







(3) reward
highway-env包中除了泊车场景外都采用同一个reward function:
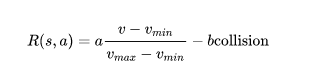
这个function只能在其源码中更改,在外层只能调整权重。
(泊车场景的reward function原文档里有)
2、搭建模型
DQN网络,我采用第一种state表示方式——Kinematics进行示范。由于state数据量较小(5辆车*7个特征),可以不考虑使用CNN,直接把二维数据的size[5,7]转成[1,35]即可,模型的输入就是35,输出是离散action数量,共5个。
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as T
from torch import FloatTensor, LongTensor, ByteTensor
from collections import namedtuple
import random
Tensor = FloatTensor
EPSILON = 0 # epsilon used for epsilon greedy approach
GAMMA = 0.9
TARGET_NETWORK_REPLACE_FREQ = 40 # How frequently target netowrk updates
MEMORY_CAPACITY = 100
BATCH_SIZE = 80
LR = 0.01 # learning rate
class DQNNet(nn.Module):
def __init__(self):
super(DQNNet,self).__init__()
self.linear1 = nn.Linear(35,35)
self.linear2 = nn.Linear(35,5)
def forward(self,s):
s=torch.FloatTensor(s)
s = s.view(s.size(0),1,35)
s = self.linear1(s)
s = self.linear2(s)
return s
class DQN(object):
def __init__(self):
self.net,self.target_net = DQNNet(),DQNNet()
self.learn_step_counter = 0
self.memory = []
self.position = 0
self.capacity = MEMORY_CAPACITY
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self,s,e):
x=np.expand_dims(s, axis=0)
if np.random.uniform() < 1-e:
actions_value = self.net.forward(x)
action = torch.max(actions_value,-1)[1].data.numpy()
action = action.max()
else:
action = np.random.randint(0, 5)
return action
def push_memory(self, s, a, r, s_):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(torch.unsqueeze(torch.FloatTensor(s), 0),torch.unsqueeze(torch.FloatTensor(s_), 0),\
torch.from_numpy(np.array([a])),torch.from_numpy(np.array([r],dtype='float32')))#
self.position = (self.position + 1) % self.capacity
def get_sample(self,batch_size):
sample = random.sample(self.memory,batch_size)
return sample
def learn(self):
if self.learn_step_counter % TARGET_NETWORK_REPLACE_FREQ == 0:
self.target_net.load_state_dict(self.net.state_dict())
self.learn_step_counter += 1
transitions = self.get_sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
b_s = Variable(torch.cat(batch.state))
b_s_ = Variable(torch.cat(batch.next_state))
b_a = Variable(torch.cat(batch.action))
b_r = Variable(torch.cat(batch.reward))
q_eval = self.net.forward(b_s).squeeze(1).gather(1,b_a.unsqueeze(1).to(torch.int64))
q_next = self.target_net.forward(b_s_).detach() #
q_target = b_r + GAMMA * q_next.squeeze(1).max(1)[0].view(BATCH_SIZE, 1).t()
loss = self.loss_func(q_eval, q_target.t())
self.optimizer.zero_grad() # reset the gradient to zero
loss.backward()
self.optimizer.step() # execute back propagation for one step
return loss
Transition = namedtuple('Transition',('state', 'next_state','action', 'reward'))
3、运行结果
各个部分都完成之后就可以组合在一起训练模型了,流程和用CARLA差不多,就不细说了。
初始化环境(DQN的类加进去就行了):
import gym
import highway_env
from matplotlib import pyplot as plt
import numpy as np
import time
config = \
{
"observation":
{
"type": "Kinematics",
"vehicles_count": 5,
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8, # [Hz]
"policy_frequency": 2, # [Hz]
}
env = gym.make("highway-v0")
env.configure(config)
训练模型:
dqn=DQN()
count=0
reward=[]
avg_reward=0
all_reward=[]
time_=[]
all_time=[]
collision_his=[]
all_collision=[]
while True:
done = False
start_time=time.time()
s = env.reset()
while not done:
e = np.exp(-count/300) #随机选择action的概率,随着训练次数增多逐渐降低
a = dqn.choose_action(s,e)
s_, r, done, info = env.step(a)
env.render()
dqn.push_memory(s, a, r, s_)
if ((dqn.position !=0)&(dqn.position % 99==0)):
loss_=dqn.learn()
count+=1
print('trained times:',count)
if (count%40==0):
avg_reward=np.mean(reward)
avg_time=np.mean(time_)
collision_rate=np.mean(collision_his)
all_reward.append(avg_reward)
all_time.append(avg_time)
all_collision.append(collision_rate)
plt.plot(all_reward)
plt.show()
plt.plot(all_time)
plt.show()
plt.plot(all_collision)
plt.show()
reward=[]
time_=[]
collision_his=[]
s = s_
reward.append(r)
end_time=time.time()
episode_time=end_time-start_time
time_.append(episode_time)
is_collision=1 if info['crashed']==True else 0
collision_his.append(is_collision)
我在代码中添加了一些画图的函数,在运行过程中就可以掌握一些关键的指标,每训练40次统计一次平均值。
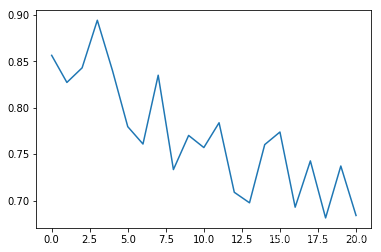
平均碰撞发生率:
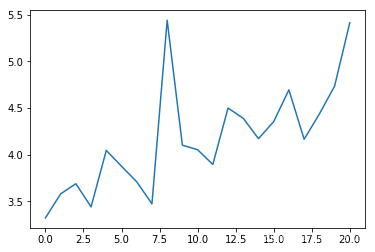
epoch平均时长(s):
平均reward:
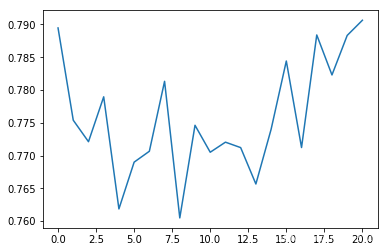
可以看出平均碰撞发生率会随训练次数增多逐渐降低,每个epoch持续的时间会逐渐延长(如果发生碰撞epoch会立刻结束)
总结
相比于模拟器CARLA,highway-env环境包明显更加抽象化,用类似游戏的表示方式,使得算法可以在一个理想的虚拟环境中得到训练,而不用考虑数据获取方式、传感器精度、运算时长等现实问题。对于端到端的算法设计和测试非常友好,但从自动控制的角度来看,可以入手的方面较少,研究起来不太灵活。
更多精彩教程欢迎B站搜索“千锋教育”
本人从事网路安全工作12年,曾在2个大厂工作过,安全服务、售后服务、售前、攻防比赛、安全讲师、销售经理等职位都做过,对这个行业了解比较全面。
最近遍览了各种网络安全类的文章,内容参差不齐,其中不伐有大佬倾力教学,也有各种不良机构浑水摸鱼,在收到几条私信,发现大家对一套完整的系统的网络安全从学习路线到学习资料,甚至是工具有着不小的需求。
最后,我将这部分内容融会贯通成了一套282G的网络安全资料包,所有类目条理清晰,知识点层层递进,需要的小伙伴可以点击下方小卡片领取哦!下面就开始进入正题,如何从一个萌新一步一步进入网络安全行业。
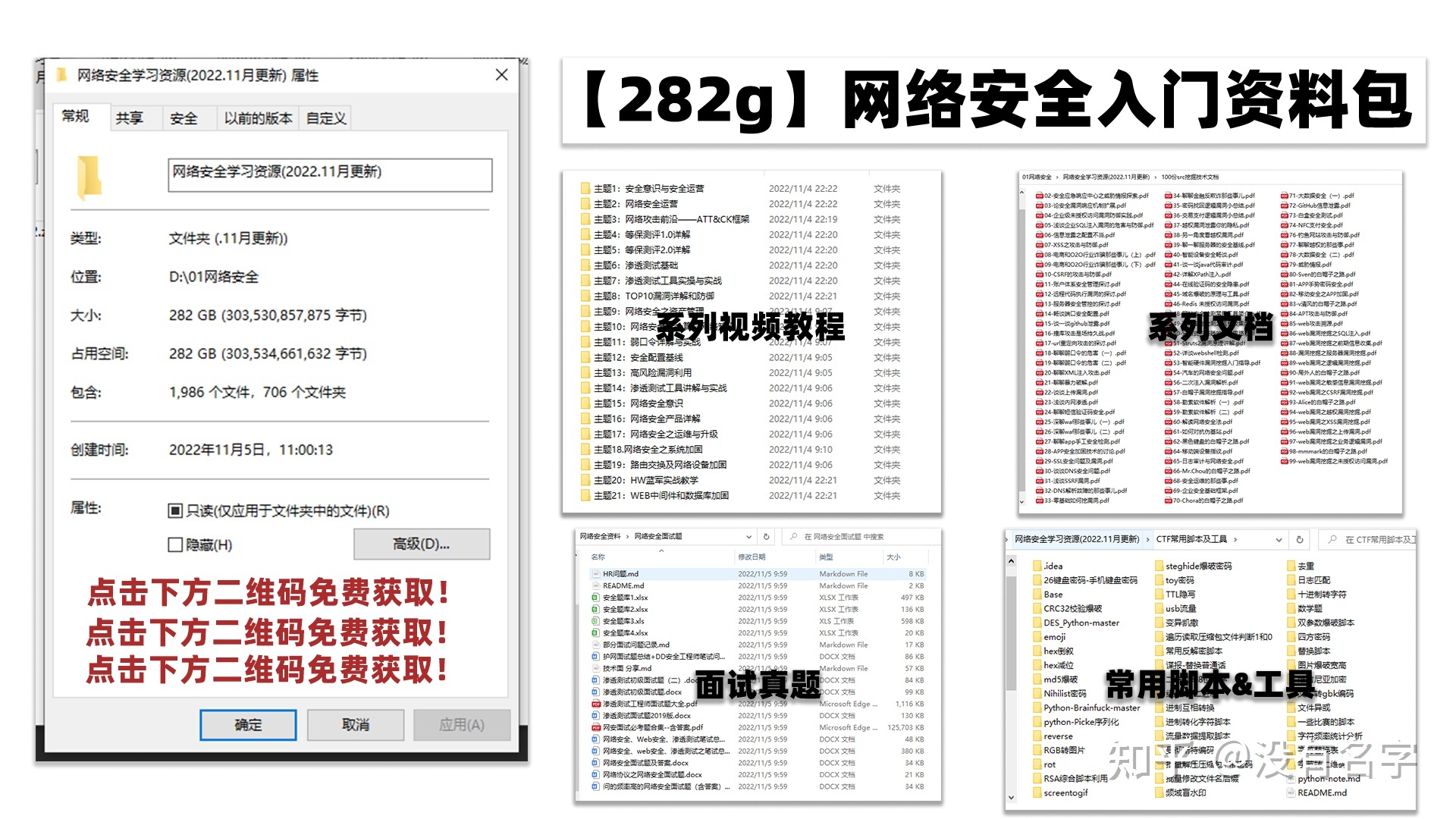
学习路线图
其中最为瞩目也是最为基础的就是网络安全学习路线图,这里我给大家分享一份打磨了3个月,已经更新到4.0版本的网络安全学习路线图。
相比起繁琐的文字,还是生动的视频教程更加适合零基础的同学们学习,这里也是整理了一份与上述学习路线一一对应的网络安全视频教程。
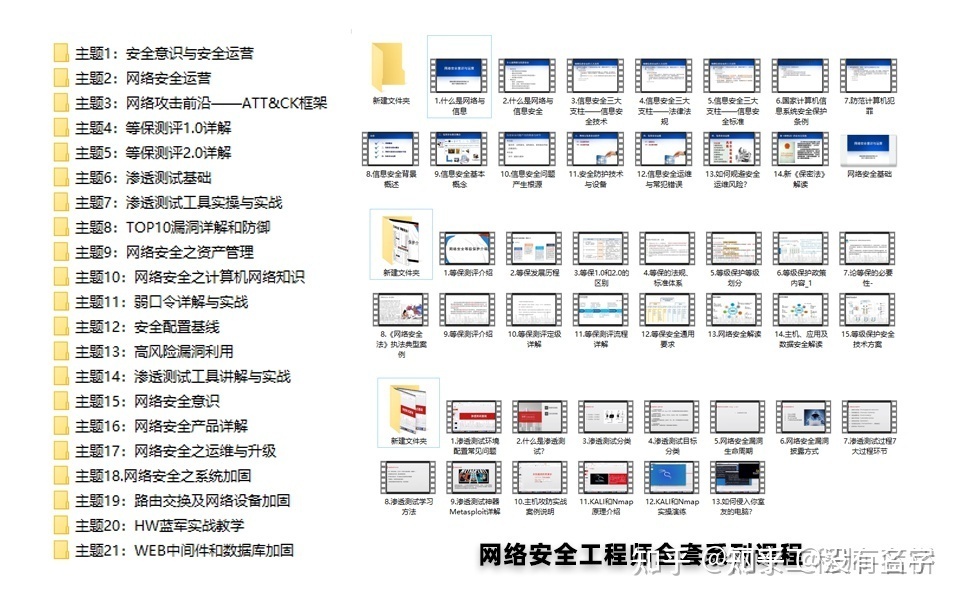
网络安全工具箱
当然,当你入门之后,仅仅是视频教程已经不能满足你的需求了,你肯定需要学习各种工具的使用以及大量的实战项目,这里也分享一份我自己整理的网络安全入门工具以及使用教程和实战。
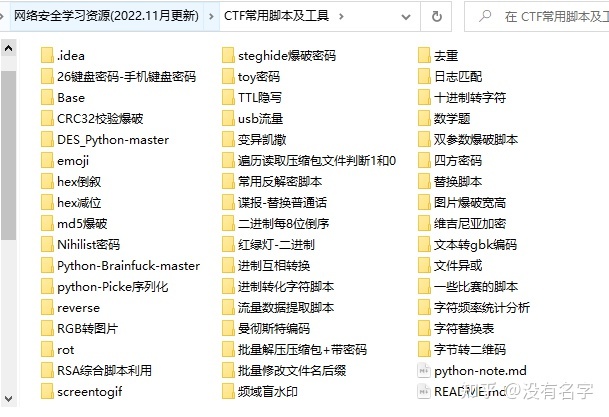
项目实战
最后就是项目实战,这里带来的是SRC资料&HW资料,毕竟实战是检验真理的唯一标准嘛~

面试题
归根结底,我们的最终目的都是为了就业,所以这份结合了多位朋友的亲身经验打磨的面试题合集你绝对不能错过!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3524
3524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









