink-sql-connector-kafka\_2.11-1.13.2.jar
**注意,在寻找jar的时候,`cdc 2.0` 更新过`group id` ,不再试 `com.alibaba.ververica` 而是改成了 `com.ververica`**
### flink sql cdc on hudi
创建mysql cdc表
CREATE TABLE mysql_users (
id BIGINT PRIMARY KEY NOT ENFORCED ,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3)
) WITH (
‘connector’ = ‘mysql-cdc’,
‘hostname’ = ‘localhost’,
‘port’ = ‘3306’,
‘username’ = ‘root’,
‘password’ = ‘dafei1288’,
‘server-time-zone’ = ‘Asia/Shanghai’,
‘database-name’ = ‘test’,
‘table-name’ = ‘users’
);
创建hudi表
CREATE TABLE hudi_users5(
id BIGINT PRIMARY KEY NOT ENFORCED,
name STRING,
birthday TIMESTAMP(3),
ts TIMESTAMP(3),
partition VARCHAR(20)
) PARTITIONED BY (partition) WITH (
‘connector’ = ‘hudi’,
‘table.type’ = ‘MERGE_ON_READ’,
‘path’ = ‘hdfs://localhost:9009/hudi/hudi_users5’
);
修改配置,让查询模式输出为表,设置checkpoint
>
> set execution.result-mode=tableau;
>
>
> set execution.checkpointing.interval=10sec;
>
>
>
进行输入导入
>
> INSERT INTO hudi\_users5(id,name,birthday,ts, `partition`) SELECT id,name,birthday,ts,DATE\_FORMAT(birthday, 'yyyyMMdd') FROM mysql\_users;
>
>
>
查询数据
>
> select \* from hudi\_users5;
>
>
>
执行结果

## 学习路线:
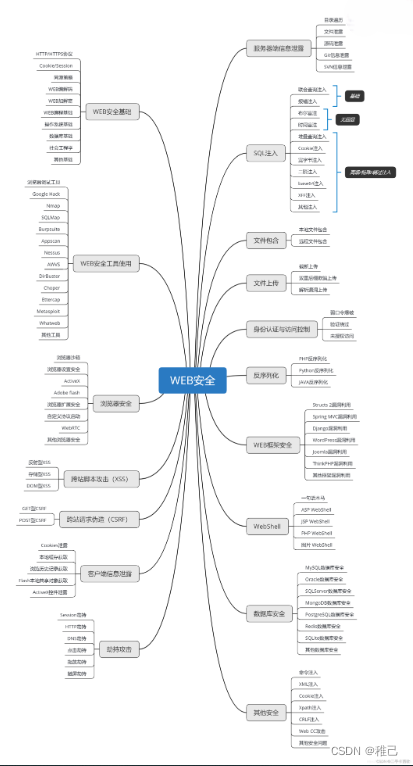
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 3380
3380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









