







还有兄弟不知道网络安全面试可以提前刷题吗?费时一周整理的160+网络安全面试题,金九银十,做网络安全面试里的显眼包!
王岚嵚工程师面试题(附答案),只能帮兄弟们到这儿了!如果你能答对70%,找一个安全工作,问题不大。
对于有1-3年工作经验,想要跳槽的朋友来说,也是很好的温习资料!
【完整版领取方式在文末!!】
93道网络安全面试题
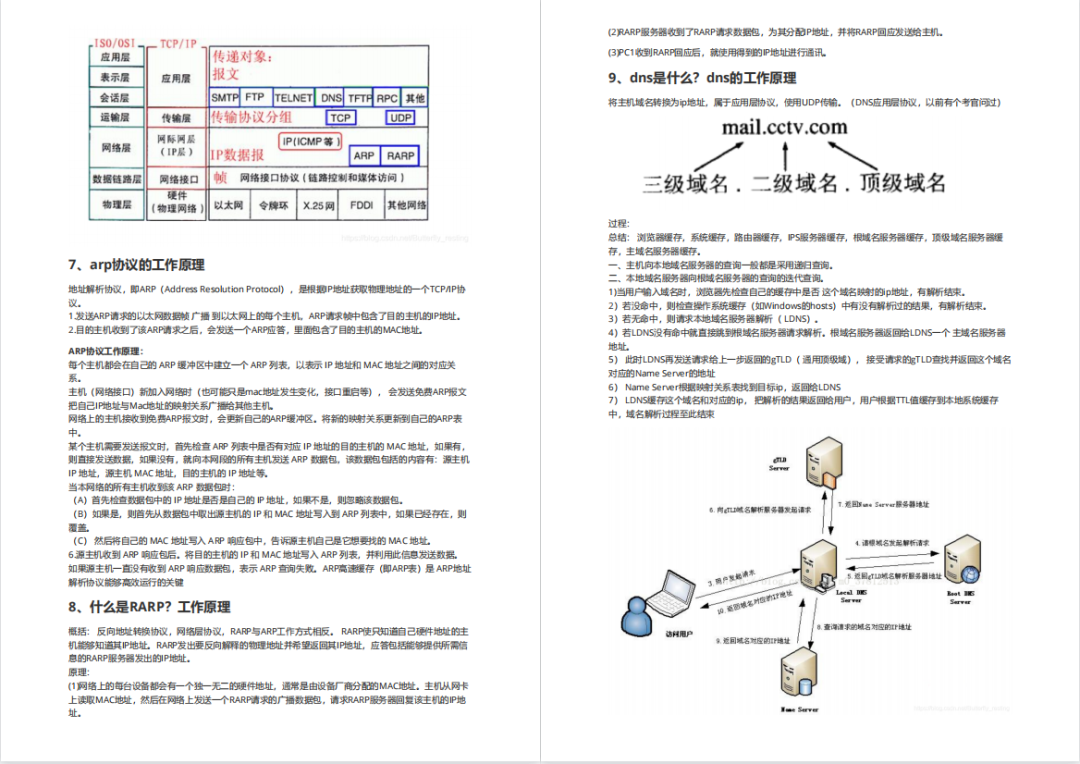


内容实在太多,不一一截图了
黑客学习资源推荐
最后给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
😝朋友们如果有需要的话,可以联系领取~
1️⃣零基础入门
① 学习路线
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
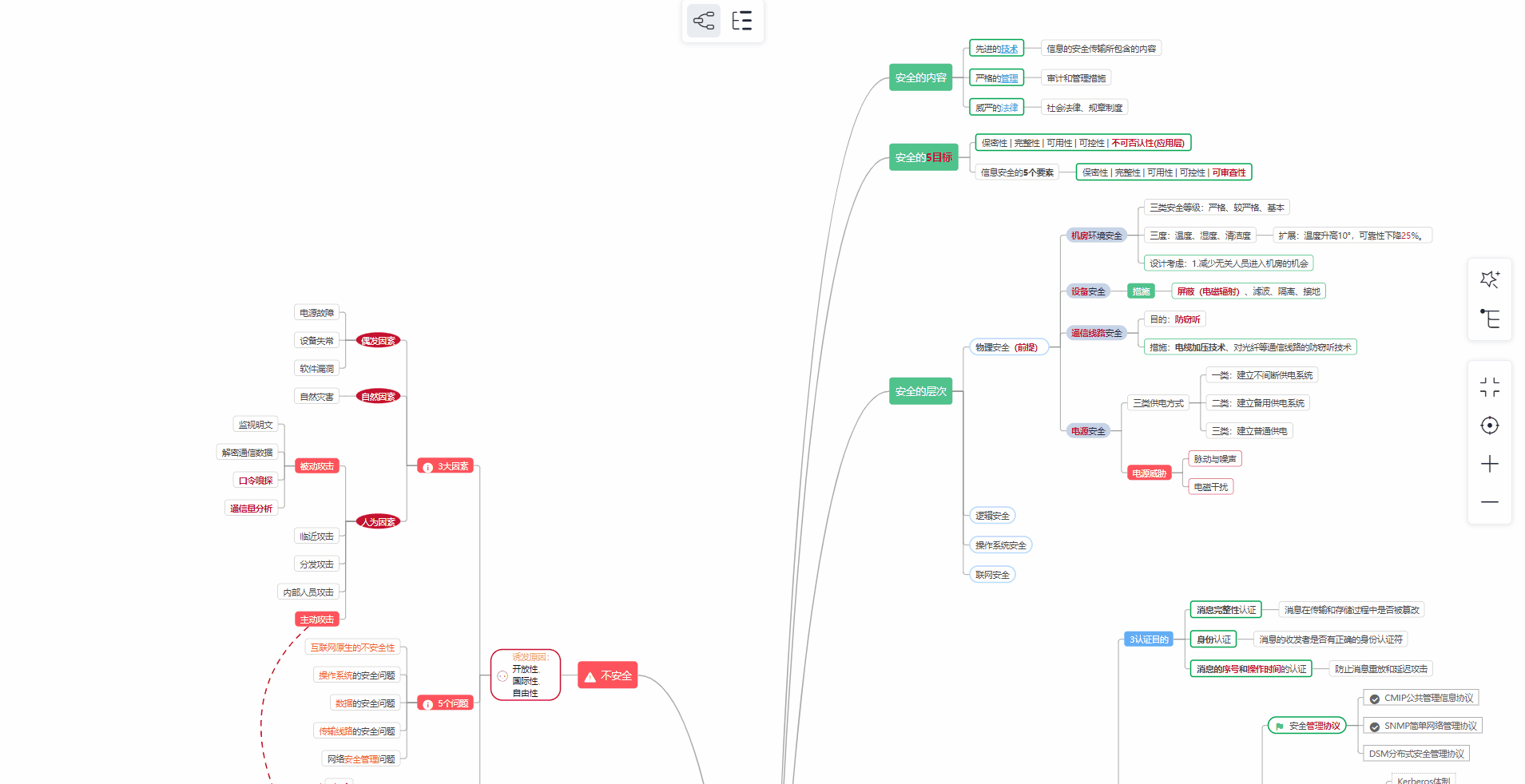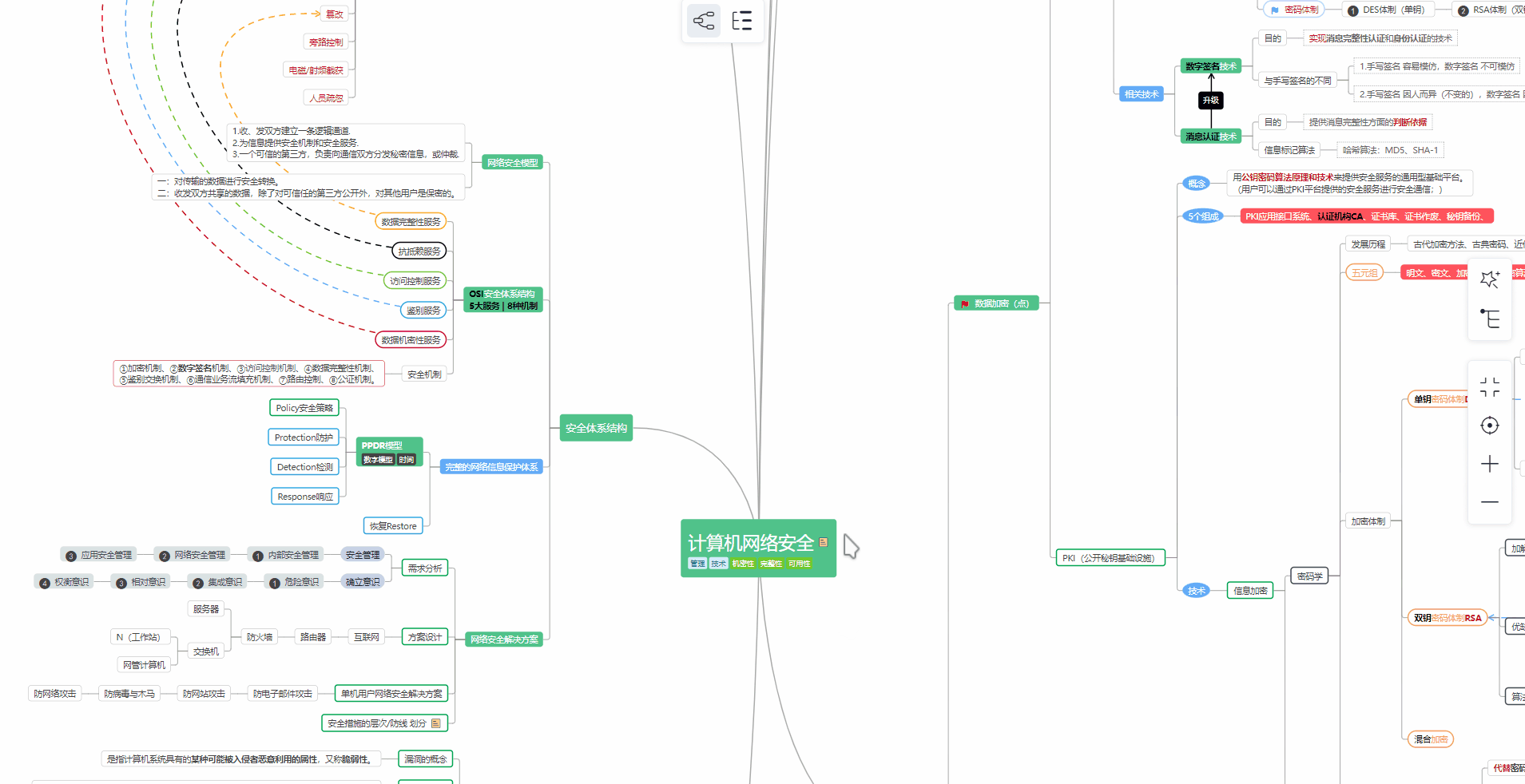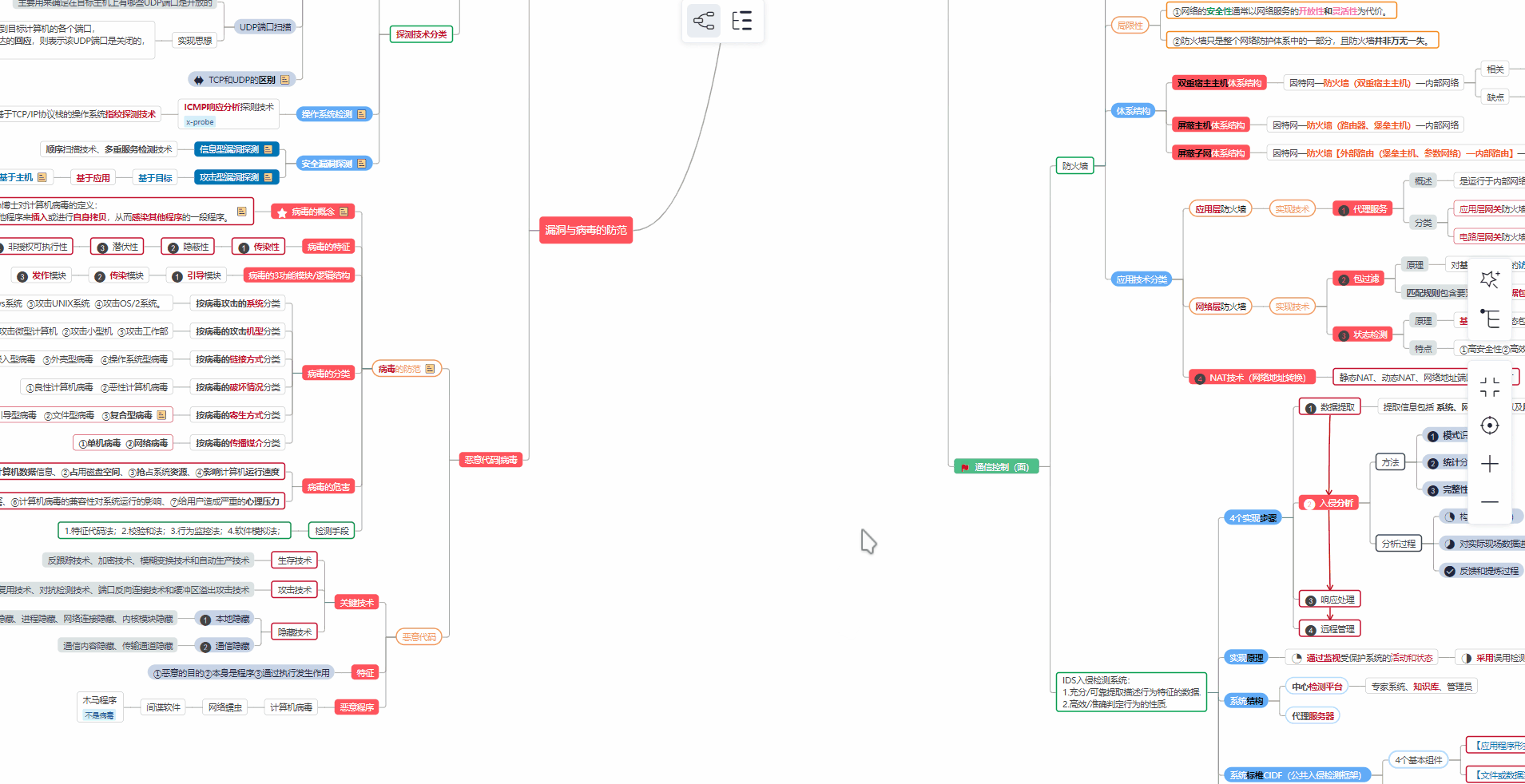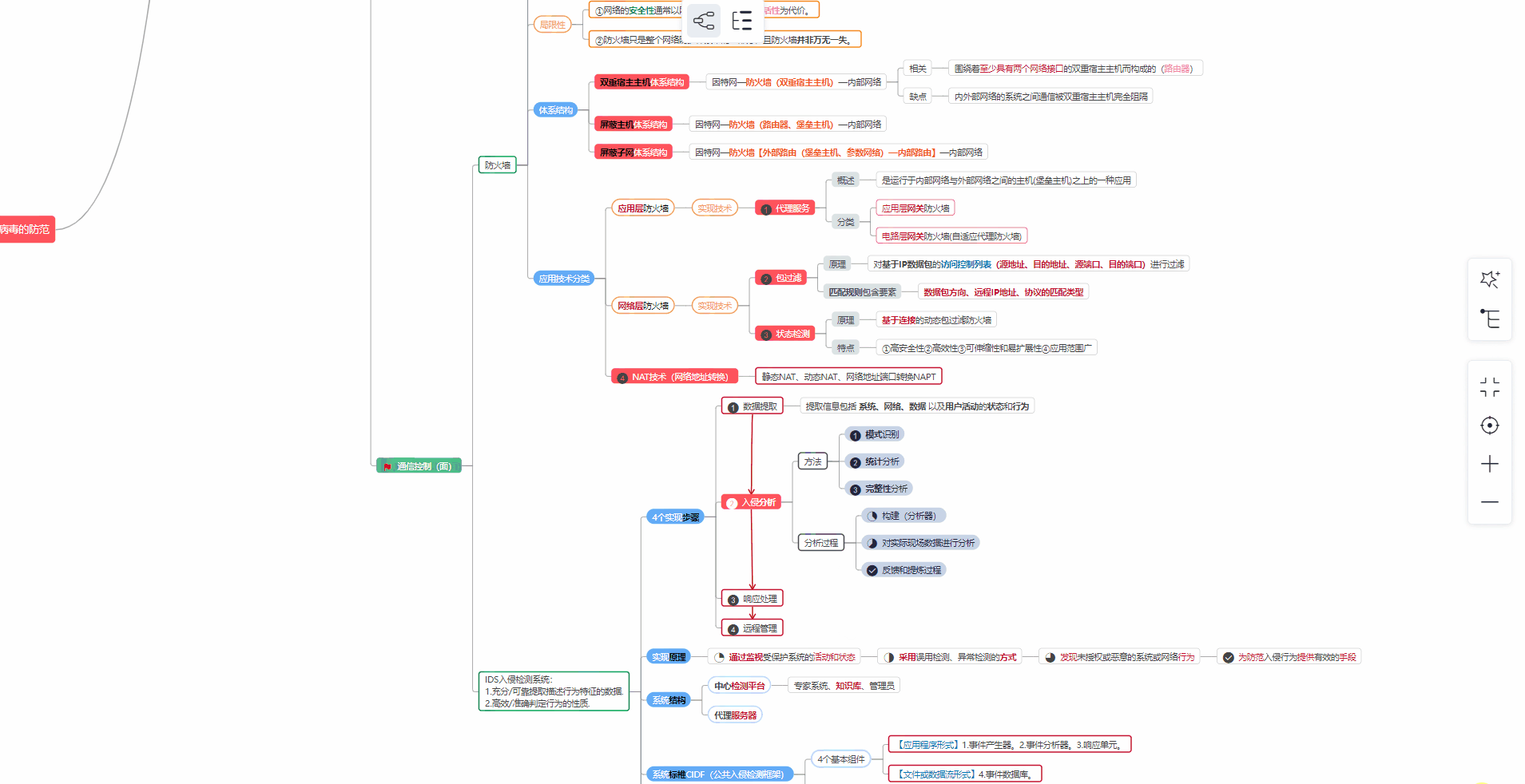
② 路线对应学习视频
同时每个成长路线对应的板块都有配套的视频提供:

2️⃣视频配套工具&国内外网安书籍、文档
① 工具

② 视频
③ 书籍
资源较为敏感,未展示全面,需要的最下面获取

② 简历模板
因篇幅有限,资料较为敏感仅展示部分资料,添加上方即可获取👆
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
LinkList:
public class LinkedList<E> extends AbstractSequentialList<E> implements
List<E>, Deque<E>, Cloneable, java.io.Serializable {}
类继承图关系:
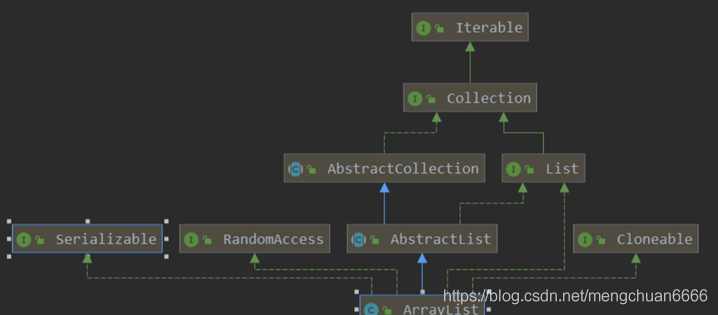
数据结构实现:ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
随机访问效率:ArrayList 比 LinkedList 在随机访问的时候效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。
增加和删除效率:在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。
综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
-
是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
-
底层数据结构: Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是 双向链表 数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
-
插入和删除是否受元素位置的影响: ① ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e) 方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element) )时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② LinkedList 采用链表存储,所以对于add( E e)方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置i插入和删除元素的话((add(int index, E element)) 时间复杂度应为o(n))因为需要新创立一个新的链表,复制前i-1个元素并在第i位加入新的元素,最后附上n-i个元素。
-
是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index) 方法)。
-
内存空间占用: ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
Q4:Set 有什么特点,有哪些实现?
Set 不允许元素重复且⽆序,常⽤实现有 HashSet、LinkedHashSet 和 TreeSet。
HashSet 通过 HashMap 实现,HashMap 的 Key 即 HashSet 存储的元素,所有 Key 都使⽤相同的Value ,⼀个名为 PRESENT 的 Object 类型常量。使⽤ Key 保证元素唯⼀性,但不保证有序性。由于HashSet 是 HashMap 实现的,因此线程不安全。
HashSet 判断元素是否相同时,对于包装类型直接按值⽐较。对于引⽤类型先⽐较 hashCode 是否相同,不同则代表不是同⼀个对象,相同则继续⽐较 equals,都相同才是同⼀个对象。
LinkedHashSet 继承⾃ HashSet,通过 LinkedHashMap 实现,使⽤双向链表维护元素插⼊顺序。
TreeSet 通过 TreeMap 实现的,添加元素到集合时按照⽐较规则将其插⼊合适的位置,保证插⼊后的集合仍然有序。

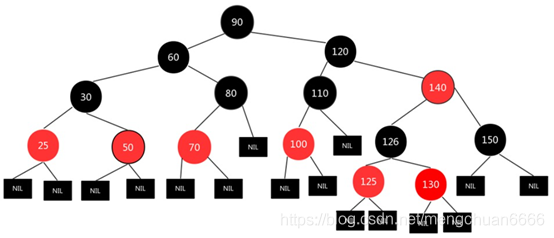
Q5:TreeMap 有什么特点?
TreeMap 基于红⿊树实现,增删改查的平均和最差时间复杂度均为 O(logn) ,最⼤特点是 Key 有序。
Key 必须实现 Comparable 接⼝或提供的 Comparator ⽐较器,所以 Key 不允许为 null。
HashMap 依靠hashCode和equals去重,⽽ TreeMap 依靠 Comparable 或 Comparator。
TreeMap 排序时,如果⽐较器不为空就会优先使⽤⽐较器的compare⽅法,否则使⽤ Key 实现的。
Comparable 的Compareto⽅法,两者都不满⾜会抛出异常。TreeMap 通过put和deleteEntry实现增加和删除树节点。插⼊新节点的规则有三个:① 需要调整的新节点总是红⾊的。② 如果插⼊新节点的⽗节点是⿊⾊的,不需要调整。③ 如果插⼊新节点的⽗节点是红⾊的,由于红⿊树不能出现相邻红⾊,进⼊循环判断,通过重新着⾊或左右旋转来调整。TreeMap 的插⼊操作就是按照 Key 的对⽐往下遍历,⼤于节点值向右查找,⼩于向左查找,先按照⼆叉查找树的特性操作,后续会重新着⾊和旋转,保持红⿊树的特性。
Q6:HashMap 有什么特点?
JDK8 之前底层实现是数组 + 链表,JDK8 改为数组 + 链表/红⿊树,节点类型从Entry 变更为 Node。主要成员变量包括存储数据的 table 数组、元素数量 size、加载因⼦ loadFactor。
table 数组记录 HashMap 的数据,每个下标对应⼀条链表,所有哈希冲突的数据都会被存放到同⼀条链表,Node/Entry 节点包含四个成员变量:key、value、next 指针和 hash 值。
HashMap 中数据以键值对的形式存在,键对应的 hash 值⽤来计算数组下标,如果两个元素 key 的hash 值⼀样,就会发⽣哈希冲突,被放到同⼀个链表上,为使查询效率尽可能⾼,键的 hash 值要尽可能分散。
HashMap 默认初始化容量为 16,扩容容量必须是 2 的幂次⽅、最⼤容量为 1<< 30 、默认加载因⼦为
0.75。
Q7:HashMap为什么线程不安全?
大家都应该知道HashMap不是线程安全的。具体存在问题的场景有:
1. 数据丢失
2. 数据重复
3. 死循环
关于死循环的问题,在Java8中个人认为是不存在了,在Java8之前的版本中之所以出现死循环是因为在resize的过程中对链表进行了倒序处理;在Java8中不再倒序处理,自然也不会出现死循环。
曾经有大神这样解释的:
通过上面Java7中的源码分析一下为什么会出现数据丢失,如果有两条线程同时执行到这条语句 table[i]=null,时两个线程都会区创建Entry,这样存入会出现数据丢失。 如果有两个线程同时发现自己都key不存在,而这两个线程的key实际是相同的,在向链表中写入的时候第一线程将e设置为了自己的Entry,而第二个线程执行到了e.next,此时拿到的是最后一个节点,依然会将自己持有是数据插入到链表中,这样就出现了数据 重复。 通过商品put源码可以发现,是先将数据写入到map中,再根据元素到个数再决定是否做resize.在resize过程中还会出现一个更为诡异都问题死循环。 这个原因主要是因为hashMap在resize过程中对链表进行了一次倒序处理。假设两个线程同时进行resize, A->B 第一线程在处理过程中比较慢,第二个线程已经完成了倒序编程了B-A 那么就出现了循环,B->A->B.这样就出现了就会出现CPU使用率飙升。 在下午突然收到其中一台机器CPU利用率不足告警,将jstack内容分析发现,可能出现了死循环和数据丢失情况,当然对于链表的操作同样存在问题。 PS:在这个过程中可以发现,之所以出现死循环,主要还是在于对于链表对倒序处理,在Java 8中,已经不在使用倒序列表,死循环问题得到了极大改善。
HashMap的线程不安全主要体现在下面两个方面:
1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
Q8:说下你对HaspMap的认识!【重点,重点】
首先大家都知道HashMap是一个集合,是<key、value>的集合,每个节点都有一个key和value,具体的参考代码:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Hashmap的数组结构为数组+(链表或者红黑树)
为什么要采用这种结构来存储元素呢?首先得分析下数组和链表的特点:
数组:查询效率高,插入,删除效率低。
链表:查询效率低,插入删除效率高。
在HashMap底层使用数组加(链表或红黑树)的结构完美的解决了数组和链表的问题,使得查询和插入,删除的效率都很高。
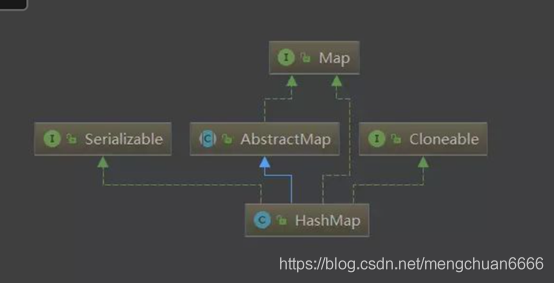
HashMap的继承图:
JDK8 之前,hash:计算元素 key 的散列值
① 处理 String 类型时,调用 stringHash32 方法获取 hash 值。
② 处理其他类型数据时,提供一个相对于 HashMap 实例唯一不变的随机值 hashSeed 作为计算初始量。
③ 执行异或和无符号右移使 hash 值更加离散,减小哈希冲突概率。
indexFor:计算元素下标
将 hash 值和数组长度-1 进行与操作,保证结果不会超过 table 数组范围。
大家可以参考下代码看下解释,然后就很明白了,我们可以简单总结出HashMap:
无序,允许为null,非同步;
底层由散列表(哈希表)实现;
初始容量和装载因子对HashMap影响挺大的,设置小了不好,设置大了也不好。
resize:扩容数组
① 如果当前容量达到了最大容量,将阈值设置为 Integer 最大值,之后扩容不再触发。
② 否则计算新的容量,将阈值设为 newCapacity x loadFactor 和 最大容量 + 1 的较小值。
③ 创建一个容量为 newCapacity 的 Entry 数组,调用 transfer 方法将旧数组的元素转移到新数组。
transfer:转移元素
① 遍历旧数组的所有元素,调用 rehash 方法判断是否需要哈希重构,如果需要就重新计算元素 key 的 hash 值。
② 调用 indexFor 方法计算元素存放的下标 i,利用头插法将旧数组的元素转移到新数组。
JDK8
hash:计算元素 key 的散列值
如果 key 为 null 返回 0,否则就将 key 的 hashCode 方法返回值高低16位异或,让尽可能多的位参与运算,让结果的 0 和 1 分布更加均匀,降低哈希冲突概率。
put:添加元素
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
我们来解析下实现的方法
① 调用 putVal 方法添加元素。
② 如果 table 为空或长度为 0 就进行扩容,否则计算元素下标位置,不存在就调用 newNode 创建一个节点。
③ 如果存在且是链表,如果首节点和待插入元素的 hash 和 key 都一样,更新节点的 value。
④ 如果首节点是 TreeNode 类型,调用 putTreeVal 方法增加一个树节点,每一次都比较插入节点和当前节点的大小,待插入节点小就往左子树查找,否则往右子树查找,找到空位后执行两个方法:balanceInsert 方法,插入节点并调整平衡、moveRootToFront 方法,由于调整平衡后根节点可能变化,需要重置根节点。
⑤ 如果都不满足,遍历链表,根据 hash 和 key 判断是否重复,决定更新 value 还是新增节点。如果遍历到了链表末尾则添加节点,如果达到建树阈值 7,还需要调用 treeifyBin 把链表重构为红黑树。
⑥ 存放元素后将 modCount 加 1,如果 ++size > threshold ,调用 resize 扩容。
get :获取元素的 value 值
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods.
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
如何自学黑客&网络安全
黑客零基础入门学习路线&规划
初级黑客
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)
恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:282G全网最全的网络安全资料包评论区留言即可领取!
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
如果你零基础入门,笔者建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习;搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime;·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完;·用Python编写漏洞的exp,然后写一个简单的网络爬虫;·PHP基本语法学习并书写一个简单的博客系统;熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选);·了解Bootstrap的布局或者CSS。
8、超级黑客
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,附上学习路线。
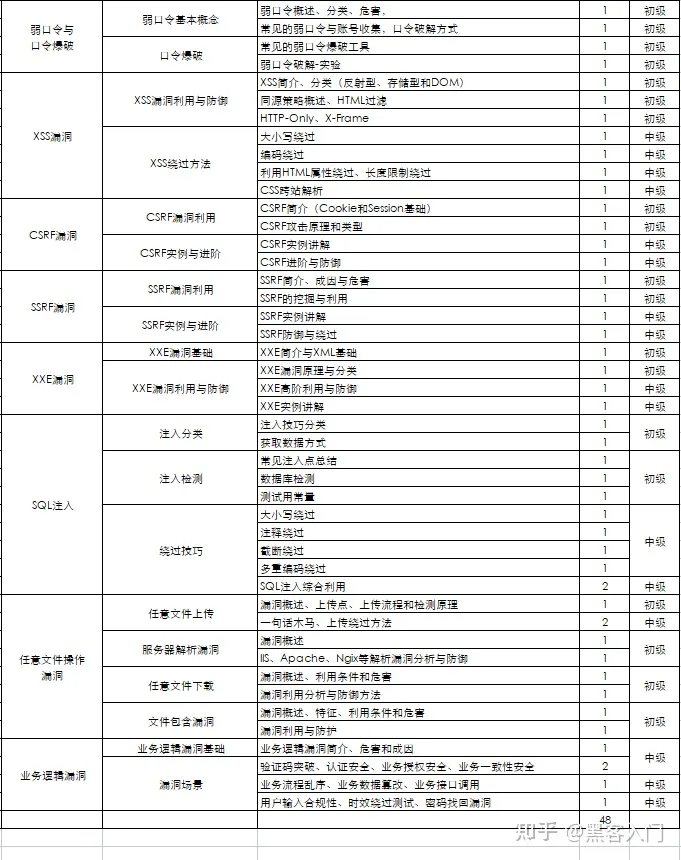
网络安全工程师企业级学习路线

如图片过大被平台压缩导致看不清的话,评论区点赞和评论区留言获取吧。我都会回复的
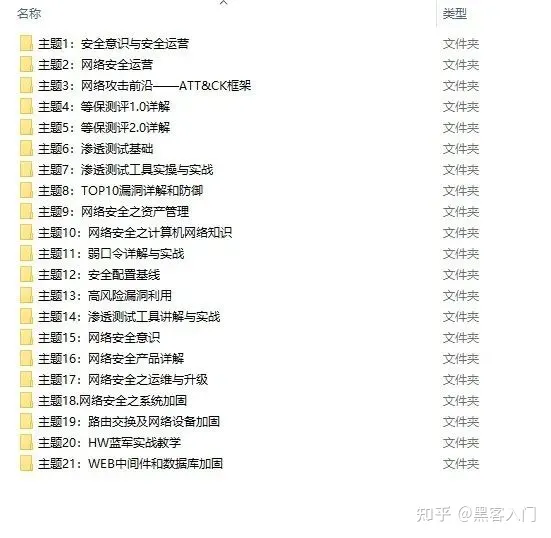
视频配套资料&国内外网安书籍、文档&工具
当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。

一些笔者自己买的、其他平台白嫖不到的视频教程。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









