







还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题
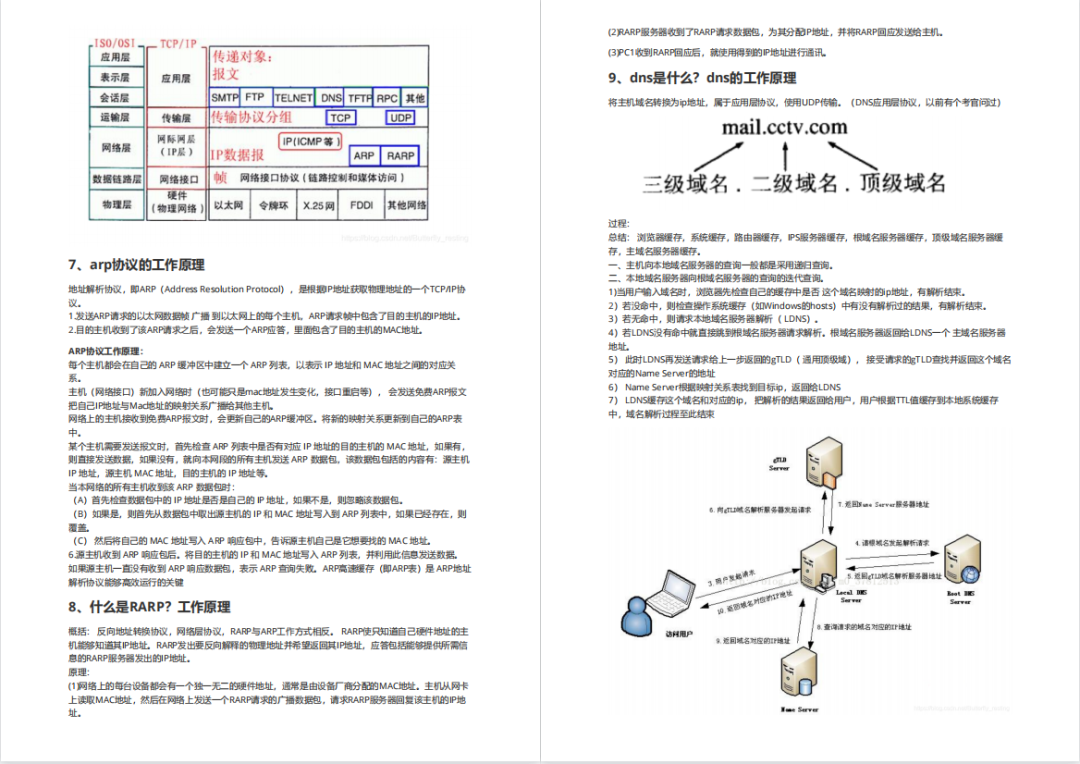


内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以联系领取~
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
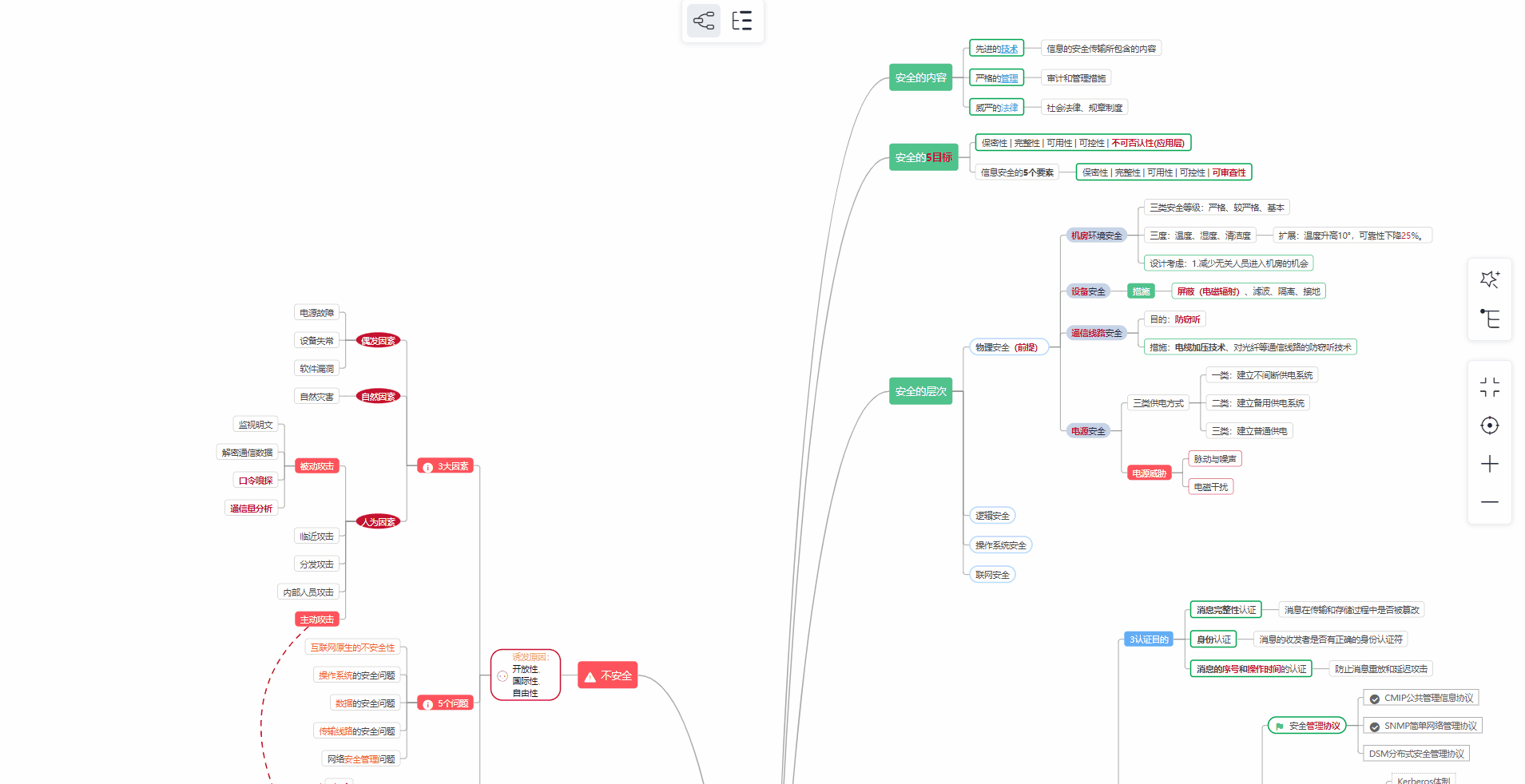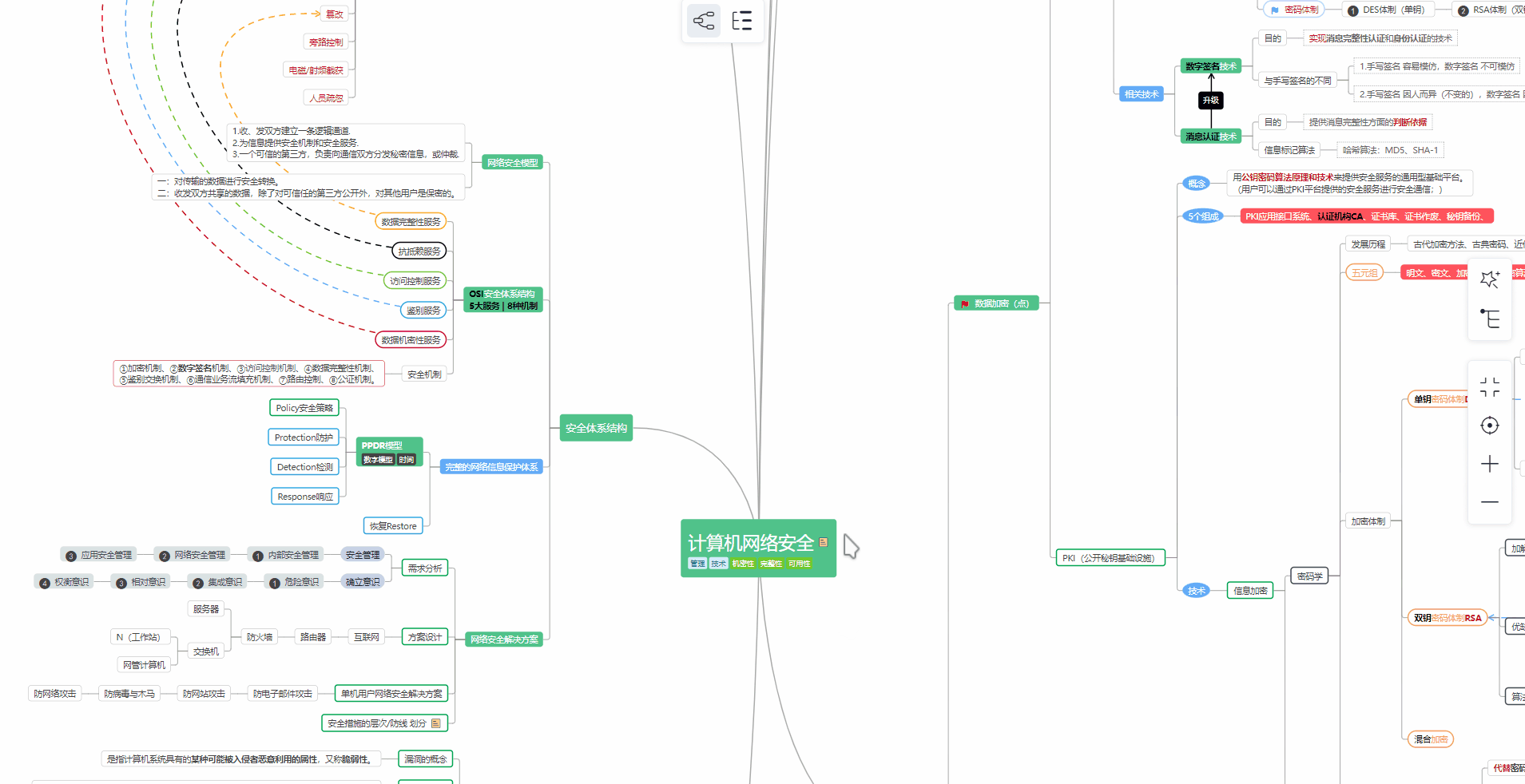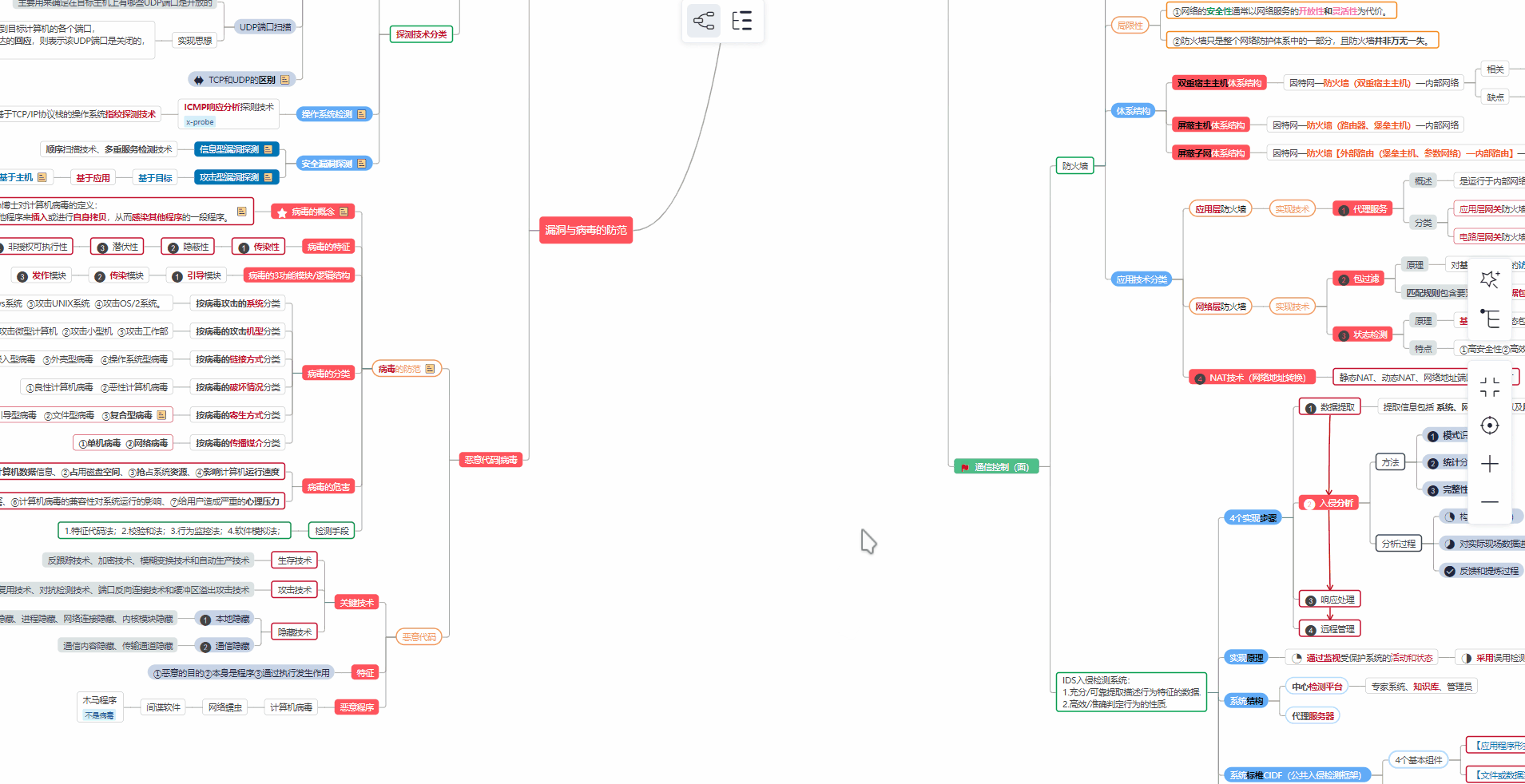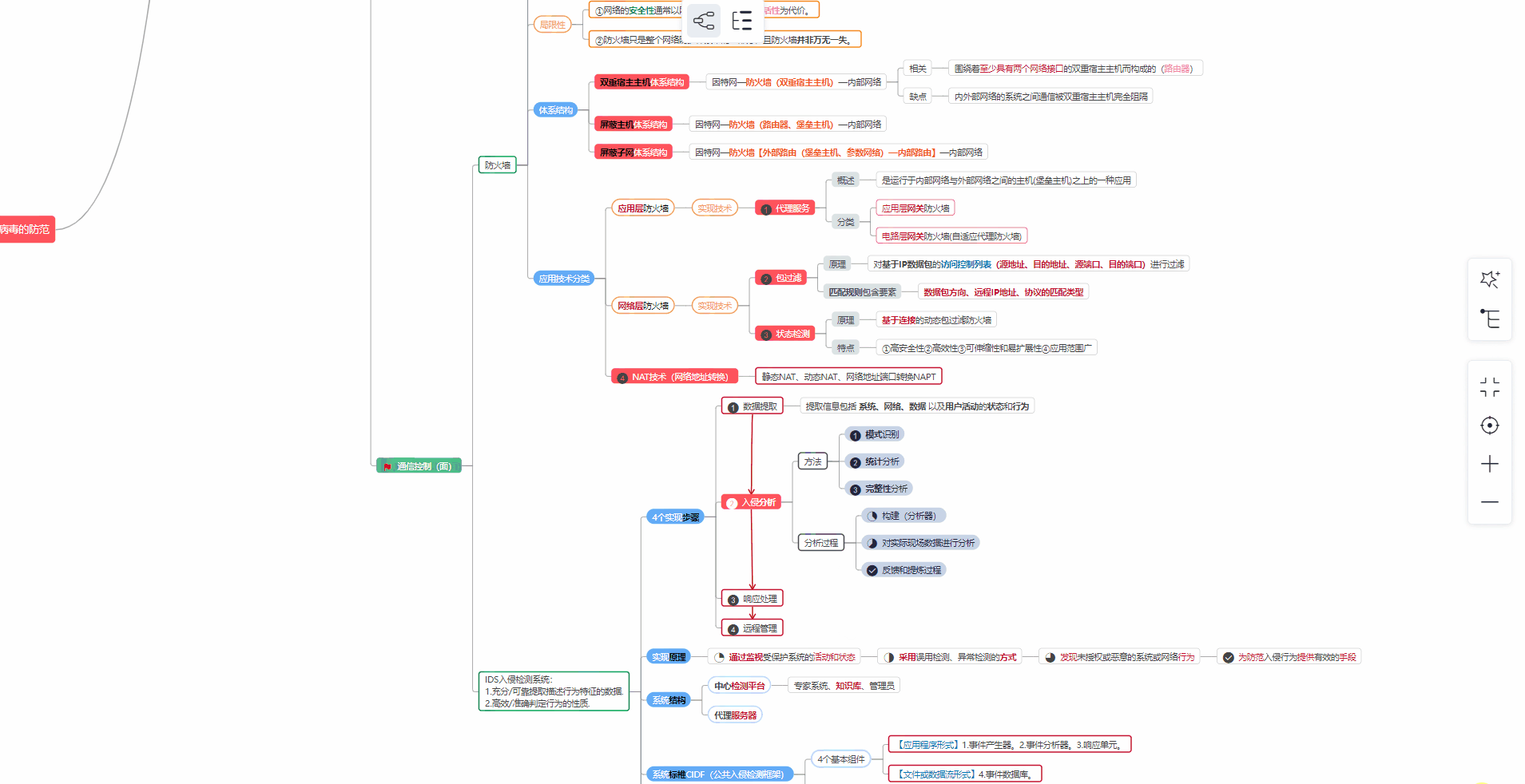
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

2️⃣视频配套工具&国内外网安书籍、文档
① 工具

② 视频
③ 书籍
资源较为敏感,未展示全面,需要的最下面获取

② 简历模板
因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
System.out.println("result: " + result);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
复制代码
线程安全和线程同步
=========
线程安全:指函数在多线程环境中被调用时,能够正确地处理多个线程之间的全局变量,使得功能正确完成。
线程同步:即当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作。
线程同步不等于线程安全,现在很多人误解了这一点而喜欢将他们混为一谈。现实是,当我询问面试者何为线程同步时,很多人回答的都是线程安全。
线程同步是实现线程安全的一种手段,你当然也可以用其他的方式达到线程安全。
线程安全的本质问题是资源问题:
当一个共享资源被一个线程读操作时,该资源不能被其他线程任意写;
当一个共享资源被一个线程写操作时,该资源不能被其他线程任意读写;
下面介绍java中实现线程安全的几种方式:
synchronized
synchronized以同步方式保证了方法内部或代码块内部资源(数据)的互斥访问,保证了线程之间对监视资源的数据同步.
private synchronized void count(int newValue) {
x = newValue;
System.out.println("x= " + x);
}
复制代码
另一种写法:
private void count(int newValue) {
synchronized (this) {
x = newValue;
System.out.println("x= " + x);
}
}
复制代码
volatile
volatile关键字修饰的变量具有原子性和同步性,相当于实现了对单⼀字段的线程间互斥访问。
volatile关键字能够保证内存的可见性,如果用volatile关键字声明了一个变量,在一个线程里面改变了这个变量的值,那其它线程是立马可见更改后的值的。
volatile可以看做是简化版的 synchronized.
volatile 只对基本类型 (byte、char、short、int、long、float、double、boolean)的赋值操作和对象的引⽤赋值操作有效。
java.util.concurrent.atomic:
AtomicInteger、AtomicBoolean 等类,作⽤和 volatile 基本⼀致,可以看做是 volatile修饰的Integer、Boolean等类。
Lock / ReentrantReadWriteLock
Lock同样是加锁机制,但使⽤⽅式更灵活,同时也更麻烦:
Lock lock = new ReentrantLock();
…
lock.lock();
try {
x++;
} finally {
lock.unlock();
}
复制代码
Synchronized存在的一个性能问题就是读与读之间互斥,所以我们⼀般并不会只是使⽤ Lock ,⽽是会使⽤更复杂的锁,例如 ReadWriteLock ,从而进行一些更加细致化的操作,如下代码:
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
Lock readLock = lock.readLock();
Lock writeLock = lock.writeLock();
private int x = 0;
private void writeOperate () {
writeLock.lock();
try {
x++;
} finally {
writeLock.unlock();
}
}
private void readOperate ( int time){
readLock.lock();
try {
System.out.println();
} finally {
readLock.unlock();
}
}
复制代码
读取锁是共享的,因而上述代码中,有线程写操作时,其他线程不可写,不可读;该线程读操作时,其他线程不可写,但可读。
线程间通信/交互
========
线程有自己的私有空间,但当我多个线程之间相互协作的时候,就需要进行线程间通信方,本节将介绍Java线程之间的几种通信原理。
锁与同步
这种方式主要是对全局变量加锁,即用synchronized关键字对对象或者代码块加锁lock,来达成线程间通信。
这种方式可详见上一节线程同步中的例子。
等待/通知机制
基于“锁”的方式需要线程不断去尝试获得锁,这会耗费服务器资源。
Java多线程的等待/通知机制是基于Object类的wait()方法和notify(), notifyAll()方法来实现的,
wait()方法和notify()方法必须写在synchronized代码块里面:
wait()和notify()方法必须通过获取的锁对象进行调用,因为wait就是线程在获取对象锁后,主动释放对象锁,同时休眠本线程,直到有其它线程调用对象的notify()唤醒该线程,才能继续获取对象锁,并继续执行。相应的notify()就是对对象锁的唤醒操作,因而必须放在加锁的synchronized代码块环境内。
notify()方法会随机叫醒一个正在等待的线程,而notifyAll()会叫醒所有正在等待的线程,被唤醒的线程重新在就绪队列中按照一定算法最终再次被处理机获得并进行处理,而不是立马重新获得处理机。
public class mythread {
private static Object lock = new Object();
static class ThreadA implements Runnable {
@Override
public void run() {
synchronized (lock) {
for (int i = 0; i < 5; i++) {
try {
System.out.println("ThreadA: " + i);
lock.notify();
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
lock.notify();
}
}
}
static class ThreadB implements Runnable {
@Override
public void run() {
synchronized (lock) {
for (int i = 0; i < 5; i++) {
try {
System.out.println("ThreadB: " + i);
lock.notify();
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
lock.notify();
}
}
}
public static void main(String[] args) {
new Thread(new ThreadA()).start();
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(new ThreadB()).start();
}
}
复制代码
join方法
join()方法让当前线程陷入“等待”状态,等join的这个线程执行完成后,再继续执行当前线程。
当主线程创建并启动了耗时子线程,而主线程早于子线程结束之前结束时,就可以用join方法等子线程执行完毕后,从而让主线程获得子线程中的处理完的某个数据。
join()方法及其重载方法底层都是利用了wait(long)这个方法。
public class mythread {
static class ThreadA implements Runnable {
@Override
public void run() {
try {
System.out.println(“子线程睡一秒”);
Thread.sleep(1000);
System.out.println(“子线程睡完了一秒”);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new ThreadA());
thread.start();
thread.join();
System.out.println(“如果不加join方法,这行就会先打印出来”);
}
}
复制代码
sleep方法
sleep方法是Thread类的一个静态方法。它的作用是让当前线程睡眠一段时间:
- Thread.sleep(long)
这里需要强调一下:**sleep方法是不会释放当前的锁的,而wait方法会。**这也是最常见的一个多线程面试题。
sleep方法和wait方法的区别:
-
wait可以指定时间,也可以不指定;而sleep必须指定时间。
-
wait释放cpu资源,同时释放锁;sleep释放cpu资源,但是不释放锁,所以易死锁。
-
wait必须放在同步块或同步方法中,而sleep可以再任意位置
ThreadLocal类
ThreadLocal是一个本地线程副本变量工具类,可以理解成为线程本地变量或线程本地存储。严格来说,ThreadLocal类并不属于多线程间的通信,而是让每个线程有自己“独立”的变量,线程之间互不影响。
ThreadLocal类最常用的就是set方法和get方法。示例代码:
public class mythread {
static class ThreadA implements Runnable {
private ThreadLocal threadLocal;
public ThreadA(ThreadLocal threadLocal) {
this.threadLocal = threadLocal;
}
@Override
public void run() {
threadLocal.set(“A”);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(“ThreadA输出:” + threadLocal.get());
}
public static void main(String[] args) {
ThreadLocal threadLocal = new ThreadLocal<>();
new Thread(new ThreadA(threadLocal)).start();
}
}
}
复制代码
可以看到,ThreadA可以存取自己当前线程的一个值。如果开发者希望将类的某个静态变量(user ID或者transaction ID)与线程状态关联,则可以考虑使用ThreadLocal,而不是在每个线程中声明一个私有变量来操作,加“重”线程。
InheritableThreadLocal是ThreadLocal的继承子类,不仅当前线程可以存取副本值,而且它的子线程也可以存取这个副本值。
信号量机制
JDK提供了一个类似于“信号量”功能的类Semaphore。在多个线程(超过2个)需要相互合作的场景下,我们用简单的“锁”和“等待通知机制”就不那么方便了。这个时候就可以用到信号量。JDK中提供的很多多线程通信工具类都是基于信号量模型的。
管道
–
管道是基于“管道流”的通信方式。JDK提供了PipedWriter、 PipedReader、 PipedOutputStream、 PipedInputStream。其中,前面两个是基于字符的,后面两个是基于字节流的。
如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
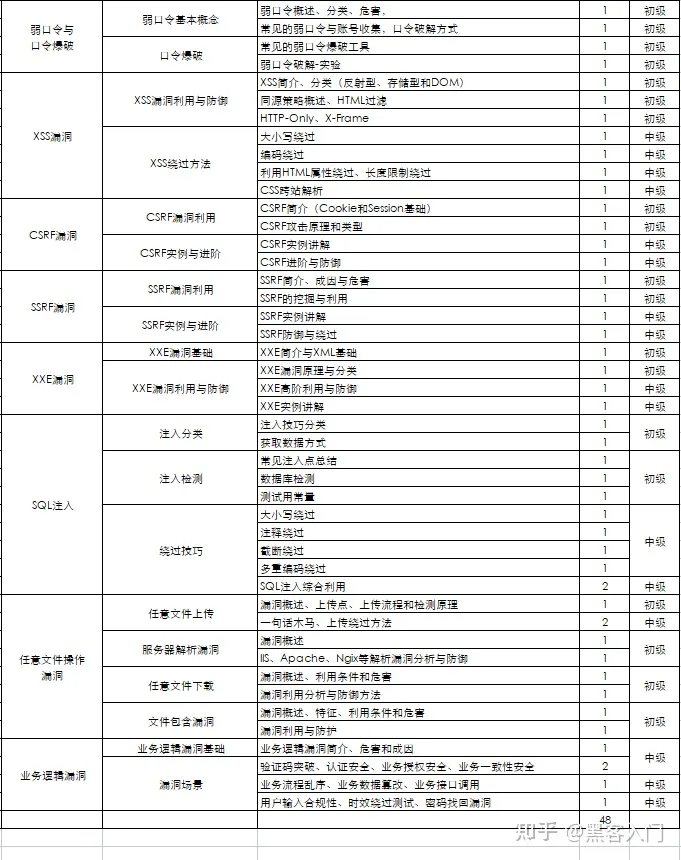
网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
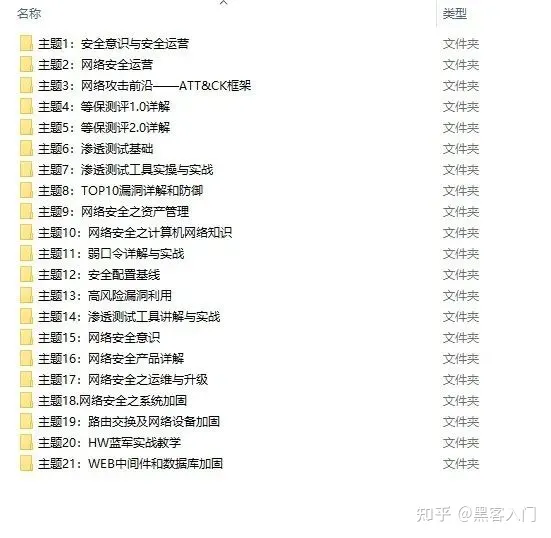
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









